Introduction
We're building CloudReactor to make it easy to deploy, manage and maintain data pipelines. With a single command, you can push tasks to your AWS environment, and then monitor, manage and orchestrate everything via a web-based dashboard.
Why are we building this?
Deploying, running and monitoring pipelines just seems to take way too much time and effort.
For example, to setup and run Airflow (I know it's the OG, please forgive me) requires a fairly steep learning curve. You have to download and install a bunch of packages, set up a server & database, learn how to use operators and DAGs etc. It's definitely powerful. We just felt that we could help free engineers from having to setup and maintain a whole other scheduling / monitoring system.
How does it work?
There's some upfront AWS config: you'll need to setup an ECS cluster in AWS to run tasks, and setup some networking + role permissions to ensure CloudReactor can manage tasks for you. We have a command-line wizard that can automate all of this. It takes ~15 mins to get everything done from scratch, and the code is available on GitHub for peace of mind that we're not doing anything nefarious.
Then the main thing: clone our QuickStart repo. This uses Docker under the hood to build and package your code into their own containers. We currently support python. Write your code in the /src/ directory of the repo. Configure the repo with your AWS keys. Issue a "deploy" command via command line, and our repo builds a docker container containing your code, pushes it up to your AWS environment, and registers it with CloudReactor.
The tasks run in your own environment. CloudReactor has permissions to stop / start / manage the container, but can't see the code or data inside.
Now if you login to the CloudReactor dashboard you'll see your code (tasks) there. From here, you can:
- schedule tasks to run on a given schedule
- manually stop / start tasks
- combine tasks into workflows (like an Airflow DAG, except via our drag & drop UI -- takes seconds)
- see the current and historical status of all tasks & workflows (running, failed, succeeded etc.)
- see metrics like # rows processed (we provide a library for sending metrics), time taken to run etc.
- set notifications (via pagerduty or email)
Combining tasks into workflows is particularly useful for running data pipelines with CloudReactor.
For example, you might write two tasks that pull data from different source systems or databases, and a third task to combine the data extracts once the first two tasks complete.
Some screenshots
Create workflows in seconds with a drag & drop editor:
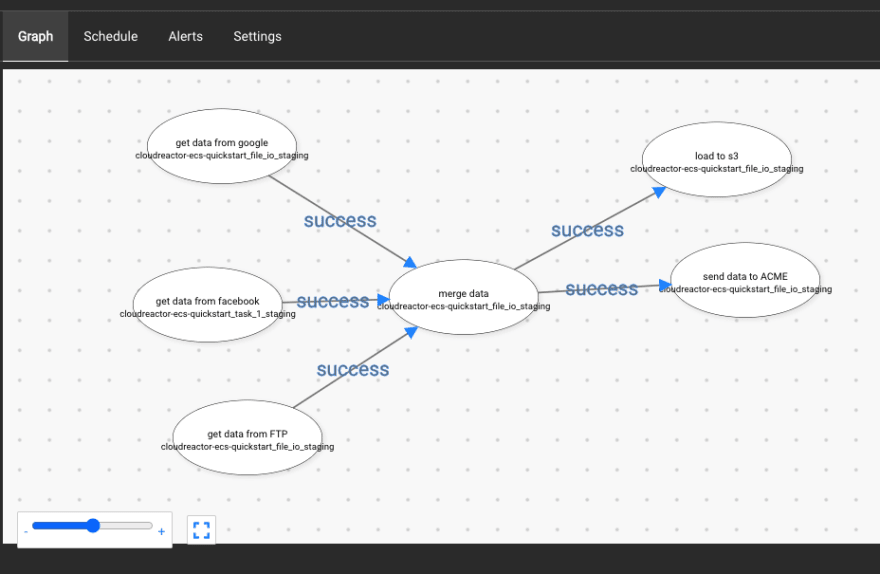
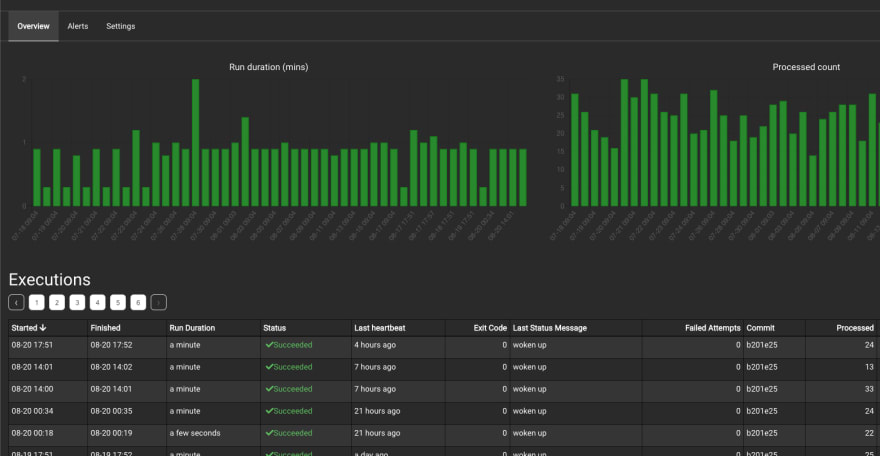
View current and historical executions:
Easily set notifications:

What does this have to do with me?
We'd love to work with you as we develop CloudReactor further!
We might be a good fit if you:
- Are running or thinking of running ETL pipelines
- Haven't heavily invested in an alternative solution (e.g. Airflow) - or are looking to migrate away (e.g. from an on-prem solution)
- Are comfortable running your pipeline in AWS, on ECS (ECS Fargate is serverless, so very cost-effective, scalable, etc.)
- Prefer to outsource the orchestration, management and monitoring side of things
If interested, feel free to sign up for a free account at https://dash.cloudreactor.io/signup. And if you want, ping me (simon at cloudreactor.io) and I'll keep a look out for you.
Thanks for your time, please let me know if any questions or comments!

Top comments (0)