
Problem
You want to extract data from Postgres and load it into Snowflake. You prefer the flexibility of code -- perhaps there are some custom operations you want to do on the data before it is loaded into Snowflake for example.
But you recognize that writing such code is only half the problem. Setting up and maintaining infrastructure to run, monitor and orchestrate a code-based data pipeline can be a huge time sink and distraction.
This is where CloudReactor helps.
CloudReactor makes deployment, monitoring and management easy.
CloudReactor’s “deploy” command packages your program into tasks backed by Docker images, and deploys them to your AWS ECS environment. You can then use the CloudReactor dashboard to monitor, manage and orchestrate these tasks. For example, simply hit “start” in the CloudReactor dashboard, or configure a cron schedule, and your task automatically starts running on AWS ECS Fargate. You can view all historical executions and their status too.
In a nutshell, you get the development & isolation benefits of Docker, plus easy deployment to AWS ECS, monitoring, alerting and workflow authoring thanks to CloudReactor.
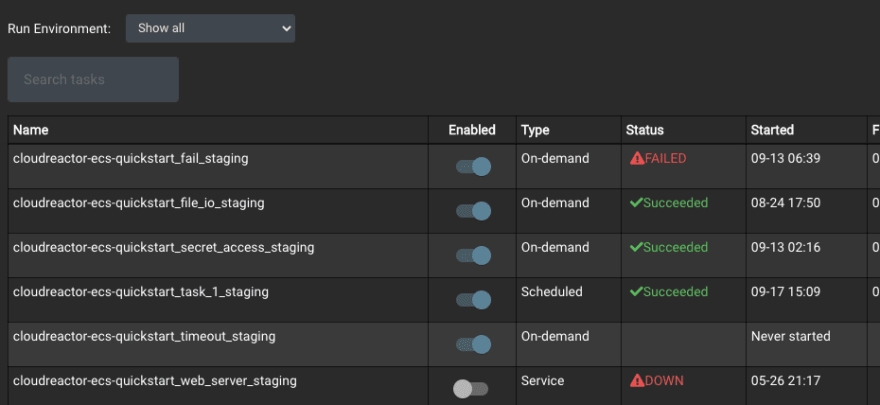
See the current status of all tasks
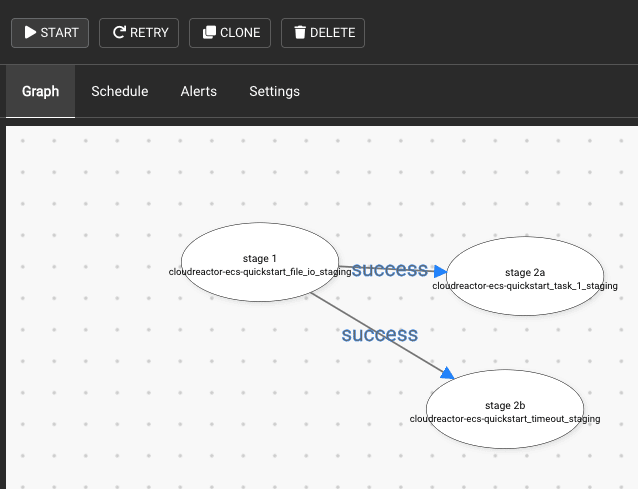
Easily link tasks into workflows via a drag & drop editor
Running tasks on ECS Fargate is often cost-effective because you only pay for resources you use, and saves your team time because there’s no server maintenance to worry about.
What you’ll get out of this guide
After following this guide, you’ll have a task that will extract data from a Postgres table and load it into Snowflake. The task keeps track of the most recent data loaded, and will only fetch new / updated records each time it runs. The script as-is doesn’t pick up deleted records however (i.e. assumes the source table is append-only).
The task is deployed and run on an ECS cluster in your own AWS environment, and uses AWS Secrets Manager for runtime secrets. You can login to your CloudReactor account to stop, start and schedule this task; to set alerts; and to build workflows (connect this task with other tasks).
While we believe using CloudReactor to manage and monitor tasks is a great choice, you can also use the core python_to_snowflake.py script independent of CloudReactor. Scripts deployed with CloudReactor are just normal code. Feel free to check out the script itself here.
Let’s get started!
We’ll first run the script locally to confirm everything works, and then configure & deploy to AWS via CloudReactor.
Local deployment
1. Fork the CloudReactor repo:
Fork & clone the CloudReactor postgres_to_snowflake repo. This repo includes the postgres_to_snowflake.py script, all required dependencies, and tools that enable the task to be built into a docker container and deployed to AWS.
git clone https://github.com/<username>/postgres_to_snowflake.git
2. Configure repo
Modify the following files:
-
/src/postgres_to_snowflake.py. This is the script / task that fetches data from Postgres and loads it to Snowflake. You will want to modify the “key variables” section at the top of the page. The source table should be a PostgreSQL table with a primary key (e.g. ID) column, and last_updated column. These columns are used to determine which records are new or have changed. When the task runs, only new or changed records are fetched from Postgres. These are compressed in the ECS container’s local storage, uploaded to an internal Snowflake named stage, and finally loaded into Snowflake. Obviously, feel free to modify the script as necessary for your specific situation./deploy/files/.env.dev: Add your Postgres and Snowflake credentials. These are used when the script is run locally. Note that the credentials are stored in a json-like object, one object per resource. This mimics the secrets object that we’ll create in AWS Secrets Manager shortly to store credentials, and allows us to use the same code to extract secrets independent of the environment. Note that .env.dev is in .gitignore by default; you can remove it from .gitignore and use git-encrypt to encrypt the checked-in file if you want. -
/docker-compose.yml: Nothing to change here. Just for reference, this has a “postgres_to_snowflake” block under “services”. This allows us to run the task locally by runningdocker-compose run --rm postgres_to_snowflake:
postgres_to_snowflake:
<<: *service-base
command: python src/postgres_to_snowflake.py
3. Run script locally
docker-compose run --rm postgres_to_snowflake
Of course, you need to ensure connectivity from your local machine to source and destination databases. This might involve a VPN for example.
If the script succeeds 🥳 🎉, you should be able to login to your snowflake dashboard and query the relevant destination table. Awesome!
AWS deployment with CloudReactor monitoring
Next, we'll configure the repo for deployment to AWS, and monitoring & management in CloudReactor.
1. Create a CloudReactor account and get API key
Sign up for a free CloudReactor account. Once created, you can login to view your CloudReactor API key.
2. Set up AWS infrastructure, link to CloudReactor
To run tasks in AWS via CloudReactor, you’ll need:
- An ECS cluster. The cluster must have access to the internet to communicate with CloudReactor and to connect to external resources such as Snowflake. A common configuration is to create an ECS cluster in a private subnet, and to connect that private subnet to a public subnet via a NAT gateway.
- To import information about the cluster, subnets, security groups and other settings into a CloudReactor “Run Environment”. A Run Environment is a collection of settings that tell CloudReactor how to deploy and manage tasks in your environment.
There are two ways to create this infrastructure and link it to CloudReactor.
- I want to do it the easy way: we created an open-source AWS Setup Wizard that can create an ECS cluster and a VPC with public and private subnets in your AWS environment. Alternatively, if you already have a VPC and/or cluster, you can instruct the Setup Wizard to use these instead. Finally, the wizard will import settings regarding your chosen ECS cluster, VPC, security groups etc. into a “Run Environment” in CloudReactor.
Note that the Wizard uploads a CloudFormation stack to create resources. These changes can therefore be reversed easily.

Clone this repo, build the docker image and run the wizard:
git clone https://github.com/CloudReactor/cloudreactor-aws-setup-wizard.git
cd cloudreactor-aws-setup-wizard
./build.sh
./wizard.sh (or .\wizard.bat if using Windows)
During the wizard, you’ll be asked what subnets & security groups to run tasks in.
- If your Postgres instance is hosted on AWS RDS, you’ll want to select the same VPC & subnets as your RDS instance is in.
- If you select a different security group from your RDS instance for your tasks to run in, you’ll need to edit your RDS instance security group to allow traffic from your task security group. To do this, see the AWS guide on editing security group rules.
For further information on how to use the wizard, see https://docs.cloudreactor.io/#set-up-aws-infrastructure-link-to-cloudreactor. After running the AWS Setup Wizard, you can return to this guide.
- I want to do it the manual way: if you prefer to setup your ECS cluster and networking manually, follow the CloudReactor & ECS cluster manual setup guide. You may also want to review the networking guide. Note that you can set up your ECS cluster and networking manually, and then use our AWS Setup Wizard to import those settings into CloudReactor. Or, you can do everything manually.
Whether you use the AWS Setup Wizard or do things manually, you’ll end up with:
- An ECS cluster, VPC and subnets
- A role template installed in your AWS environment that allows CloudReactor to start, stop and schedule tasks (see https://github.com/CloudReactor/aws-role-template for the template itself)
- A named “Run Environment” in CloudReactor. You may have named this “prod” or “staging” for example. Keep this name in mind -- we’ll need it shortly!
3. Preparing runtime secrets via AWS Secrets Manager
We’ll use AWS Secrets Manager to store runtime secrets. For this guide, we’ll create 3 secrets objects: one each to store your CloudReactor API key, PostgreSQL and Snowflake credentials. (If you don’t want to use AWS Secrets Manager, see https://docs.cloudreactor.io/secrets.html for an overview of some other options)
In the AWS Secrets Manager dashboard, click “Store a new secret”.
- We’ll start with the CloudReactor API key. For “Secret Type”, select “Other type of secrets” and “plaintext”. Paste in your CloudReactor API key as the entire field (i.e. no need for newline, braces, quotes etc.). On the next page, for “secret name”, type
CloudReactor/<env_name>/common/cloudreactor_api_key. Replace<env_name>with whatever your CloudReactor Run Environment is called -- this was created during the AWS Setup Wizard. You can also check the name of the Run Environment by logging into the CloudReactor dashboard and selecting “Run Environments”. - Note that the
CloudReactor/<env_name>/common/prefix is important: tasks deployed with CloudReactor are by default able to read secrets contained in this specific path (but not other paths). You can of course modify the permissions policy to enable access to other paths. - Next, we can create a secret object to store Postgres credentials. Click “store a new secret” again. If your Postgres instance is hosted on RDS, you can select “RDS” and your database, and AWS will pre-fill the hostname, port, etc. for you. After creating the secret, you’ll need to edit it and add another key manually, “dbname”. If your Postgres instance isn’t hosted on RDS, choose “other type of secrets”. This allows you to store a number of user-defined environment variables in a single JSON-like secrets object. Add the following keys & their associated values: dbname, username, password, host, port. Either way, for the name to save the secret as, enter
CloudReactor/<env_name>/common/postgres. Again,env_nameis the CloudReactor “Run Environment” mentioned just above. You can choose a different name topostgresif you want. - Finally, create a secret object for Snowflake secrets. Here, the object should have three keys: user, password, account. Similarly, name the secret with a prefix starting with
CloudReactor/<env_name>/common/, e.g.CloudReactor/<env_name>/common/snowflake. - Once these objects have been created, you can click each of them in the Secrets Manager dashboard and view their ARN. It should look something like this:
arn:aws:secretsmanager:<region>:<account_id>:secret:CloudReactor/<env_name>/common/<name>-xxxxx.
4. Configure repo for AWS deployment
Modify the following files:
-
/deploy/docker_deploy.env.example: copy this todocker_deploy.env. Add your AWS key, secret access key, and AWS ECS cluster region. This allows you to use the./docker_deploycommand in the next step to deploy tasks directly from your local machine to AWS. -
/deploy/vars/[env_name].yml: copy and renameexample.ymlto match the name of your CloudReactor Run Environment (e.g. prod, staging). Open the file. Fill in your CloudReactor API key next toapi_key. Next, further down that same file, you’ll see the following block:
- name: PROC_WRAPPER_API_KEY
valueFrom: "arn:aws:secretsmanager:[aws_region]:[aws_account_id]:secret:CloudReactor/example/common/cloudreactor_api_key-xxx"
- name: POSTGRES_SECRETS
valueFrom: ...
...
Fill in the valueFrom: with the actual secrets ARNs from AWS Secrets Manager (note: PROC_WRAPPER_API_KEY = CloudReactor API secret).
Note the following block further down that file:
postgres_to_snowflake:
<<: *default_env_task_config
Nothing to modify here. This block allows the postgres_to_snowflake task to read the secrets we just defined above.
5. Deploy!
Deploy to ECS:
./docker_deploy.sh [env_name] postgres_to_snowflake
Where again, [env_name] is the name of your CloudReactor Run Environment (and the .yml file created just above with your CloudReactor API key), e.g. prod, staging.
6. Log in to CloudReactor and stop, start, schedule and monitor your task!
Log into the CloudReactor dashboard at dash.cloudreactor.io.
You’ll see an entry for the postgres_to_snowflake task:

To run it now, simply hit the start button. You can monitor its status from the dashboard, and see a list of historical executions by clicking on the task name.
Click the gear icon to set a cron schedule. You can also setup success / failure alerts via email or PagerDuty.
Finally, if you deploy other tasks using CloudReactor, you can click “workflows” and link tasks together (e.g. “immediately after this tasks succeeds, start some related downstream task”).
Conclusion & Next Steps
CloudReactor aims to simplify data engineers' lives, by making it really easy to deploy, run, monitor and manage tasks in the cloud.
In this guide, we deployed a task that fetched data from a Postgres source, and loaded it into Snowflake. The task runs in your own AWS environment, but can be managed easily in CloudReactor.
Next, you may want to deploy other tasks using CloudReactor - read our guide here. Once deployed, you can link these tasks together into a workflow.
We welcome your feedback! Feel free to contact me at simon@cloudreactor.io

Top comments (0)