This article was originally written by Julie Kent on the Honeybadger Developer Blog.
In this post, we will learn the basics of neural networks and how we can implement them utilizing Ruby! If you're intrigued by artificial intelligence and deep learning but are unsure how to get started, this post is for you! We'll walk through a simple example to highlight the key concepts. It's pretty unlikely that you'd ever use Ruby to write multiple-layer neural networks, but for simplicity and readability, it's a great way to understand what's going on. First, let's take a step back and look at how we got here.

A still from the movie Ex Machnia. Photo credit
Ex Machina was a movie released in 2014. If you look the title up on Google, it classifies the genre of the film as "Drama/Fantasy." And, when I first watched the film, it did seem like science fiction.
But, for much much longer?
If you ask Ray Kurzweil, a well-known futurist who works at Google, 2029 could be the year artificial intelligence will pass a valid Turing test (which is an experiment to see whether a human can distinguish between a machine/computer and another human.) He also predicts that singularity (when computers surpass human intelligence) will emerge by 2045.
What makes Kurzweil so confident?
The emergence of deep learning
Put simply, deep learning is a subset of machine learning that utilizes neural networks to extract insights from large amounts of data. Real-world applications of deep learning include the following:
- Self-driving cars
- Cancer detection
- Virtual assistants, such as Siri and Alexa
- Predicting extreme weather events, such as earthquakes
But, what is a "neural network?"
Neural networks get their name from neurons, which are brain cells that process and transmit information through electrical and chemical signals. Fun fact: the human brain is made up of 80+ billion neurons!
In computing, a neural network looks like this:
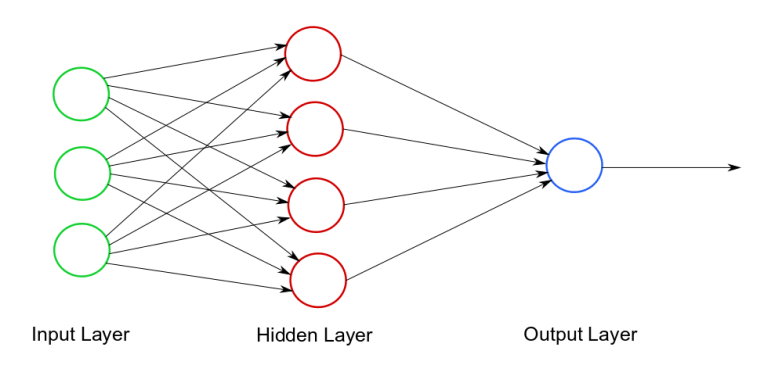
An example neural network diagram. Photo credit
As you can see, there are three parts:
1) The input layer -- The initial data
2) Hidden layer(s) -- A neural network can have 1 (or more) hidden layers. This is where all of the computation is done!
3) Output layer -- The end result/prediction
A quick history lesson
Neural networks aren't new. In fact, the first trainable neural network (the Perceptron) was developed at Cornell University in the 1950s. However, there was a lot of pessimism surrounding the applicability of neural networks, mainly because the original model only consisted of one hidden layer. A book published in 1969 showed that utilizing Perceptron for fairly simple computations would be impractical.
The resurgence of neural networks can be attributed to computer games, which now require extremely high powered graphics processing units (GPUs), whose architecture closely resembles that of a neural net. The difference is the number of hidden layers. Instead of one, neural networks trained today are using 10, 15, or even 50+ layers!
Example time!
To understand how this works, let's look at an example. You will need to install the ruby-fann gem. Open up your terminal and move to your working directory. Then, run the following:
gem install ruby-fann
Create a new Ruby file (I named mine neural-net.rb).
Next, we will utilize the "Student Alcohol Consumption" dataset from Kaggle. You can download it here. Open up the "student-mat.csv" file in Google Sheets (or your editor of choice.) Delete all of the columns except for these:
- Dalc (Workday alcohol consumption where 1 is very low and 5 is very high)
- Walc (Weekend alcohol consumption where 1 is very low and 5 is very high)
- G3 (Final grade between 0 and 20)
We need to change our final grade column to be binary -- either a 0 or 1 -- for the ruby-fann gem to work. For this example, we will assume that anything less than or equal to 10 is a "0" and greater than 10 is a "1". Depending on what program you're using, you should be able to write a formula in the cell to automatically change the value to either 1 or 0 based on the cell's value. In Google Sheets, it looks something like this:
=IF(C3 >= 10, 1, 0)
Save this data as a .CSV file (I named mine students.csv) in the same directory as your Ruby file.
Our neural network will have the following layers:
- Input Layer: 2 nodes (workday alcohol consumption and weekend alcohol consumption)
- Hidden Layer: 6 hidden nodes (this is somewhat arbitrary to start; you can modify this later as you test)
- Output Layer: 1 node (either a 0 or 1)
First, we will need to require the ruby-fann gem, as well as the built-in csv library. Add this to the first line in your Ruby program:
'require 'ruby-fann' require 'csv'
Next, we need to load our data from our CSV file into arrays.
# Create two empty arrays. One will hold our independent varaibles (x_data), and the other will hold our dependent variable (y_data).
x_data = []
y_data = []
# Iterate through our CSV data and add elements to applicable arrays.
# Note that if we don't add the .to_f and .to_i, our arrays would have strings, and the ruby-fann library would not be happy.
CSV.foreach("students.csv", headers: false) do |row|
x_data.push([row[0].to_f, row[1].to_f])
y_data.push(row[2].to_i)
end
Next, we need to divide our data into training and testing data. A 80/20 split is pretty common, where 20% of your data is used for testing and 80% for training. "Training," here, means that the model will learn based on this data, and then we will use our "testing" data to see how well the model predicts outcomes.
# Divide data into a training set and test set.
testing_percentage = 20.0
# Take the number of total elements and multiply by the test percentage.
testing_size = x_data.size * (testing_percentage/100.to_f)
# Start at the beginning and end at the testing_size - 1 since arrays are 0-indexed.
x_test_data = x_data[0 .. (testing_size-1)]
y_test_data = y_data[0 .. (testing_size-1)]
# Pick up where we left off until the end of the dataset.
x_train_data = x_data[testing_size .. x_data.size]
y_train_data = y_data[testing_size .. y_data.size]
Cool! We have our data ready to go. Next comes the magic!
# Set up the training data model.
train = RubyFann::TrainData.new(:inputs=> x_train_data, :desired_outputs=>y_train_data)
We use the RubyFann::TrainData object, and pass in our x_train_data, which is our workday and weekend alcohol consumption, and our y_train_data, which is 0 or 1 based on the final course grade.
Now, let's setup our actual neural network model with the number of hidden neurons we discussed earlier.
# Set up the model and train using training data.
model = RubyFann::Standard.new(
num_inputs: 2,
hidden_neurons: [6],
num_outputs: 1 );
OK, time to train!
model.train_on_data(train, 1000, 10, 0.01)
Here, we pass in the train variable we created earlier. The 1000 represents the number of max_epochs, the 10 represents the number of errors between reports, and the 0.1 is our desired mean-squared error. One epoch is when the entire dataset is passed through the neural network. Mean-squared error is what we are trying to minimize. You can read more about what this means here.
Next, we want to know how well our model did by comparing what the model predicted for our test data with the actual results. We can accomplish this by utilizing this code:
predicted = []
# Iterate over our x_test_data, run our model on each one, and add it to our predicted array.
x_test_data.each do |params|
predicted.push( model.run(params).map{ |e| e.round } )
end
# Compare the predicted results with the actual results.
correct = predicted.collect.with_index { |e,i| (e == y_test_data[i]) ? 1 : 0 }.inject{ |sum,e| sum+e }
# Print out the accuracy rate.
puts "Accuracy: #{((correct.to_f / testing_size) * 100).round(2)}% - test set of size #{testing_percentage}%"
Let's run our program and see what happens!
ruby neural-net.rb
You should see a lot of output for the Epochs, but at the bottom, you should see something like this:
Accuracy: 56.82% - test set of size 20.0%
Oof, that is not very good! But, let's come up with our own data points and run the model.
prediction = model.run( [1, 1] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction.map{ |e| e.round }}"
prediction_two = model.run( [5, 4] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction_two.map{ |e| e.round }}"
Here, we have two examples. For the first, we're passing in 1s for our weekday and weekend alcohol consumption. If I were a betting person, I would guess that this student would have a final grade above 10 (i.e., a 1). The second example passes in high values (5 and 4) for alcohol consumption, so I would guess that this student would have a final grade equal to or below 10 (i.e., a 0.) Let's run our program again and see what happens!
Your output should look something like this:
Algorithm predicted class: [1]
Algorithm predicted class: [0]
Our model appears to do what we'd expect for the numbers on either the lower or higher end of the spectrum. But, it struggles when numbers are opposites (feel free to try out different combinations -- 1 and 5, or 2 and 3 as examples) or in the middle. We can also see from our Epoch data that, while the error does decrease, it remains very high (mid-20%.) What this means is there may not be a relationship between alcohol consumption and course grades. I encourage you to play around with the original dataset from Kaggle -- are there other independent variables that we could use to predict course outcomes?
Wrap-Up
There are a lot of intricacies (mostly with regards to the math) that happen under the hood to make all this work. If you're curious and want to learn more, I highly recommend looking through the docs on FANN or looking at the source code for the ruby-fann gem. I also recommend checking out the "AlphaGo" documentary on Netflix -- it doesn't require a lot of technical knowledge to enjoy it and gives a great, real-life example of how deep learning is pushing the limits of what computers can accomplish.
Will Kurzweil end up being correct with his prediction? Only time will tell!





Top comments (0)