
Have you ever wondered how flexible Hasura makes querying selective data on the frontend? What if you get that level of flexibility in the database connection selection process? Isn’t it amazing to serve data with different database connections or even different databases for different types of requests? Wouldn’t that be opening up a lot of possibilities?
With read replicas, Elastic connection pooling, and the auto-scaling capabilities of Hasura, you can achieve more balanced database queries and a more reliable system. One thing that was missing, however, is the ability to route these requests dynamically to different databases or database connections based on the request context.
Well! We are excited to announce a new feature – Hasura Dynamic Routing for data sources!
This feature is designed to incorporate different database topologies in Hasura and use them effectively. This new feature helps with many use cases including having multiple (database) users, using a per-database, multi-tenant model and advanced routing logic.
If you have data distributed/replicated over different databases, or planning to improve performance of your data layer by introducing different database topologies, or if your use-case requires different queries to use database user credentials dynamically – you will find this blog useful.
What is Hasura Dynamic Routing?
With Dynamic Routing, you can define multiple database connection configurations (connection sets) and routing logic (connection template), and when a GraphQL query hits Hasura, Hasura checks the routing logic and chooses the correct database connection configuration to execute the database query. Dynamic Routing ensures that databases are used efficiently, which delivers better performance and helps reduce infrastructure cost.
Let's look at some of the basic examples that I feel will help you understand the feature in a better way. (Of course, you can do a lot more with this!)
Connect with different database connection configurations
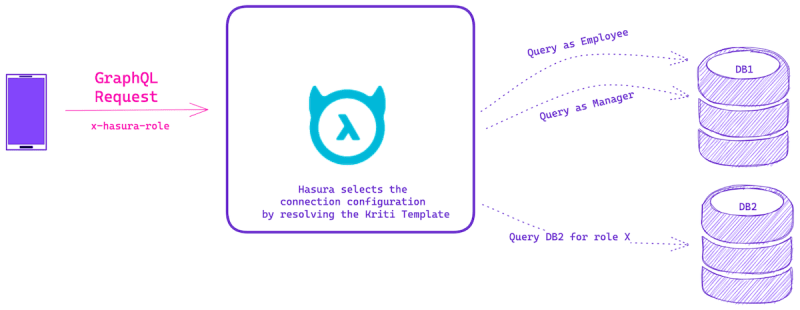
If you are integrating with an IAM vendor or wish to use database RLS, then you’ll want to use different connection credentials per request. For example, in Hasura you may use a session-variable like x-hasura-role to use a specific connection string for that role.
The connection template for the same would be:
{{ if ($.request.session.x-hasura-role == "manager")}}
{{$.connection_set.manager_connection}}
{{ elif ($.request.session.x-hasura-role == "employee")}}
{{$.connection_set.employee_connection}}
{{ elif ($.request.session.x-hasura-role == "X")}}
{{$.connection_set.DB2}}
{{ else }}
{{$.default}}
{{ end }}
Note: $.connection_set used above is explained later in this document.
No stale reads when read replicas are configured

Currently, if read replicas are configured, all query operations are routed to the read replicas, which sometimes leads to stale reads due to replication lag. You can force certain query operations to the primary connection by using some operation context variable like operation name or a special request header.
The connection template for the same would be:
{{ if (($.request.query.operation_type == "query")
|| ($.request.query.operation_type == "subscription"))
&& ($.request.headers.x-query-read-no-stale == "true") }}
{{$.primary}}
{{ else }}
{{$.default}}
{{ end }}
The above example will route the read queries to the primary database when x-query-read-no-stale header is passed. Even if a read replica is configured, this query hits the primary DB with the above routing logic.
Route to a specific shard or node-group in a distributed database

You can now route the queries to a specific node in a distributed database system like Yugabyte/CockroachDB by specifying different nodes as connection sets. And then, define the routing logic by defining a Kriti template based on your business logic.
The connection template for the same would be:
{{ if ($.request.session.x-hasura-tenant-id == "my_tenant_1")}}
{{$.connection_set.my_tenant_1_connection}}
{{ elif ($.request.session.x-hasura-tenant-id == "my_tenant_2")}}
{{$.connection_set.my_tenant_2_connection}}
{{ else }}
{{$.default}}
{{ end }}
A sample logic can be something like Route database query to Node A if the GraphQL request contains session variable “x-hasura-tenant-id” is equals to “tenant_1”
Enhanced security benefits of using Dynamic Routing
Dynamic database connection routing in Hasura provides enhanced security for your applications by allowing you to control access to your databases on a per-request basis.
By configuring connection sets and connection templates, you can route requests to specific databases or connections based on session variables or headers, which helps in isolating data and providing role-based access control. Let’s walk through some of the key security benefits.
Fine-grained access control
Dynamic connection routing allows you to route requests based on user roles, enabling you to implement role-based access control at the database connection level. This ensures that users can only access the databases and connections they are authorized to use, reducing the risk of unauthorized access.
Isolation of sensitive data
By routing requests to specific databases or connections, you can isolate sensitive data in separate databases, and ensure that only authorized users can access it.
Integration with third-party IAM solutions
Dynamic connection routing can be integrated with third-party identity and access management (IAM) solutions, providing additional security for your databases.
How does Dynamic Routing work?
You can now provide a connection template to the source configuration which will be resolved during runtime for any non-admin graphql query and the query will be executed against the resolved connection. A "resolved connection" can be any one of:
- A reference to existing primary connection (connection_info) or read-replicas
- A connection set member (a connection configuration that can be added to a datasource and can be used in template as
$.connection_set.<connection_set_name>) - A direction to fallback to current behavior
The "connection set" is a list of connections predefined in the metadata so that:
- it's easy to refer to it in the template and
- additional properties like connection pool settings can also be supplied
Note: The "primary" connection url (connection_info) is still required with a source configuration to run system queries like catalog introspection, metadata queries, event triggers, etc.
Overall, the GraphQL request resolution would look like the following:

As mentioned above, Dynamic Routing will now decide which database connection configuration needs to be used to resolve that particular GraphQL query instead of using the primary configuration.
Conclusion
Dynamic Routing for databases helps you to implement more complex database topologies, such as multi-tenancy models, without sacrificing performance or introducing another infrastructure to handle the database query routing. With this, you can use a per-database multi-tenant model with minimal metadata management. This can lead to cost savings and increased efficiency, as well as a delightful user experience for your customers.
More technical details on the Dynamic Routing lives here. We are actively looking for more use cases and how this feature helps your organization to scale, so reach out to us in our Discord channel if you find it helpful or if you have any questions around this.
Sign up now for Hasura Cloud to try this feature!

Top comments (0)