
Hasura gives you instant GraphQL and REST APIs for all your data. Typically you would connect a database to Hasura and get these APIs. But what if you already have existing GraphQL / REST APIs outside of Hasura? How do you reuse them without re-writing every functionality from scratch? Where does Hasura fit in this whole architecture? In this post, we will talk about how to architect your app to add Hasura that already has an existing system running.

- Making your GraphQL APIs production ready
- Secure your GraphQL API
- High Performance GraphQL
- Monitoring and Observability
- Join data with other sources
-
Reusing Existing REST APIs with Hasura
<!--kg-card-end: markdown--><!--kg-card-begin: html-->
Making your GraphQL APIs production ready
<!--kg-card-end: html-->
The hardest part about GraphQL APIs is not just writing the custom resolvers but also optimising them for high performance, caching and securing them. Making your GraphQL API production ready involves a lot of heavy lifting. In this section, we will look at how to
- Secure your API without writing any code
- Add GraphQL caching to reduce response times
- Monitor and observe APIs
- Join your response data with any source
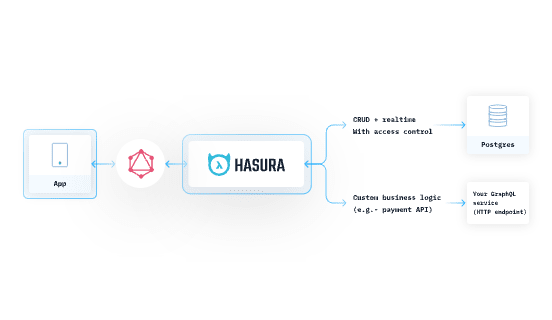
Hasura supports adding custom GraphQL servers via Remote Schemas. You need to plug your GraphQL endpoint along with the relevant auth headers and Hasura will introspect your API and add that schema to Hasura's existing GraphQL schema.
Hasura is designed to sit directly between your application and data sources.
Add your existing Server as a Remote Schema
Once you are on the Hasura Console, Head to the Remote Schemas tab of the console and click on the Add button.
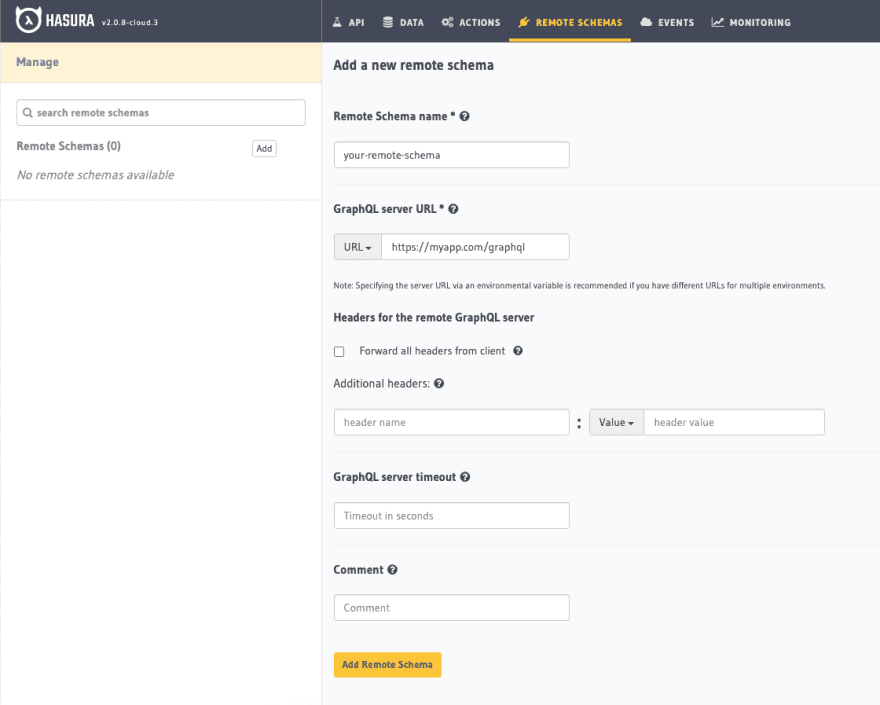
The GraphQL endpoint can be written in any language / framework of choice. Your GraphQL server should enable introspection for Hasura to be able to connect and add that schema.
This is the first step to bring all your existing GraphQL APIs to Hasura and create a unified endpoint.
Secure your GraphQL API
Now lets dive in to Security. Securing your GraphQL API needs to be approached differently. The typical REST API approach of rate limiting endpoint access and preventing attacks wont work with GraphQL, since you know, GraphQL API has a single endpoint and is schema based. Lets see how Hasura helps you here.
Add Authorization to your GraphQL Server
Writing authorization rules with GraphQL will deeply involve the GraphQL schema and potentially writing custom directives. Hasura lets you define these rules declaratively, without writing code. You can use the Console UI or the Metadata yaml to create these rules programatically. In the end, you get the benefits of
- No code
- Declaratively add permission rules
- Role based
- Field level granularity
- Apply token claims as filters
Once you have added your custom GraphQL server as a remote schema, you need to enable permissions for remote schemas. You can do so by adding the following environment variable.
HASURA_GRAPHQL_ENABLE_REMOTE_SCHEMA_PERMISSIONS: "true"
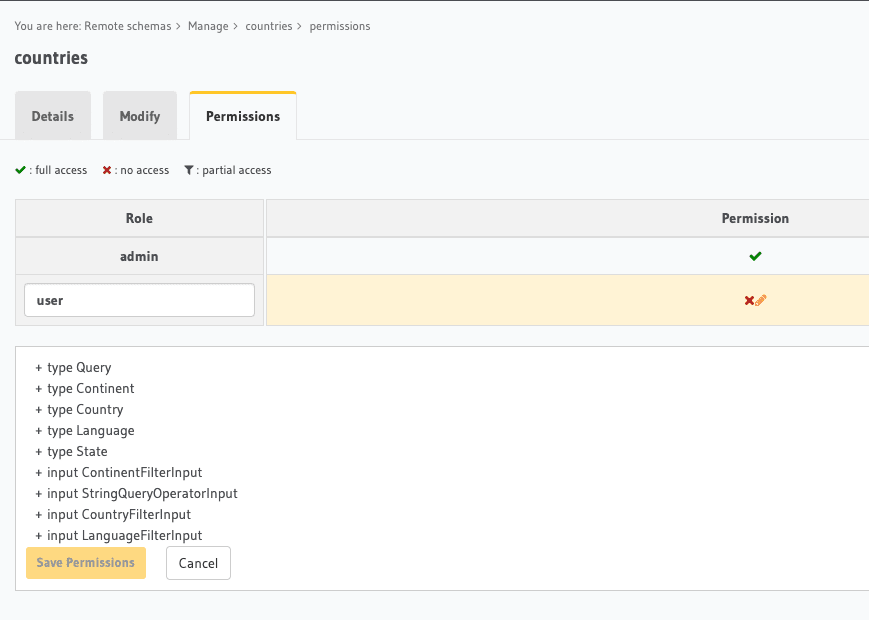
What you see below is the permissions UI of the Hasura Console. This lets you browse the GraphQL schema of your custom server and define role based permission for each query type.
Enable Rate Limiting and Query Depth Limiting
Defining authorization rules prevent unauthorized access to your data. But that doesn't prevent anyone from hitting your API and eventually your database/datastore. You would always want genuine requests to hit your database to serve the users of your app. This leads us to think about Denial of Service (DoS and DDoS) attacks, either volumetric or application level security.
To prevent attacks and API abuse, Hasura lets you
- Limit requests to your API per min/hour
- Apply limits based on user identity and session variables
- Prevent scraping and abusing with Allow Lists

High Performance GraphQL
With the right API limits configured, you prevent un-intented hits to the database. If you are using Hasura to connect your database(s), you don't need to worry about the typical N+1 problem. Optimising for performance though is not limited to the database but to the actual API being consumed.
This brings us to Caching GraphQL APIs on the Server Side. Typically your queries could be slow due to various parameters like size of the response, location of your server (thereby latency) and no of concurrent API calls. You want to keep the response times of your queries as low as possible.
Writing your own caching solution for GraphQL involves maintaining a low latency key-value store like Redis at the edge. Cache invalidation logic needs to be defined and how you cache authenticated data will usually require lots of boilerplate and logic specific code.
Cache your existing GraphQL Server
Hasura Cloud has support for caching your existing GraphQL server. You can
- Just use the
@cacheddirective to existing GraphQL query - Get automatic edge caching for free*
- Cache authenticated data <!--kg-card-begin: markdown-->

Since Hasura has metadata about the different GraphQL types used and the corresponding Authorization rules defined per role, it is able to offer an end to end caching solution.
Cache invalidation can be configured with the @cached directive arguments like ttl. You also get the flexibility of API access to manually clear cached data.
Once you hit your custom GraphQL server through Hasura with the cached directive, the HTTP response will include a Cache-Control header, that indicates the maximum number of seconds for the returned response to remain in the cache. The infrastructure of maintaining and invalidating the cache is taken care by Hasura Cloud.
*Support for Edge caching is coming soon to Hasura Cloud. Right now caching is limited to the region where the Hasura project was created.
Monitoring and Observability
Getting the performance and security benefits helps get your APIs production ready. But when the GraphQL API is running in production, you need true visibility into the system to diagnose issues or learn about user behaviour. At any point of time, you should be able to ask any arbitrary question about how your application works.
Hasura Cloud Console comes with the Monitoring tab which gives you detailed insights into your API availability and performance. You can
- Monitor errors and get detailed breakdown of individual requests
- Distributed tracing for your API
- Identify slow queries
- Websocket monitoring for realtime use cases <!--kg-card-begin: markdown-->
![]()
Since you are working with custom GraphQL servers, you want visibility into how the API request traverses through different components of the architecture. First your client hits the Hasura endpoint. Hasura parses the query to decide if it is a database query or a remote schema query and proxies the API call to the right connection.
Now the performance could be slow in certain components of this architecture and you want to get to the root of the problem whenever an issue arises. Distributed tracing attempts to give a unified view about the various performance characteristics of this architecture.

<!--kg-card-end: markdown--><!--kg-card-begin: html-->
Join API response with other data sources
Typically your custom logic and data from external sources will have some relationship with the rest of your API, either through database connection or through other external APIs.
Remote Joins in Hasura extend the concept of joining data across tables, to being able to join data across tables and remote data sources. Once you create relationships between types from your database and types created from APIs, you can then “join” them by running GraphQL queries.
- Establish relationships between other data sources via Remote Joins
- Join with database or any other GraphQL source <!--kg-card-begin: markdown-->
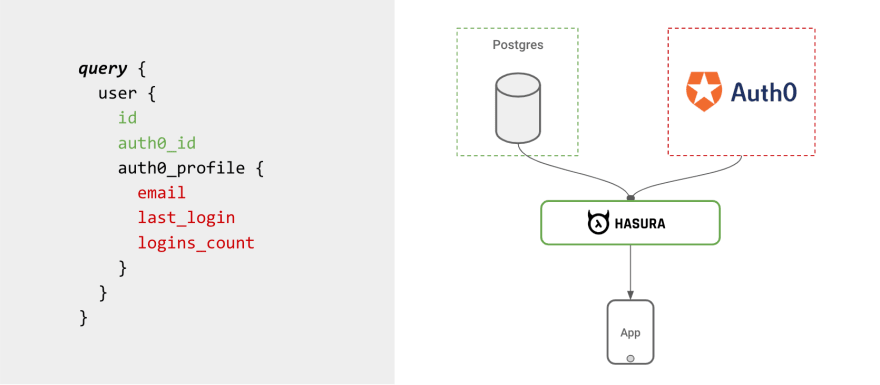
You can look at examples of Remote Joins to get an idea of setting up custom GraphQL servers and extending Hasura.
Get GraphQL over existing REST API
Writing a custom GraphQL server for business logic is a feasible option if you are starting from scratch. But what if you already have an existing REST API and want to reuse the logic? Now again, this could be re-used inside your GraphQL resolver. Hasura actually makes this easy by letting you
- Map your REST API to GraphQL types
- Generate boilerplate with codegen <!--kg-card-begin: markdown-->
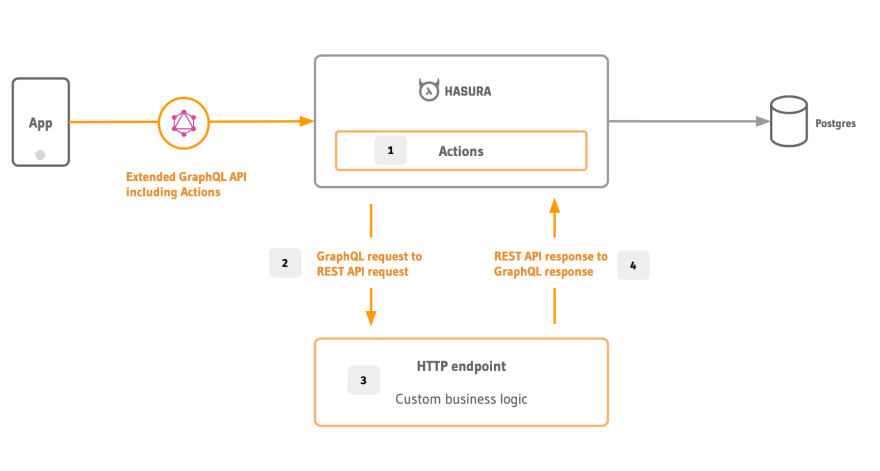
Actions work well in the 3factor architecture where the HTTP handlers can be deployed as serverless functions.
Read our series of posts on Turning your REST API to GraphQL using Hasura Actions.
Get started with production ready GraphQL today!

Top comments (0)