
Originally published in App Developer Magazine on 8th August 2018.
The transition from I.T’s role in organizations, from a mere horizontal function to one of a strategic advantage, is playing out the world over. However, most change management techniques behind these efforts tend to disproportionately focus on end-user facing software — often at the cost of intra-organization or internal applications (apps).
Internal apps propel data-driven decision-making or support an end-user facing service. They can also help you become a fast-moving, agile organization that today’s consumer expects and competition demands. It is critical for businesses to focus equally on the quality and feature velocity of internal apps.
In this post, let’s see how GraphQL can help a business do just that.
Challenges with internal apps in organizations
The development process for internal apps generally faces the following problems:
Budget & Staffing : Compared to user-facing apps, internal apps are often under-budgeted and understaffed. This shortcoming places a high premium on the productivity of the app dev team.
Compatibility with existing technology : Intra-organization apps are usually not greenfield projects, so they need to interact with data in existing systems. This requires different teams to coordinate with each other for every release. Having this kind of complexity and multiple stakeholders in the mix typically does not bode well for feature velocity.
The brunt of bad “build vs. buy” decisions is more acutely felt in a constrained environment. Therefore, a digression into targeting the right set of apps to build internally versus purchasing off the shelf (OTS) products is warranted.
Apps can be classified based on the complexity of analysis or business logic applied to data and the nature of their interaction with the underlying databases. The following is a useful guide to making build versus buy decisions based on this classification:

Now that we know what apps to build, let’s see how they can be built even better. But first, a brief introduction to GraphQL.
What is GraphQL?
GraphQL is a specification for a query language for APIs and a server-side runtime for executing queries. The open source spec is centered around a typed schema that is available to users of the API (mostly front-end developers) to make any CRUD queries on the exposed fields. It’s also agnostic to the underlying databases or any other source of data.
The key features of GraphQL that make it attractive for app development are:
Fewer errors : The typed schema leads to fewer errors, as commonly seen errors can be caught during the development stage itself.
Flexibility : Once supported, a schema can serve any permutations of queries against it. To use a simple example of a blog app, a schema that covers the tables for authors and articles, will serve both of these queries at no additional cost:
- Fetch a list of authors and each author’s articles
- Fetch a list of articles and each article’s author
Uniformity : Regardless of the source of data, GraphQL provides a uniform query interface for standardized app development workflows.
Extensibility : GraphQL can also be used to stitch together multiple sources of data to such a degree that it can interact with these disparate sources in the same API call.
Thanks to these reasons, GraphQL adoption has been growing by leaps and bounds. It is now being touted as an alternative to traditional REST APIs, because of its impact on API Lifecycle Management.
How GraphQL can help transform internal app development?
The impact of GraphQL on app development is rather apparent on API Lifecycle Management. Here’s how it affects the different stages of an API development cycle:
Fewer APIs: GraphQL’s schema-driven approach leads to fewer APIs having to be developed. As shown in the above blog app example, there is no incremental cost to a new API that interacts with the same schema. This flexibility also works where new APIs are needed purely to transform the format of the output on the server side; the GraphQL spec grants frontend apps the ability to dictate the format of the output and query for any slice of data they want.
Impact on client apps: The general front-end developer experience for consuming GraphQL APIs is fast becoming the gold standard that other dev tools are expected to emulate.
- Client-side code can be auto-generated from a GraphQL schema.
- Use-cases like real-time data, etc., from live queries are very easy to handle.
- Front-end developers spend much less time integrating with GraphQL APIs as compared to the same effort for REST APIs.
Automatic API documentation: With a published schema, GraphQL has API discovery or documentation implicitly built into the server, with tools that take advantage of this.
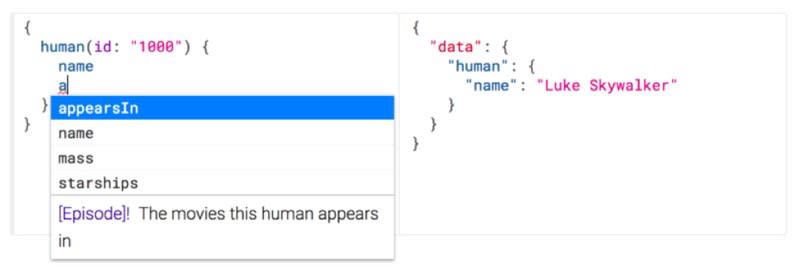
Testing & Deployment: GraphQL APIs need to be tested only when there’s a change in the schema or a fresh schema (the client still needs to be tested). This also holds true for deployments. Compared to REST APIs, where every iteration is a candidate for testing and deployment, the cost of Q.A and devOps is significantly lower.
GraphQL also helps reduce run-time errors and related testing due to its typed schema. Using client-side tooling/SDKs to exploit this benefit and provide compile-time, client-side query validations is the norm in the GraphQL ecosystem.
This is where my image “Query validation in an IDE preventing errors before reaching formal testing” should go with the caption below it

Standardized code and workflows: Working with a specification like GraphQL, enforces a certain amount of standardization in codebases and processes. Considering the attrition rates in IT, this is a solid benefit of GraphQL.
Compatibility with existing technology
Making apps work with the existing technology stack is an important use-case. In addition to leveraging existing investments, data from these different sources, especially legacy apps/DBs, often needs to be queried together. This almost always introduces a technical and operational nightmare.
GraphQL is great for placing different sources behind a uniform query interface as it is agnostic to the underlying database.
Here’s an anecdote from James Baxley from his experience with using GraphQL at NewSpring Church:
“We wanted to use the Meteor account’s system and reactive data, get financial accounts, show giving history, and show profile info from Rock, have all of our images and content stored in our CMS, and we wanted in-app search using Google’s site search API. Using the power of GraphQL, in one week a single developer was able to connect all of those databases and systems together into a single endpoint.”
Stitching together multiple sources of data is usually a one-time effort, that once handled, saves the need for expensive, cross-functional operations.
Concluding remarks
GraphQL’s efficiency, and the extent of automated tooling delivered, means that teams working on internal apps can work better with the typical budgetary/resource constraints, as dependencies on backend developers are significantly reduced. In fact, with some open-source tools auto-generating ready-to-use GraphQL APIs, GraphQL enables front-end developers to transition into full-stack developers who can manage entire apps by themselves.
Several well-known organizations like The New York Times, Github, Spotify, etc., have taken the plunge, adopting GraphQL as their primary API technology. The ecosystem is ripe with tools that handle most of the heavy-lifting. For example, Hasura provides a ready-to-use GraphQL server that automatically infers the schema from a database and manages the underlying implementation.
Therefore, it is imperative that organizations evaluate GraphQL and, if their findings are positive, begin to chart out an org-wide adoption roadmap. Trying out GraphQL on internal apps is a great, risk-free opportunity for any organization to do so.

Top comments (0)