TL;DR
The different approaches to add dynamic content to statically generated sites with JAMStack.
- JAMStack Constraints
- Types of Content
- Source data during build phase
- Static pages hydrated on client
- Separate Static and Dynamic pages
- Caveats
- Summary
JAMStack Constraints
JAMStack is an emerging architecture for web apps which aims to decouple frontend and backend dev teams. Read more about it here. The architecture allows for a performance and operational benefit by imposing a few key constraints on how you build your UI.
These are the key constraints:
Pre-built markup/UI
Markup is pre-built to ensure good performance and SEO. UI should be pre-built and deployed as HTML files instead of getting rendered on the client (like what vanilla SPAs do).
No server side code that deals with UI
No server side code implies that the UI developer deploys their code as an HTML/CSS bundle, focussing on rendering the frontend. They needn't do server-side templating / server-side rendering.
As you can imagine, these two constraints give the UI team great ownership in being able to deploy and own their code (no server-side complexity). There is no server side templating like how it's typically done in Django/Rails application and they can assume content will be injected into HTML from a data source.
JAMStack is great for static sites or static site generators, but the key question is, what about "dynamic" sites or apps?
Types of Content
Before we try out these approaches in-depth, let's walkthrough the different types of content to see which approach works for what. The content for a webpage comes from a data source, typically a database. This data could change frequently based on user interactions. There could be multiple data sources to get content from. For example, a blog can have content coming from a database and user information coming from an auth provider. Broadly content types can be classified to be one or more of the following:
User specific (public or private)
In case of static web pages, the content served would be the same for all users. But what if, depending on the user who is viewing the page the content served needs to be different? Users of the site can also generate personal content and how do you build all those static pages pre-deployment time?
The answer is simple. You can't build the markup ahead for user specific content. This gives us the classification based on whether the content is publicly accessible or protected. Content on a webpage can be public, accessible to all or protected behind auth and will be different for different users.
Frequency of updates (frequent / infrequent)
Another classification of content would be to base it off on whether the content changes and if so, how often. If content changes frequently, then it needs a dynamic runtime to take over from the pre-built markup that was generated.
Let's say there's page content that you want to change and you want to reflect the changes immediately to your users. With pre-built markup, this doesn't happen realtime and there is a delay with re-building and deploying. Content on a webpage can change frequently, realtime or doesn't change that often.
Interactivity (interactive / non-interactive)
Users interacting with the page in the form of search, comments, forms, e-commerce checkout, payments etc are dynamic and a pure static web page doesn't scale for these kind of interactions. And hence the final classification based on interactions. Content on a webpage can be either interactive or non interactive.
Choosing the right approach for your dynamic content
Let's see how we can apply different approaches to handle different types of content and decide which ones are more suitable for a given use case. Go over the below flow to see which approach is applicable for your use case.

We'll look at different approaches to handle dynamic content and how it can be implemented to make a JAMStack (pre-built markup) site dynamic.
Approach #1: Source data during build phase
The simplest way to make JAMStack Dynamic is to source dynamic content at build time. The content can come from any data source. Data sources can be markdown (suited for blogs/docs), JSON/YAML and APIs, including third party ones. The API(s) would be responsible for fetching content from a database or a datastore and thus makes it a powerful way to build sites with dynamic content.
The data sources are compiled to HTML, typically using a static site generator. During the build phase, these generators traverse through every path of the app and compile flat HTML files out of it. It uses specified data sources to compile the HTML.
Architecture
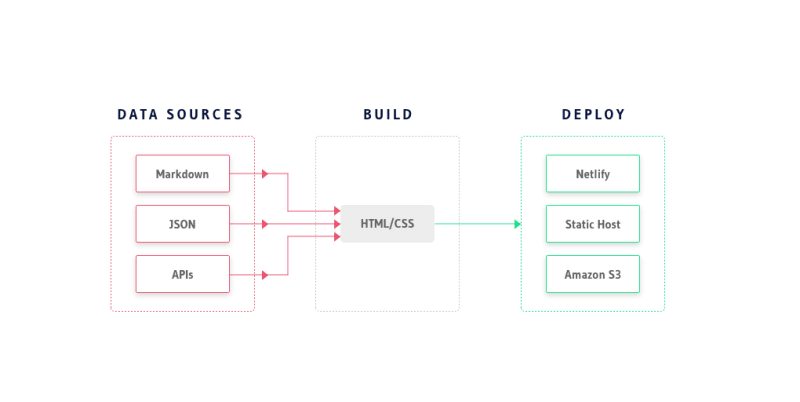
With git automation, git push should trigger an automated build which is then deployed to cloud providers. Add a CDN for caching and an app with decent traffic should run easily.
What is this architecture best suited for?
Let's say you have some data which is coming from the database (accessed using APIs) but is not updated frequently. With this architecture, you can cache content which is infrequently updated, and only trigger builds for the content that changes. Do note that the data still comes from a data source like a database/markdown during the build phase and hence any changes will reflect eventually.
Trying it out with Gatsby and Hasura
Hasura fits into Dynamic JAMStack with its unified GraphQL API sourced into Gatsby. Here's an example of using Gatsby with Hasura with dynamic content. Hasura is being used as a Headless CMS in this example and the amount of backend code written is significantly reduced.
Approach #2: Static pages hydrated on client
As you would imagine, just having pre-built content may not suffice for many apps. In this approach, we will look at how to fetch data at both build and run time for any page. This is achieved using a process called hydration, that allows static markup to be sent to the client which further becomes a dynamic app with the ability to manipulate the DOM. The benefit is obvious; users see a fully rendered page and then it becomes interactive like an SPA.
Now let's look at various possibilities of dynamic content on the client. You have a site that requires client side functionalities such as search, comments, handling forms and e-commerce actions. Do note that some of them could be coupled with Authentication/Authorization as well.
To handle these client side interactions, what we need is a pre-rendered static site + a dynamic runtime, maintaining the performance benefits and major parts of SEO.
Architecture
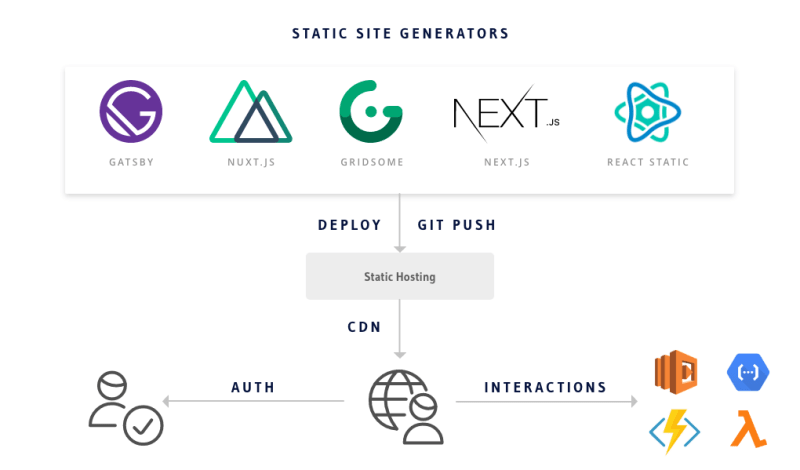
With the markup rendered on the client, we would like the client to take over to make it interactive. This should be possible with hydration.
Hydration
Hydration is a concept where the client expects the generated markup on both client and server to be identical. It is a process during which the framework (like react/vue) takes over the static HTML sent by the server and turns it DOM that can be manipulated and react to client-side data changes. In short, this makes sure that the client is ready for dynamic content without reloading.
All pages should work by default without JavaScript being enabled on the browser and client side rendering is just a progressive enhancement.
Interactions -> Serverless Functions
On the client side, the user would typically do auth (login/logout), interactive actions (search, comments) etc. The user interactions can be forwarded to serverless functions which can internally perform business logic to handle state of the app.
User interactivity can be lazy loaded on the client. Consider the example of this blog. The Disqus comments are loaded on the client where as the article was pre-rendered during build phase.
Realtime
Feed based UIs could require data to come in realtime. How do we update content on the UI realtime? Websockets FTW! A websocket connection can be setup to listen for notifications. Anytime new data comes in, the client is notified about the data update.

If you have access to a Realtime GraphQL API, it should be as simple as setting up websockets on the app to connect and fetch live data. Obviously this API needs to support Auth, in case it's required. Here's a reference video tutorial for how it's done with Hasura.
Asynchronous calls
On the client, you can make asynchronous calls to external APIs for fetching/mutating data for UI views which are not user blocking. The APIs can be serverless functions.
Trying it out with Gatsby and Hasura
Here's an example of using Gatsby with Hasura. Markup is hydrated on the client and some data is fetched only during runtime, assuming its dynamic.
Approach #3: Separate Static and Dynamic Pages
By now, you would have realised that static data is important for improved page load time and time to interactive. But what about pages which cannot be pre-built at all? Imagine a user profile page or a search results page. The content of these pages cannot be determined during build phase.
Some pages of the app are completely static, while some are completely dynamic. We can separate out the static and dynamic pages neatly, so that static pages get their performance boost, while dynamic pages are completely loaded on the client, behaving like an SPA.
Let's consider the example of an e-commerce product page to understand this better. There are some routes which are primarily static and doesn't have dynamic interactions on the client.

In an e-commerce site, pages can be pre-built for homepage, listing page, product page etc and can be rendered on the server. But user profile, search results, cart or payment pages cannot be pre-built. They are completely loaded on the client. Usually these pages are also behind Auth.
Completely Static Pages -> Sourced during build phase. Ideal for performance and SEO.
Completely Dynamic Pages -> Loaded on client side on demand. Interactive for users. Distributed the load to client. Protected routes are used to block access to users.
In the above example, product details would be pre-rendered markup where as ADD TO CART would be dynamic interaction on the client and the Cart page itself would be protected by auth, being completely dynamic.
Caveats
The approaches mentioned above come with a few caveats. Although they are not blockers, it's good to know them to know where this works and where it doesn't.
Completely Dynamic Apps
What about apps which are completely protected behind auth? Hasura Console is a good example of that; In fact all admin dashboards are protected behind Auth. Content can be different for users who have logged in. Obviously these pages cannot be built during compile time.
There is a way to handle this. This approach requires you to build your app as an SPA (Single Page Application) where everything is loaded on the client or SSR (Server Side Rendering) where the server compiles HTML on every request. I didn't mention this approach earlier because this doesn't have any pre-built markup and is not the scope of this post 😃
Updating Content
If data in the database changes, the app will not show the current data till it's rebuilt. So the option is to either trigger a rebuild whenever there is a data change or take advantage of hydration to update data dynamically on the client once the page is loaded.
What about large sites?
Build time increases with fairly large sites. Assume a content site with over thousands of posts. Rebuilding all the pages would be very slow. Deployments need to be instant. So how does one perform quick deployments?
Incremental builds is the way forward. Here’s a good read from Netlify. The idea is to cache the older content which doesn't require changing and rebuild only the pages which have been added recently so that deployments are instant. This solution may not exist for all frameworks today.
Summary
JAMStack is a neat architecture to highlight the benefits of static sites that we were building a few years ago (and continue to). The idea behind Dynamic JAMStack is to get pre-built markup to the client as much as possible and do progressive enhancement on the client via Hydration to open up a lot of possibilities.
Coupled with modern frontend frameworks and headless CMS, these static sites can become truly dynamic bringing in a whole lot of benefits and flexibility to build powerful apps. This way we build sites for performance.
Of course these approaches may not be suitable for all types of apps. There are still use cases which requires an app to be completely SPA or completely SSR for obvious reasons and they continue to work well in their current architecture.
Here are some good reads:





Top comments (0)