
This is the story of how I wanted to try out the speech to text offerings from Azure Cognitive Services and eventually ended up building a prototype of a podcast transcription service that automatically transcribes any new episode of your podcast and displays synchronized transcripts alongside your audio making your podcast more accessible.
Transcripts provide multiple benefits for the podcast host as well as the listeners. More importantly, it is the right thing do because it makes your web content more accessible. You can read more about this at Podcast Accessibility.
If you want to see this in action, take a look at Hanselminutes++ (running on free plan on Azure) which is a minimal clone of the popular Hanselminutes podcast with synchronized transcripts.
You can also find the source code on github.
The transcripts for HanselMinutes are Artificial Intelligence powered and is about 85%-90% accurate (rough calculation) and extremely affordable at approximately 1 USD / hour of audio when done.
Story Time
The meeting / conversation transcription showcase from Microsoft Build 2019 was lingering on the back of my head and so I wanted to try it out. Although, the meeting transcription service required custom devices, I liked what I saw with Batch Transcription offerings. I decided to give that a try and this is what followed.
1. Azure Batch Transcription
I followed the docs and created a new Speech Services instances on Standard S0 plan in the West US region. I decided to start making POST requests to the transcription endpoint from the Swagger Page after authorizing the requests with my subscription key.
{
"recordingsUrl": "<SAS URI of Blob>",
"models": [],
"locale": "en-US",
"name": "Title of the episode",
"description": "An optional description of the episode",
"properties": {
"ProfanityFilterMode": "Masked",
"PunctuationMode": "DictatedAndAutomatic"
}
}
I realized that I had to input valid Azure Blob SAS URI for the recordingsUrl field. So, I downloaded a mp3 file from Hanselminutes, uploaded them to storage account with storage explorer, generated SAS URI and made requests.
Every episode of Hanselminutes is 30 minutes long and it took almost the same time to transcribe each episode. I learnt that I can register a webhook where the results will be POSTed once they are completed and avoid constantly polling the API to check if transcription is completed.
Side Comment: I tried transcribing all the Hanselminutes episodes from 2018 and 2019 but there were issues transcribing certain episodes and I have a question on StackOverflow about it. I also have questions about request throttling and support for blob storage that are not clear for me from the docs.
2. Azure Functions
I got my first transcription result and I was happy with what I saw. Now, I wanted to transcribe several episodes and realized that it quickly became a tedious task to download mp3 files, upload to Azure Storage and then fire off transcription requests. My developer brain was screaming out for something like Azure Functions and so it I wrote some.
2.1 Http Triggered Function
- Accepts a URL of an mp3 file in the triggering request
- Downloads the mp3 file as a stream.
- Uploads it to a Storage Account.
2.2 Azure Blob Triggered Function
This function is triggered whenever there is a new blob with an .mp3 extension in the storage account.
- Generates SAS URI for the blob
- Makes a transcription request to the transcription endpoint
2.3 HTTP Triggered Azure Function
This is the function that receives the HTTP callbacks when the transcription process is completed
- Processes the transcription results.
- Initially I wanted to simply view the transcripts
- Later (when I started to build a Hanselminutes clone) decided to store them inside Azure CosmosDB.
3. Azure Logic App
I still needed links to the audio file for each episode of the podcast. I know I can get that from the RSS Feed and I decided to opt for a no-code solution and use the RSS Connector to parse RSS feeds. Although I say things like no-code solution, the truth is that I wanted to try out Logic Apps. ;) ;)
3.1 A Custom RSS Feed
Hanselminutes is a weekly podcast but I needed a RSS Feed that updates way more frequently and on my schedule. I decided to set up my own RSS Feed with my fork of the Lorem RSS Feed where I have only feed item that regularly updates.
For development purposes, I trigger a check on my fake RSS Feed for updates and when there are updates to my feed, HTTP POST items from Hanselminutes feed to the HTTP triggered azure function. Not pretty, but works for now.
4. Azure Web App and CosmosDB
I searched the internet to see if Hanselminutes already had transcriptions and I only found some broken / outdated links. I’m guessing transcripts existed at one point but they no longer do. This was a good excuse for me to build a minimal Hanselminutes clone with transcriptions. I decided to go with CosmosDB to store transcripts and updated the Azure Function to store results in CosmosDB and built an ASP NET Core Web App that spoke to CosmosDB.
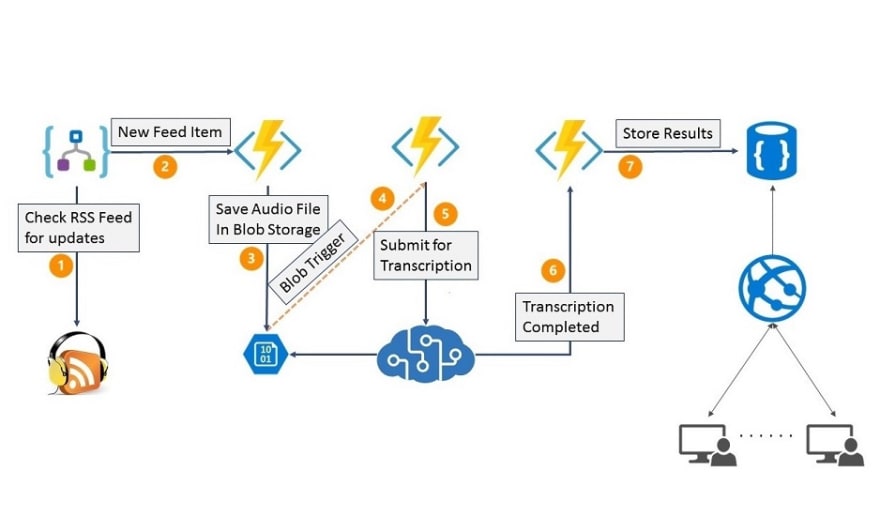
Costs
The core transcription service from Azure Cognitive Services costs 1 USD / hour of audio in the Standard Plan.
Azure Storage, Azure Functions and Logic Apps are relatively dirt cheap that you can consider them as free value additions.
I store the transcripts on Azure Cosmos DB which has a complex pricing model and it costs a fair bit with the starting price around 24 USD / month. Continue reading to know how the next version addresses this in the next version.
The Hanselminutes clone is hosted on Azure App Service but if you host a podcast you would already have your own website.
Plans for the Next Version
Clearly, Azure CosmosDB is a major cost barrier and the costs can quickly skyrocket with the popularity of the podcasts. I am considering posting transcription results directly to github instead of storing it inside CosmosDB. This allows the transcripts to be “open source” and take community contributions towards increasing accuracy and more importantly drive the costs down significantly.
The RSS Connector on Logic App was great for a quick start but it has introduced a lot of limitations and ‘code smells’. I have decide to replace the RSS connector with this library.
I plan to provide two separate Azure Functions, one to transcribe new episodes and the other to transcribe episodes from your archive.
The editing experience could also be much better. In fact, it would be great to have a standalone editor running on github pages with the ability to import and edit speech to text results generated by Azure and later accommodate other transcription engines as well. Import your transcript ➡️ Make corrections ➡️ Export. Send a pull request.
The ability to distinguish between speakers would be great but “not today”…[Update 17 June,2019] : Azure Speech Services now supports Speaker Diarization.
I expect the next version to shape up like the picture below and once the project reaches there, the transcription costs will be available at approx 1 USD / hour which is how much Azure Transcription Service cost. The rest of the value add stuff which complements your workflow is available at a paltry budget. No more of that submit your audio file for transcription and we will email you transcripts in 24 hours that you can later add to your website.
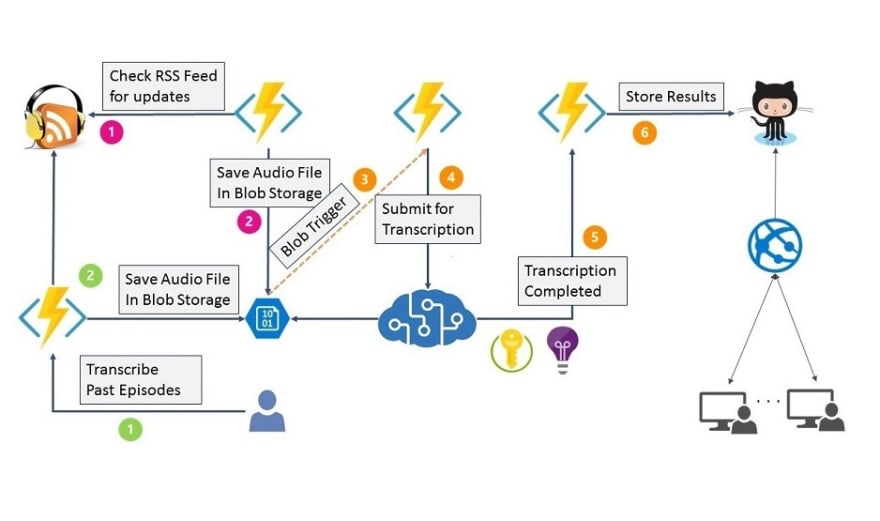
High Level Overview of the Next Version
Closing Remarks
It started with me wanting to try out the Batch transcription API on a Saturday morning to see if it was any good. A week’s worth of effort later, I end up here. Although this was a fun side-project, I am quite happy with how this turned out considering the below facts.
Did I know anything about how the internals of speech-to-text Artificial Intelligence magic works ? No.
Forget Artificial Intelligence. I did not know how to implement synchronized scroll by myself. I spent a good 4-6 hours on that before giving up and building on top of the scrollTo Library. Was never good with JS anyway.
The only “original code” that I wrote was the logic to to trigger the scroll of in sync with the audio. That was it. Around 50 lines of javascript. The rest of the code was mostly straight out from the Azure docs.
It has been a fun ride building on the shoulders of the giants and their abstractions and I want to see how far forward I can take this.

Top comments (0)