
In Part 1 of this series, I shared my plan for rebuilding my personal website. Before I start thinking about changes to user interfaces or HTTP responses, I need to clean up the mess I created with my poorly designed data model. In this post, I’ll focus on my experience with Amazon DynamoDB and the role that service will continue to play in my site’s architecture. Let’s go over some core DynamoDB concepts so we can shine a bright light on my missteps.
Some Basics
DynamoDB stores data in tables. If you’re familiar with other popular database systems, chances are you’ve come across tables working with those systems, too — and the idea here is pretty similar. Tables are made up of zero or more items. An item can be compared to a row in a relational database, and is made up of attributes . An attribute can be likened to a table column, and can be one of the following types: String, Binary, Number, Boolean, Null, List, Map, StringSet, BinarySet, and NumberSet.

The example above is an excerpt from a Songs table. Artist, SongTitle, and AlbumTitle are attributes. The second item in that table is represented visually as a row whose attribute values are the following strings:Eric Lau, Cloudburst, and Quadrivium.
On Being Ridiculous
That all seems pretty familiar, right? And simple, too? If you’re like me, it sure does. And if you’re like me, you started reading the documentation to figure out how to get started. You read through all that jazz about tables and attributes and groggily declared to yourself, somewhere around 10 PM at night, “I know this stuff”. And then you saw, later on in the documentation, mention of “primary keys” and “indexes”, and smirked — defiantly — at the thought of having to read more explanations of concepts that you’d already “mastered”. So you skipped it all and went straight to table creation… and just figured out the rest as you went along.
Do not do any of that.
Primary Keys
Without an understanding of how primary keys work in DynamoDB, you won’t be able to design your tables in a way that will allow you to efficiently retrieve data from them. To start, there are two kinds of primary keys in DynamoDB: simple and composite.
A simple primary key is a partition key made up of one attribute. You’ll sometimes see the partition key referred to as the hash key or hash attribute because it’s used in an internal hash function that evenly distributes items across partitions. In tables that only have partition keys, each item must have its own unique partition key value.
Composite keys are made up of two attributes — the partition key and the sort key. You’ll sometimes see the sort key referred to as the range key or range attribute , as items with the same partition key are stored physically close together and sorted by the sort key value. In tables that have both partition keys and sort keys, two items can share the same partition key value so long as those two items also have different sort key values.
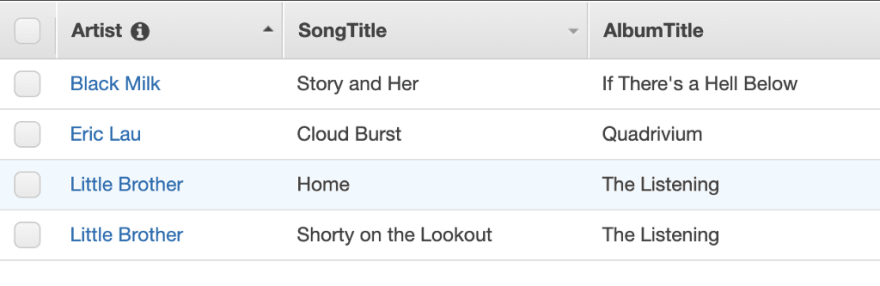
Consider the Songs table again. It has a composite primary key, composed of the Artist attribute (partition key) and SongTitle attribute (sort key). Note that there are two songs with the same partition key values (Little Brother), but they also have different sort key values (Home and Shorty on the Lookout).
Retrieving Items
After you’ve defined your table’s primary key and have added items, you’ll eventually want to retrieve that data. That can be done in a number of ways; the primary operations you’ll use to retrieve a collection of data are the Scan and Query operations.
The Scan operation can be used to retrieve all of the data in a table. You can apply a filter expression to refine your results and define the attribute set that you’d like to see returned. A Scan can be executed without a primary key being provided in a request.
The Query operation can be used to find items based on primary key values. In order to execute a Query operation, you must, at the very least, provide the name of a primary key and a corresponding value. You can also provide a sort key and use a comparator operator to further refine your results. More refinement can be done with key condition expressions as well as filter expressions.
On Being Ridiculous: The Aftermath
I originally designed my tables without paying much attention to any of the stuff I’ve written here since the “Primary Keys” heading. I assumed DynamoDB worked the way other popular NoSQL solutions worked, and that silly assumption informed my approach.
I decided to store all of my social media posts in a posts table that felt more like a MongoDB collection than a DynamoDB table. I used an attribute called id as the table’s partition key. No sort key. And in the absence of a sort key, I had to use the Scan operation to retrieve results. But the results were never sorted as expected. So I did some Googling and found this issue:
How to order a scan results by createdAt · Issue #346 · aws-amplify/aws-sdk-ios
Here’s a quote from the thread:
DynamoDB doesn’t support sorting in a scan operation, which makes senses [sic], as ordering in a full table scan is usually unnecessary.
Ugh. So I was forced to actually read more of the docs, and I found this:
Query results are always sorted by the sort key value. If the data type of the sort key is Number, the results are returned in numeric order. Otherwise, the results are returned in order of UTF-8 bytes. By default, the sort order is ascending. To reverse the order, set the ScanIndexForward parameter to false.
Ugh * ugh. Sort keys open up retrieval options, including those made available through key condition expressions.
Righting Wrongs
A few months ago, I created a new table to hold posts, and that new table has a composite primary key. The partition key is the table’s source attribute (with values like Twitter, Instagram, etc.), and the sort key is the createdAt attribute (the post’s timestamp). Now that I can use the Query operation, I can sort results by timestamp and use key condition expressions to write more complex queries. I also plan to add at least one secondary index so I can query against other item attributes like body.
My API is still pointing to the old table. A bit of code is required to convert the different timestamp formats into one format I can use in the new table, so I have to sync the two tables using a script until I can get that conversion code into the /posts endpoint’s POST method and point to the new table (more on that later on in the series). Still, though, I’m in much better shape overall.
Guillermo uses GUIs
The last DynamoDB-related change I’ll be making involves the addition of a new tool into my workflow: NoSQL Workbench for DynamoDB. The UI is pretty intuitive, and I like not having to log into the AWS admin console to interact with my tables. There’s an operation builder feature that is especially helpful for creating filter expressions and, of course, executing operations. The builder can generate Python, Node.js, and Java code for you as well.

Next Steps
Now that I’ve got the data set up correctly, I need to create the data pipeline that will allow me to ultimately use Amazon QuickSight to make sense of my social media activity and health data. I’ll be setting all of that up with AWS Glue and Amazon Athena.
Stay tuned for Part 3 in the series, friends!

Top comments (0)