I am new to dev.to community would like to share a solution we implemented at BGL for YOLO model inference(any general model inference also applies) and hope you find it helpful.
Inference cost may count for a large proportion of computing cost, in order to address this concern and reduce high inference cost, AWS already offers several model inference solutions for a wide range of scenarios:
But what if you're looking for a more flexible, customizable serverless solution with an even lower cost? And most importantly, one that can potentially be “lifted and shifted” to other cloud platforms if your organization is dealing with multi-cloud infrastructure. or worried about having the solution locked in with one specific provider?
Welcome to BGL’s story about how to implement AWS Lambda as a model inference service to handle a large volume of inference requests in production.
Context:
Our engineering team is building an AI product to automate several business processes. Both Hugging Face Transformer (For NLP task) and YOLOv5(For object detection tasks) frameworks are integrated and several models had been trained based on the business cases and datasets. Inference API is integrated with the existing business workflow to automate the process so the organization can pull resources away from tedious and low-value works and reduce operating costs.
The current system is handling 1000+ inference requests/day with a 50x volume growth in the near future. Once the model candidate is deployed to production and stable, the main cost would be on the model inferencing.
The Solution Design
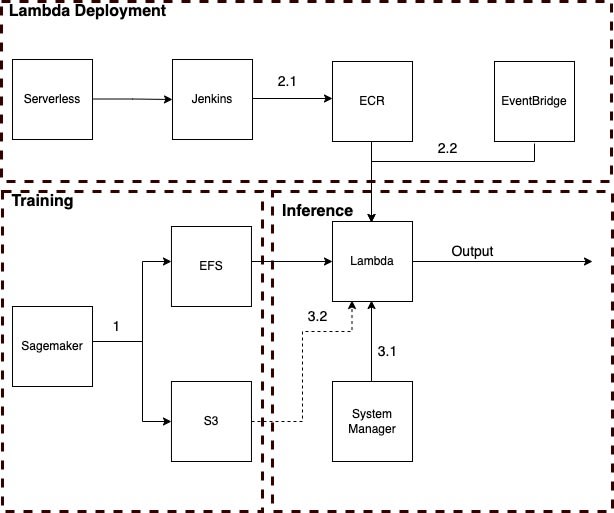
The solution utilizes several AWS services with the following purposes (under the solution’s context):
- Sagemaker: Training custom model
- EFS: Storing artifacts of the trained model, as the primary model loading source
- S3: Storing artifacts of the trained model, as a secondary model loading source
- ECR: Hosting Lambda docker image
- EventBridge: A “Scheduler” to invoke Lambda System Manager: Storing model path in parameter store
Training:
- Sagemaker normally compresses and outputs the model artifacts to S3. In this case, additionally, one copy is also saved to EFS(explained in 3.2) by adding an extra Sagemaker channel name.
Lambda Deployment:
2.1 Serverless Framework is used to manage Lambda configurations with all required packages and Lambda script built through Jenkins and Docker into a docker image that is further pushed to ECR.
Note: The model artifacts are not embedded in this image, they stay at both S3 and EFS.
Here is an example of the docker file for building the Lambda image:
- Public lambda basic image from AWS (public.ecr.aws/lambda/python:3.8.2021.11.04.16)
- Copying Lambda logic written in awslambda.py
- Copying the YOLOv5 project (originally cloned from YOLOv5) as loading a YOLOv5 trained model locally in Lambda would require it
- All packages required are defined in a separate file called lambda-requirements.txt which is under the same directory

2.2 Each Lambda has an associated EventBridge rule configured (in Serverless YAML file). EventBridge invokes Lambda by every 5 minutes with two important purposes:
- Keeping Lambda warm to avoid the cold start without triggering an actual inference request
- Pre-loading the desired model in the first warming request and then caching it (through a global variable), will significantly reduce the inference lead time caused by model loading for subsequent actual inference requests.
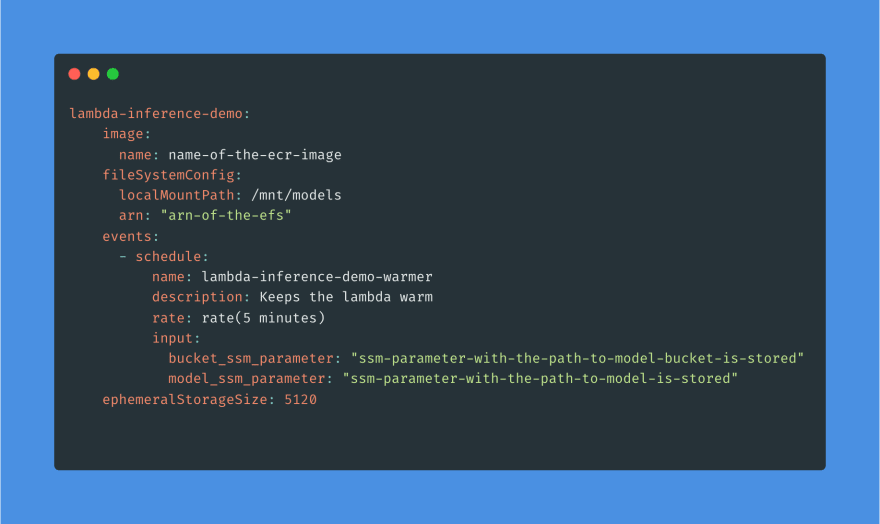
The code snippet above shows the structure of the Lambda configuration used in Serverless YAML file. For details please refer to Serverless Framework Documentation, key points are:
ephemeralStorageSize 5120 will configure the size of ‘/tmp’ folder of a Lambda to 5120MB(explained in 3.2)
Model bucket and path as input parameters of EventBridge invoke (explained in 3.1)
Inference
The diagram below explains the Lambda handling logic, the principle behind is to check whether the invoke is triggered:
By lambda warming request(through EventBridge) -> load the mode (for the first time) & cache -> return without processing inference, or
By a actual inference request -> process inference -> return inference result
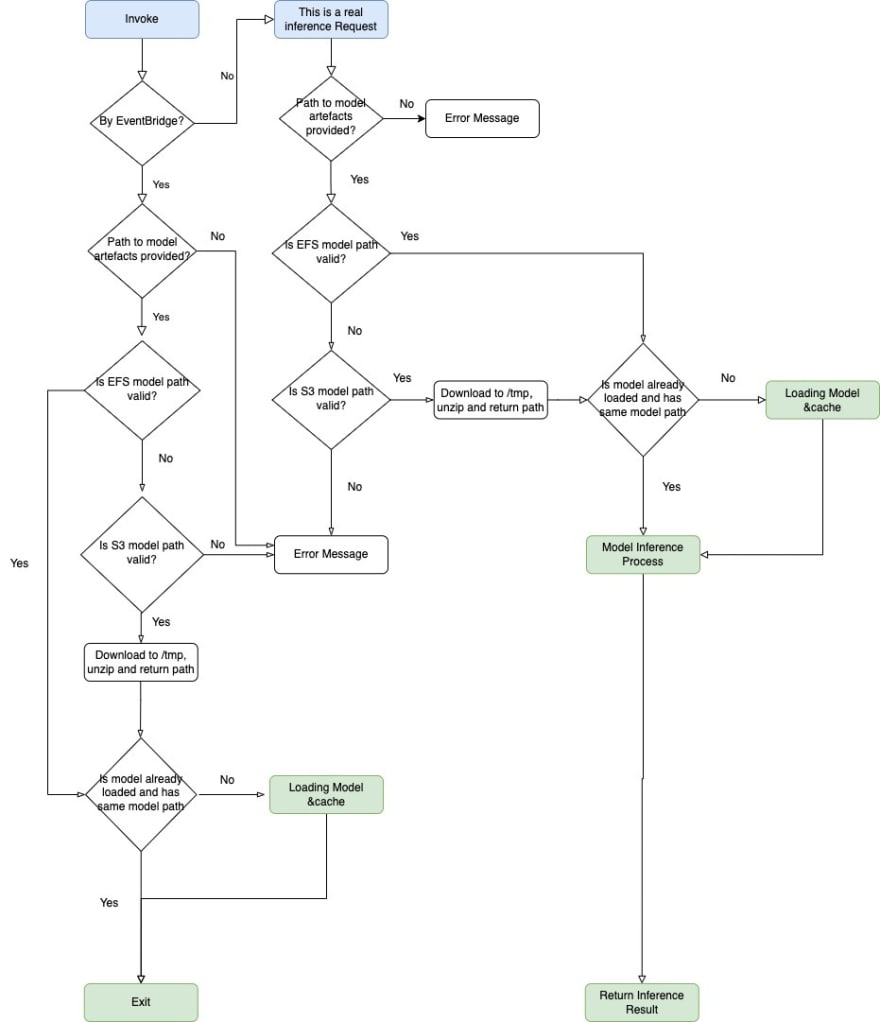
3.1 The S3 bucket and corresponding model path are saved in the System Manager parameter store so this is uncoupled from Lambda deployment. Engineers can point the Lambda to any desired model by changing the parameter without redeploying this Lambda.
3.2 EFS is a file system, so mounting and loading the model straight from EFS would be much faster (please keep a close eye on EFS bandwidth cost). In case the EFS loading fails (invalid path, bandwidth constrained, etc), Lambda downloads the model artifacts from S3 to the local ‘/tmp’ directory and loads the model from there. It is important to make sure Lambda has enough storage for ‘/tmp’ (ephemeralStorageSize parameter is set to 5120MB in our case)!
Loading YOLOv5 model locally in Lambda is straightforward:

- Make sure you copied the yolov5 project directory (mentioned in 2.1) and set the path of the directory to repo_or_dir
- Use model= ‘custom’ and source= ‘local’
- The path points to a valid *.pt YOLOv5 trained model.
Limitations
No solution is perfect, it all comes with tradeoffs and limitations, some of the limitations of the proposed solution are:
- Lambda inference is not set for a real-time inference which requires real-time processing and very low latency
- Lambda has a 15-minute runtime limitation, it will fail if inference takes too long
- EFS bandwidth cost is an extra cost but you could switch to S3 downloading & loading as the primary method with EFS mounting & loading as the secondary. It is slower but cheaper and the batch inference is not sensitive to latency in general
Potential Lift & Shift
Some features/design patterns of this solution can be potentially lifted & shifted to other cloud platforms (Azure, GCP for instance) as they offer similar services as AWS, two valuable ones are:
- Using low-cost serverless computer services (Azure Functions, GCP Functions)to serve model batch inference and integrate with a ‘scheduler’ to keep the service ‘warm’
- Designing logic to pre-load & cache the model to reduce inference processing time.
Summary
Thanks for your reading and hope you enjoyed this article, here comes some key takeaways:
- AWS Lambda, EFS, and S3 can be combined into a cost-efficient, scalable & robust service for model batch-inference(up to 15 minutes)
- Implementing the AWS EventBridge Lambda trigger properly can help to minimize Lambda cold-start
- Implementing a model pre-loading&caching logic in Lambda will help to reduce model inference lead time
- Passing the model path as a system parameter instead of embedding the model into the Lambda image yields more flexibility (decoupling)
- There are potential lift & shift opportunities to apply a similar concept on other cloud platforms




Top comments (0)