In my previous article, we introduced a cost-effective inference architecture that successfully handles approximately one million inferences per month in our live production environment.

Previous logic:
Upon receiving an inference request, Lambda will load the specified model, which is mounted on the Amazon Elastic File System (EFS).
In the event that loading the model from EFS fails, the system will resort to fetching the model from Amazon S3 as a backup solution (Alternative 1)
One challenge associated with this solution is that during a scale-up scenario, when a large number of concurrent Lambda functions are invoked, they all attempt to load models from EFS simultaneously. This surge in demand can quickly exhaust the reserved bandwidth (throughput), leading to numerous inference timeouts.

Solution 1 (Not recommended):
While increasing the provisioned throughput may seem like a straightforward solution, this can prove to be costly and is therefore not recommended.
Solution 2 (Recommended):
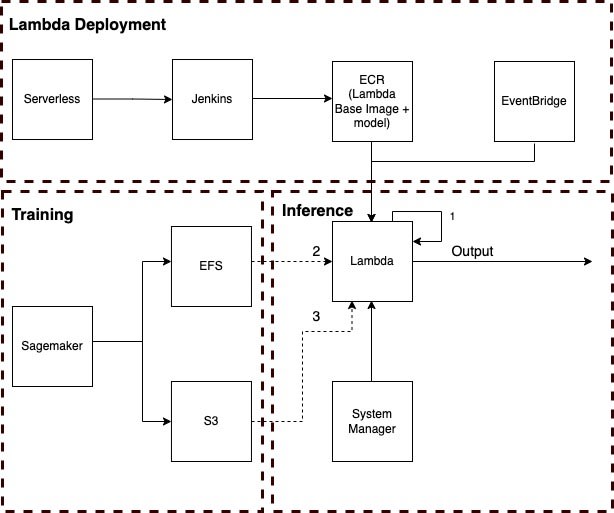
Injecting the model into the base image used by Lambda allows each inference to load the model from 'local', resulting in reduced inference latency and cost savings on EFS. If this approach fails, the following backup solutions are in place:
Loading the model from EFS (Backup Solution 1)
Loading the model from S3 if EFS loading fails (Backup Solution 2)
Results:
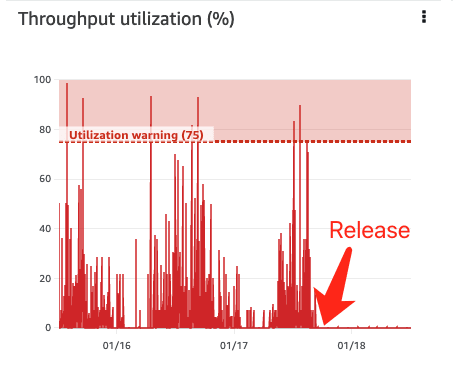
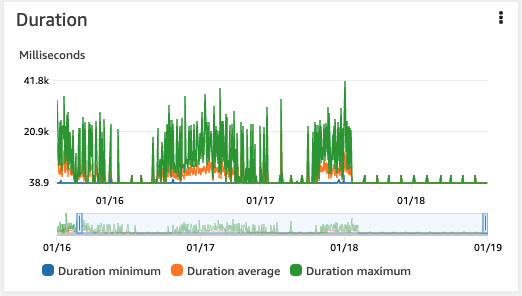
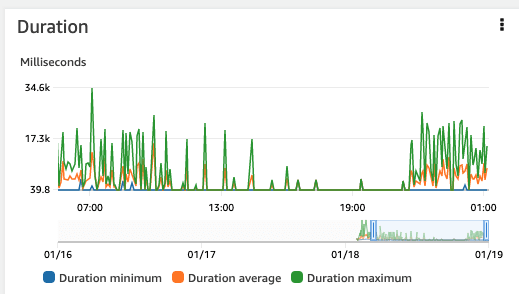
Upon implementing the model injection, there is a notable reduction in both EFS throughput and Lambda inference duration, resulting in decreased costs and improved performance.

Top comments (0)