
I have been keep testing different scenarios with OneTrainer for Fine-Tuning SDXL on my relatively bad dataset. My training dataset is deliberately bad so that you can easily collect a better one and surpass my results. My dataset is bad because it lacks expressions, different distances, angles, different clothing and different backgrounds.
Used base model for tests are Real Vis XL 4 : https://huggingface.co/SG161222/RealVisXL_V4.0/tree/main
Here below used training dataset 15 images:

None of the images that will be shared in this article are cherry picked. They are grid generation with SwarmUI. Head inpainted automatically with segment:head - 0.5 denoise.
Full SwarmUI tutorial : https://youtu.be/HKX8_F1Er_w
The training models can be seen as below :
https://huggingface.co/MonsterMMORPG/batch_size_1_vs_4_vs_30_vs_LRs/tree/main
If you are a company and want to access models message me
-
BS1
-
BS15_scaled_LR_no_reg_imgs
-
BS1_no_Gradient_CP
-
BS1_no_Gradient_CP_no_xFormers
-
BS1_no_Gradient_CP_xformers_on
-
BS1_yes_Gradient_CP_no_xFormers
-
BS30_same_LR
-
BS30_scaled_LR
-
BS30_sqrt_LR
-
BS4_same_LR
-
BS4_scaled_LR
-
BS4_sqrt_LR
-
Best
-
Best_8e_06
-
Best_8e_06_2x_reg
-
Best_8e_06_3x_reg
-
Best_8e_06_no_VAE_override
-
Best_Debiased_Estimation
-
Best_Min_SNR_Gamma
-
Best_NO_Reg
Based on all of the experiments above, I have updated our very best configuration which can be found here : https://www.patreon.com/posts/96028218
It is slightly better than what has been publicly shown in below masterpiece OneTrainer full tutorial video (133 minutes fully edited):
I have compared batch size effect and also how they scale with LR. But since batch size is usually useful for companies I won't give exact details here. But I can say that Batch Size 4 works nice with scaled LR.
Here other notable findings I have obtained. You can find my testing prompts at this post that is suitable for prompt grid : https://www.patreon.com/posts/very-best-for-of-89213064
Check attachments (test_prompts.txt, prompt_SR_test_prompts.txt) of above post to see 20 different unique prompts to test your model training quality and overfit or not.
All comparison full grids 1 (12817x20564 pixels) : https://huggingface.co/MonsterMMORPG/Generative-AI/resolve/main/full%20grid.jpg
All comparison full grids 2 (2567x20564 pixels) : https://huggingface.co/MonsterMMORPG/Generative-AI/resolve/main/snr%20gamma%20vs%20constant%20.jpg
Using xFormers vs not using xFormers
xFormers on vs xFormers off full grid : https://huggingface.co/MonsterMMORPG/Generative-AI/resolve/main/xformers_vs_off.png
xformers definitely impacts quality and slightly reduces it
Example part (left xformers on right xformers off) :

Using regularization (also known as classification) images vs not using regularization images
Full grid here : https://huggingface.co/MonsterMMORPG/Generative-AI/resolve/main/reg%20vs%20no%20reg.jpg
This is one of the biggest impact making part. When reg images are not used the quality degraded significantly
I am using 5200 ground truth unsplash reg images dataset from here : https://www.patreon.com/posts/87700469
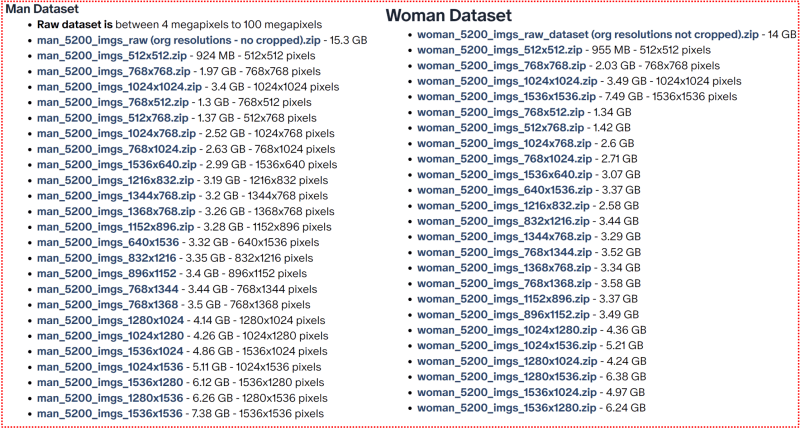
Example of reg images dataset all preprocessed in all aspect ratios and dimensions with perfect cropping

Example case reg images off vs on :
Left 1x regularization images used (every epoch 15 training images + 15 random reg images from 5200 reg images dataset we have) - right no reg images used only 15 training images
The quality difference is very significant when doing OneTrainer fine tuning

Loss Weight Function Comparisons
I have compared min SNR gamma vs constant vs Debiased Estimation. I think best performing one is min SNR Gamma then constant and worst is Debiased Estimation. These results may vary based on workflows but for my Adafactor workflow this is the case
Here full grid comparison : https://huggingface.co/MonsterMMORPG/Generative-AI/resolve/main/snr%20gamma%20vs%20constant%20.jpg
Here example case (left ins min SNR Gamma right is constant ):

VAE Override vs Using Embedded VAE
We already know that custom models are using best fixed SDXL VAE but I still wanted to test this. Literally no difference as expected
Full grid : https://huggingface.co/MonsterMMORPG/Generative-AI/resolve/main/vae%20override%20vs%20vae%20default.jpg
Example case:

1x vs 2x vs 3x Regularization / Classification Images Ratio Testing
Since using ground truth regularization images provides far superior results, I decided to test what if we use 2x or 3x regularization images.
This means that in every epoch 15 training images and 30 reg images or 45 reg images used.
I feel like 2x reg images very slightly better but probably not worth the extra time.
Full grid : https://huggingface.co/MonsterMMORPG/Generative-AI/resolve/main/1x%20reg%20vs%202x%20vs%203x.jpg
Example case (1x vs 2x vs 3x) :

I also have tested effect of Gradient Checkpointing and it made 0 difference as expected.
Old Best Config VS New Best Config
After all findings here comparison of old best config vs new best config. This is for 120 epochs for 15 training images (shared above) and 1x regularization images at every epoch (shared above).
Full grid : https://huggingface.co/MonsterMMORPG/Generative-AI/resolve/main/old%20best%20vs%20new%20best.jpg
Example case (left one old best right one new best) :
New best config : https://www.patreon.com/posts/96028218


Top comments (0)