
The source code of solution presented in this article,is available at
my GitHub repo pageA portable release, no .Net Core installation required, can be obtained in the GitHub Release page
I've always been really passionate about digital audio processing. In the last decade, the cloud power has spinned incredible advancement in those techniques. A really interesting area is related to the tools each CSP (Cloud Service Provider) is providing to empower developers in creating interesting use cases.
The Speech-To-Text and Text-To-Speech are now widely used service, due to the network speed that is no longer a bottleneck, in most of the cases.
I had recently faced a challenge in creating a DEMO where an hardware device, triggered by a command, posted a wave audio file recording to a folder on a server.
Then the desiderata was to have the transcript of the recorded audio along with the original recording.
This project aimed to create a simple Windows Background service in C# code, to perform subsequent Speech-To-Text (STT) process using Azure cloud.
The first challenge was that the file format could be a Wave PCM with 4 channels, recorded at 48 kHz. Not really a friendly format digested by cloud STT (Speech-To-Text).

The second challenge was to have this service run autonomously on a windows server.
The Speech API I'm using is the synchronous one, so this project fit great when you don't want to setup complex architecture on Azure and you prefer the processing on the VM. Another point is when you want to transcript short duration file. The transcription, in fact stop when a long pause is detected in the original file.
To process long file and if you prefer a more "Batch" solution take a look to this great solution by PanosPeriorellis .
Check out the dedicated documentation regarding Batch Transcription API for further info.
So, in brief, the required workflow was:
- Run in background on a windows machine, even after a reboot
- polling on a specific folder, waiting for new wave files
- when a new file is detected, verify the format (channels, frequency, bit depth)
- If necessary, convert it to a Cloud friendly format (1 or 2 audio channels, 16 bit depth, 16 Khz frequency)
- Submit the file to Cloud STT service
- Move the original input file from Input Folder to a "Processed" folder, adding timestamp to the filename
- Save the audio transcript from cloud to a recognizable .txt file in the same "Processed" folder of the windows machine
- To show the last transcription done, write a fixed txt file with the last result (For most usage, this is useless)
I was used to write Windows Background Service in the past, in the banking industry, to process text records file.
So I approached the same way, but using a more modern approach with .Net Core 5.0 . I started reading the documentation about how to develop a windows background service and the I started coding.
The first cool thing about the new BackgroundService .Net Core implementation, is that you can easily run the code within Visual Studio without issues.
The built package can then be run from command line or installed as a service.
In the past was a nightmare to debug windows services. You were required to write the business logic in DLLs, test the service in exe wrapper, or debug attaching to an running service. Now things are really better.
Regarding the Visual Studio solution, when you want to package the binaries, you can use the Project -> (right-mouse click) -> Publish -> Publish to Folder feature, to create a portable version.


You can create a self-contained exe package, with all the required .Net core file embedded (portable). You can run this service even on a windows machine without .Net Core framework (obviously, the file has a huge size).

If you want a lighter version and .net Core framework is installed on target machine, use the classic Binary Release created during compilation.

We are talking about a 126 MByte exe vs a 0,12 MBytes file ...
Libraries used recap
.Net core 5.0
As mentioned, this project has been built with .Net Core 5.0 framework.
Please refer to (https://docs.microsoft.com/en-us/dotnet/core/extensions/windows-service) for information on developing .Net Core 5.0 Background services.
Microsoft Cognitive Services Speech SDK
To interact with cloud Speech services, this software use the c# Speech SDK library from Microsoft.
For further info and documentation,go to (https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-sdk)
NAudio
Due to a specific requirements, processing and transforming wave files BEFORE the submission to the Azure Cloud Speech Services, the service make use of the library NAudio, that sadly requires the service to be built/targeted on Windows platform only.
(https://github.com/naudio/NAudio)
Folders structure
The below structure is only an example. Each folder can be in a different path in your machine.
root
│
└───inputFolder
[The folder where you insert wave files to be elaborated]
└───channelSplitFolder
[A temporary working folder. When a wave file has more than 2 channels or it has been recorded at a frequency higher than 16 Khz, here you will find the downsampled version and individual channels (i.e. a 4 channels wave file will be splitted in 4 different mono file)]
└───errorFolder
[if something unexpected happens during the process, the wave file is moved from inputFolder to errorFolder, to avoid reprocessing of the file]
└───outputFolder
[at the end of processing wave file is moved from the input folder in the output folder renamed with a timestamp. A corresponding txt file is created along the wave file with the transcription]
Code Highlights
I use the NAudio library to open incoming file and detect if it contains more than 2 channels
var reader = new WaveFileReader(sourcePath);
if (reader.WaveFormat.Channels > 2) then ...
If this is the case, I used this routine to write each channel in a separate, mono, file:
var writers = new WaveFileWriter[reader.WaveFormat.Channels];
for (int n = 0; n < writers.Length; n++)
{
var format = new WaveFormat(reader.WaveFormat.SampleRate, 16, 1);
string combinedPath = Path.Combine(channelSplitFolder, string.Format($"channel-{n + 1}.wav"));
writers[n] = new WaveFileWriter(combinedPath, format);
}
float[] buffer;
while ((buffer = reader.ReadNextSampleFrame())?.Length > 0)
{
for (int i = 0; i < buffer.Length; i++)
{
// write one sample for each channel (i is the channelNumber)
writers[i].WriteSample(buffer[i]);
}
}
for (int n = 0; n < writers.Length; n++)
{
writers[n].Dispose();
}
the same approach to verify frequencies higher than 16 kHz and, in case, downsample to 16 kHz:
reader.WaveFormat.SampleRate > 16000
In this case, with the help of stackoverflow, I wrote this routine
string convertedStreamFilename = Path.Combine(Path.GetDirectoryName(file), Path.GetFileNameWithoutExtension(file) + "-16KHz.wav");
using (var wavConverterReader = new WaveFileReader(file))
{
var newFormat = new WaveFormat(16000, 16, 1);
using (var conversionStream = new WaveFormatConversionStream(newFormat, wavConverterReader))
{
//Replace original file
WaveFileWriter.CreateWaveFile(convertedStreamFilename, conversionStream);
}
}
And this block is the core of the SDK call to Speech Services
//Perform STT
using AudioConfig audioConfig = AudioConfig.FromWavFileInput(STTSourcePath);
speechConfig.SpeechRecognitionLanguage = sourceLanguage;
speechConfig.EnableAudioLogging();
speechConfig.SetProperty(PropertyId.Conversation_Initial_Silence_Timeout, "5");
ResultReason STTResult;
using (var recognizer = new SpeechRecognizer(speechConfig, audioConfig))
{
_logger.LogInformation(String.Format("Sending file {0} to Azure STT Service", Path.GetFileName(STTSourcePath)));
//Do the real STT Job on cloud
var result = await recognizer.RecognizeOnceAsync();
STTResult = result.Reason;
if (result.Reason == ResultReason.RecognizedSpeech) {
_logger.LogInformation("Moving file from {0}\r\nto {1}", sourcePath, destWavPath);
_logger.LogInformation($"RECOGNIZED STT: Text={result.Text}");
//Dumping Json Response file to History Directory
await File.WriteAllTextAsync(destSttTxtPath, result.Text);
//Dumping Json Response file to fixed destination directory (This one is not really required, but introduced for a specific need)
await File.WriteAllTextAsync(singleTxtTranslationTargetFile, result.Text);
}
//Avoid File locking errors
recognizer.Dispose();
}
Please note that you can set the source language with SpeechRecognitionLanguage property or set the Initial Timeout inside the audio file with the Conversation_Initial_Silence_Timeout setting
How to Create an Azure Speech service resource
Azure gives you 5 hours of free Speech-To-Text each month.
To create your Speech Service resource, follow these steps (Prerequisite, you have at least a trial Azure Subscription):
- Visit this URL, https://portal.azure.com/#blade/HubsExtension/BrowseResource/resourceType/Microsoft.CognitiveServices%2Faccounts
- Press the button "Add Speech Service"
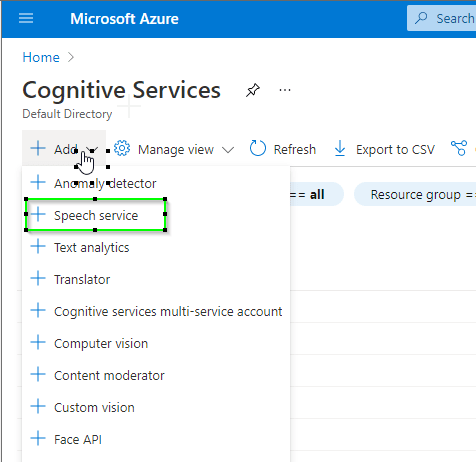
- Fill the values as in the below example. Name is whatever you want. Subscription is your Azure Subscription. Location is the Azure region where your service will be hosted. Pricing Tier can be F0, the free one, but you can create only one free resource for each subscription. S0 is the paid one, but you have always 5 free hour before paying. As Resource Group select an existing one or create a fresh resource group right here.
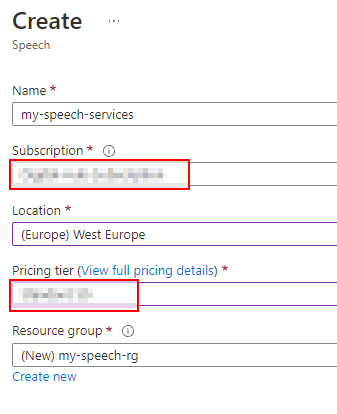
- Press "Create"
- At the end of deployment, press “Go To Resource”, or open the newly created resource from the specific Resource Group
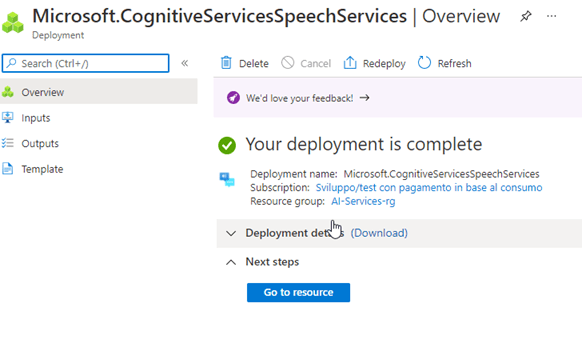
- Read the Key to be able to use the service. Remember, this is the setting to be placed in the Application Settings file, BEFORE starting the service

If you better prefer, take a look at the official Microsoft Guide to create the Speech service (https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/overview#create-the-azure-resource)
Once you have created your speech resource, you can play with the Speech Studio. Speech Studio is a great Web GUI where you can experiment with all Speech related cloud service.
Speech Studio can be reached at (https://speech.microsoft.com/).
For an overview of speech studio, visit (https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-studio-overview)
Application Settings
Before starting the service, please change the application settings, at your convenience.
Open appsettings.json with yor favourite editor.
Keys description:
AzureSTTService - Key : Place your speech service secret key - See the "How To Create Azure Speech service resource section"
AzureSTTService - Region : Set the region where you provisioned the service (i.e.= westeurope)
AzureSTTService - SourceLanguage : Set the language to transcribe from. For a complete list goto column Locale (BCP-47) at (https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support#speech-to-text)
DO NOT FORGET THE DOUBLE SLASHES IN THE PATHS
Folders - InputFolder : The folder where you insert wave files to be elaborated (i.e c:\stt\inputFolder)
Folders - OutputFolder : Where you will find original file wav and txt transcription renamed with a timestamp

Folders - ErrorFolder : If any error occur, file are moved here from the input folder
Folders - ChannelsSplitFolder : Post-Processed audio file (stereo or more channels, frequencies higher than 16 Khz) are placed here for convenience. Directory is cleaned for each transcription.

Folders - SingleTxtTranslationTargetFile : A path to a specific txt file. It will always contain the latest transcription and will be overwritten by each processing iteration (i.e "c:\stt\outputfolder\last_transcription.txt")
Installation
Once the project is built (or published to a folder), copy the binaries output and place them in a directory of your choice (ex: "c:\Program Files\STTCloudservice")
To install it as a windows service
- open a powershell as administrator
- run the following command, replace binpath with your binaries folder
sc.exe create "Azure Cloud STT Service" binpath=C:\stt-service\AzureCloudSTTService.exe
After installation, the service Startup mode is Manual. If you want you can change it to Automatic, so the software can start autonomously at each reboot.
You can do it from the Windows Services GUI, or via command line
sc.exe config "Azure Cloud STT Service" start=auto
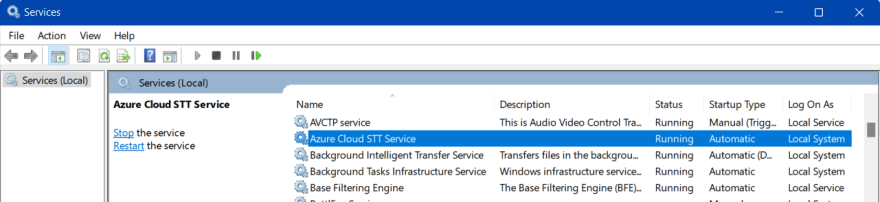
Interact with the windows service
You can start and stop service from the Services Consoles (WIN+R then launch "services.msc")
Alternatively, from the command line
- Start Service
sc.exe start "Azure Cloud STT Service"
- Stop Service
sc.exe stop "Azure Cloud STT Service"
Uninstall
Before uninstall, please stop the service using above command.
then launch
sc.exe delete "Azure Cloud STT Service"
Logging
Classic logging is used, you can find any trace in the windows events consolle.
To open (WIN+R -> eventvwr.msc -> OK)
or search Event Viewer in the Start Menu
The source code of solution presented in this article,is available at
my GitHub repo pageA portable release, no .Net Core installation required, can be obtained in the GitHub Release page





Top comments (0)