
As far back as the early 2000s, REST has been the architectural style of choice when creating Application Programming Interfaces (or APIs). To keep up with the growth and evolution of web applications, product and engineering teams must create new features and iterate rapidly. To meet these demanding app requirements, something different was needed — something that would be scalable and aligned with how data is created and consumed online today. Acknowledging some of these critical requirements, Facebook developed the Graph Query Language (or GraphQL) in 2012.
GraphQL and REST, like any other technologies, have their pros and cons. Depending on what you're building, one could be a better fit than the other. Let’s examine some of the core differences between GraphQL and REST, compare their strengths and weaknesses, and get some insight into when one should be used over the other.
Benefits of working with REST APIs
REST (Representational State Transfer) is an architectural style for developing web services. RESTful web services typically fulfill these five constraints:
- Uniform interface - Each resource in a REST API is assigned a unique identifier (URI). Clients can read the resource state from REST endpoints, as well as mutate (create, update, or delete) the resource object through these endpoints.
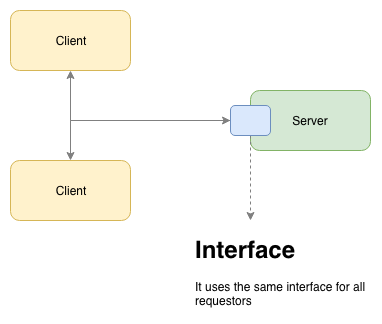
- Client-server - The client and server don’t depend on each other to progress, so they can work independently and only communicate when needed. As an example, the client doesn’t need to worry about the mechanics of how an object is stored on the server. So long as the contract interface between the client and the server remains unchanged, both servers and clients can be upgraded or even replaced independently without impacting functionality.

- Stateless - REST APIs make client-server interactions stateless, allowing each HTTP request from a client to contain all the information needed to process it. The information is encoded as part of the URI, query-string parameters, body of the request, and request headers.

- Cacheable - With the growth of the internet, performance has gained importance and made caching crucial across web infrastructures. By caching data and responses, you're effectively storing copies of frequently accessed data along the request-response path, reducing client-server request latency, cutting network bandwidth, and reducing server load. When a user requests a resource, the request passes through a cache or series of caches (such as a local cache, proxy, or reverse proxy). If any of those caches have a fresh copy of the resource, the user will be served that copy as a response. In REST, caching should be used when applicable, and it can be enabled on the server or client-side.

- Layered systems - RESTful systems have a multilayered structure in which each layer operates independently and interacts only with the layers directly connected to it. By separating the deployment of APIs from the storage of the data that these APIs touch, we get to be far more flexible with our architecture. For example, imagine a client accesses an API endpoint on Server A, and data is written to Servers B and C. No changes to the client are required because the API contract is between the client and Server A, not the other components (Server B and C). When communicating with the server, the client cannot tell whether it is directly connecting to the server or whether there are any intermediaries along the way.

This architecture offers a number of benefits, including:
Simplicity and predictability - Using RESTful APIs requires minimal learning since they are related to HTTP and client-server architectures, which many developers are already familiar with.
Scalability - The decoupling of client and server in RESTful API designs greatly simplifies the scaling of applications. Clients and servers can scale independently of each other.
Performance - REST APIs leverage the built-in caching mechanism of HTTP to return cached responses faster.
Wide adoption and support - In the 2020 State of the API report, 82% of API practitioners reported they used the REST-based OpenAPI specification.
Limitations when working with REST APIs
As discussed above, one of the main characteristics of REST is that data is accessed through unique endpoints called URIs. When a request to this endpoint is made, all data from that endpoint is returned, via REST, in a fixed data structure. As time has passed and applications have changed, REST APIs' greatest strength has also turned into its greatest weakness. Developing an API that can accommodate the different needs of each client is extremely difficult. Due to this, REST APIs are inefficient and have several limitations :
Overfetching - REST APIs typically return a lot more data than the client actually needs. The clients usually filter out the unnecessary data, since this information is rarely useful. In most cases, this process is time-consuming and laborious, especially if it involves multiple API calls. If you want your API to request less data in the first place, your backend team will need to implement this change, and it could risk breaking other applications that are expecting the data to be present.
Underfetching - This scenario is exactly the opposite of the above-mentioned scenario. In this case, the server returns less data than what the client needs. To get all the data they need, the client must send multiple requests and stitch the responses together. Imagine, for example, that you want to include additional data in your API to support a new module within your application, but that data isn't available within the same endpoint. The new API request must be made to a different endpoint in order to access all the data, and this would need additional network calls.
In both examples above, we see how this fixed data structure is inflexible and its inefficiency can significantly slow down development. With these problems in mind, Facebook developer Lee Byron developed a solution that allows users to request only the data they need - no more, no less. That was the birth of GraphQL.
Benefits of GraphQL vs REST
GraphQL is a query language built for solving common API problems, many of which were described above in the context of REST.
Below is a comparison of REST vs GraphQL:
| REST | GraphQL | |
|---|---|---|
| Data Fetching | Data is gathered by accessing individual URIs. This simplifies fetching data, however it can lead to situations like overfetching and under fetching that require additional steps to get the exact data a client is looking for. | As a query language, it’s much more flexible in how it fetches data from the exposed endpoint. Clients can request data from several resources using a single request, as well as specify the exact data that they need, avoiding REST’s fetching issues. |
| Web Caching | REST is done over HTTP and thus uses web caching that APIs can benefit from for increased performance. | Since it does not abide by HTTP specifications, GraphQL does not use native caching. It is up to the developer to ensure caching is set up. Third-party software can help bridge this gap. |
| File Uploading | Supports uploading of numerous file types | Not supported natively today, but other external libraries are available. |
| Technology Ramp Up | A shorter learning curve since REST APIs go hand-in-hand with understanding HTTP and client-server architectures that many are already familiar with. | As it is a new query language, GraphQL requires more of a ramp up period than REST. Users that have not worked with it may spend more time and resources getting used to the system. |
Limitations of working with GraphQL
GraphQL provides flexibility that traditional REST APIs cannot, but has some limitations that developers should be aware of. GraphQL does not have built-in caching capabilities to retrieve data from the browser or mobile cache. RESTful APIs use a built-in HTTP caching mechanism to return cached results faster. GraphQL requests always return HTTP 200 (OK) status codes, whether they “fail” or not. As a result, it can become complicated for developers to distinguish between a failure or successful API operation. To gain a deeper understanding of what is going on in the stack, they will need additional tools.
Native GraphQL in a serverless database
Fauna is a flexible, developer-friendly, transactional database delivered as a secure and scalable cloud API. Thanks to its native GraphQL support, it allows applications to access data through GraphQL APIs without even needing to interact with a traditional server. You never have to worry about database provisioning, scaling, sharding, or replication. Fauna has an extensive hub of GraphQL documentation, ideal for novices and experts alike.
Sign-up for free
The data API for modern applications is here. Sign-up for free without a credit card and get started instantly.Sign-up now
Quick start guide
Try our quick start guide to get up and running Fauna and GraphQL, in only 5 minutes


Top comments (1)
it seems to me that you do not distinguish between
RESTandRESTful. also do not distinguish protocol from architecture.