
This article explains how you can reduce complexity, develop features faster, and make your engineering teams more efficient using Apollo Federation and Fauna.
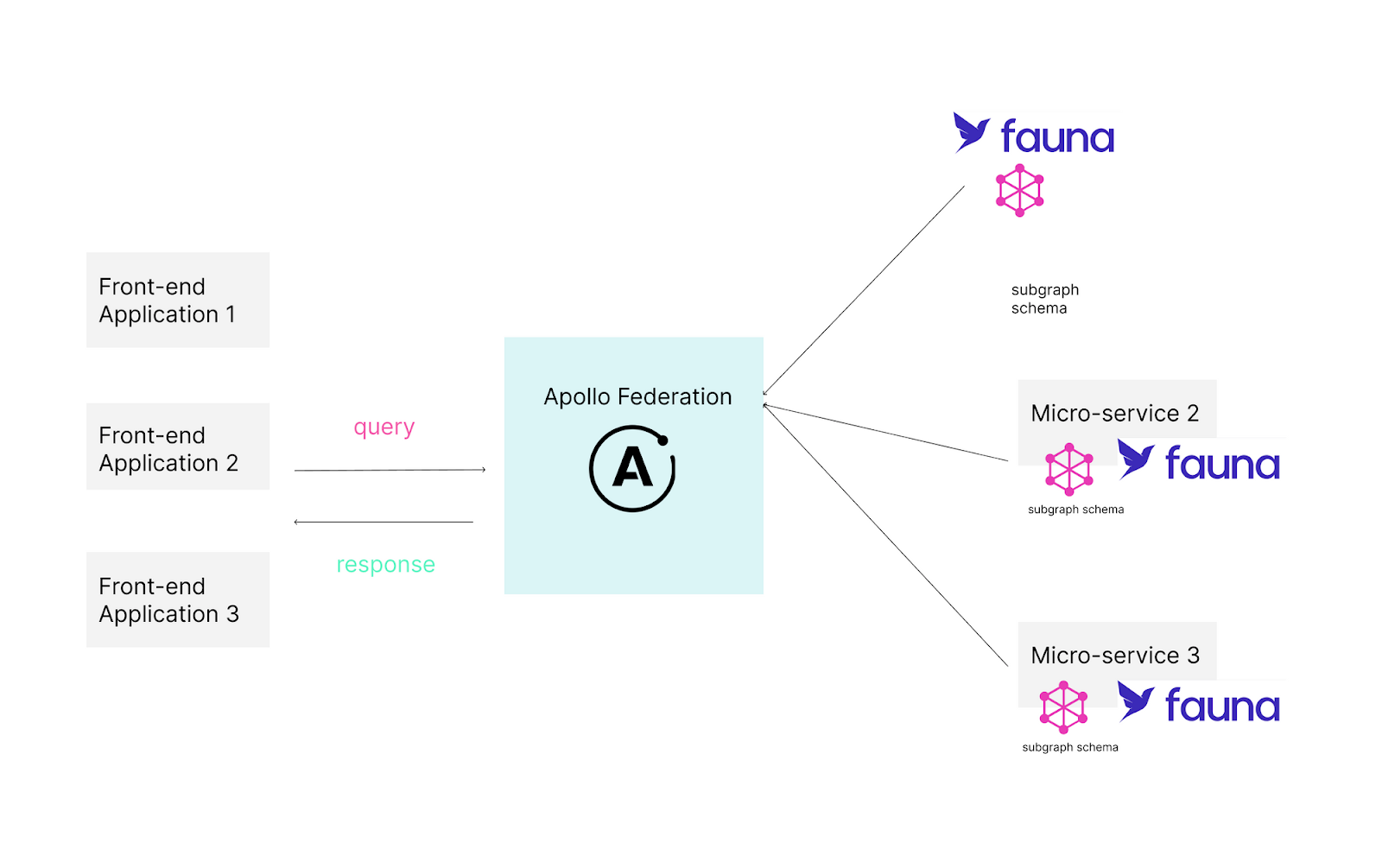
Apollo Federation is designed for implementing GraphQL in a microservice architecture. On the other hand, Fauna is a distributed serverless document-relational database delivered as an API. Fauna's native GraphQL API allows engineers to directly integrate it as a subgraph in Apollo Federation or use it as a database for individual microservices.
Apollo Federation combined with Fauna improves developer experience and increases productivity, solving the problem of schema stitching and addressing pain points such as coordination, separation of concerns, and brittle gateway code.
Challenges of modern application development and how to solve it
Many organizations find it challenging to deliver products and features with velocity. More and more organizations are investing massive amounts of resources to make their infrastructure resilient and flexible. Yet, scattered microservices, versioned REST endpoints, and complex database management systems result in slow delivery of features/product development.
GraphQL revolutionized the way organizations build applications. GraphQL, open-sourced by Facebook in 2015, helps engineering teams integrate their array of REST APIs and microservices into a unified schema that frontend developers can query, fetching only the data required to power an experience while being agnostic to the data source. Traditional REST APIs lead to under or over-fetching data.
Fast forward to 2022, and the complexity of modern APIs and applications has grown exponentially. Running everything through a single GraphQL server (read: monolith) with multiple teams rapidly contributing changes creates a bottleneck.
What if there was a way for each microservice to have its own graph that could be seamlessly composed into a supergraph? Enter Apollo Federation. With Apollo Federation, you can build a declarative, modular GraphQL architecture.
A supergraph is composed of smaller graphs called subgraphs, each with its own schema. Teams can evolve their subgraphs independently, and their changes will be automatically rolled into the overall supergraph, allowing them to deliver autonomously and incrementally.
Your application data layer (database) is a critical part of your application architecture. Fauna is a database designed with modern applications and GraphQL architecture in mind. Fauna can seamlessly integrate as a subgraph in your Apollo Federation supergraph.
Moreover, Fauna's custom GraphQL resolvers gives the engineers the ability to turn the database into a fully-fledged microservice. You can learn more about Fauna's GraphQL capabilities in the official docs.
Fauna is a database that gives you the ability to form your data from a declarative GraphQL schema while giving you the complete freedom to implement your resolver functions if you have to. The document-relation model of Fauna also makes it flexible for evolving applications. Fauna combines the simplicity of NoSQL, without sacrificing the ability to model complex relationships.
Fauna’s flexibility and GraphQL native API combined with Apollo Federation allows engineers to build robust solutions faster with more flexibility and less code.
Let’s walk through a few different approaches for how to integrate Apollo Federation and Fauna, depending on your needs and existing architecture.
Application architecture
Microservices and Fauna (Traditional subgraphs)
Having a separate database for each of your microservices is a common practice. You can use the Fauna database as your data layer in each microservices. Your services can connect to Fauna with any of the supported drivers.

This is a traditional microservice-based architecture. Each microservice is a subgraph in this case, and you compose these subgraphs into a supergraph using Apollo Federation.
Using Fauna-hosted GraphQL endpoints as subgraphs
Suppose your product is primarily frontend focused (Jamstack or serverless-native) and you are not ready to commit to multiple microservices yet but want separation of concerns in the data layer. In that case, this architecture pattern is for you.

In this pattern, you will ideally have three Fauna databases. Each database has its GraphQL schema. Each of these schemas is then combined into a Federation supergraph.
Hybrid model
In the hybrid model, you combine the two approaches discussed earlier. This is ideal when you are rapidly scaling your product and solutions.
Getting started with Fauna and Apollo Federation 2
Let’s create a federated e-commerce solution using Apollo Federation and Fauna. In this example app, we will combine a Fauna GraphQL subgraph that includes information about shops and products with one from Apollo that provides locations.
You can find the complete code in this repository.
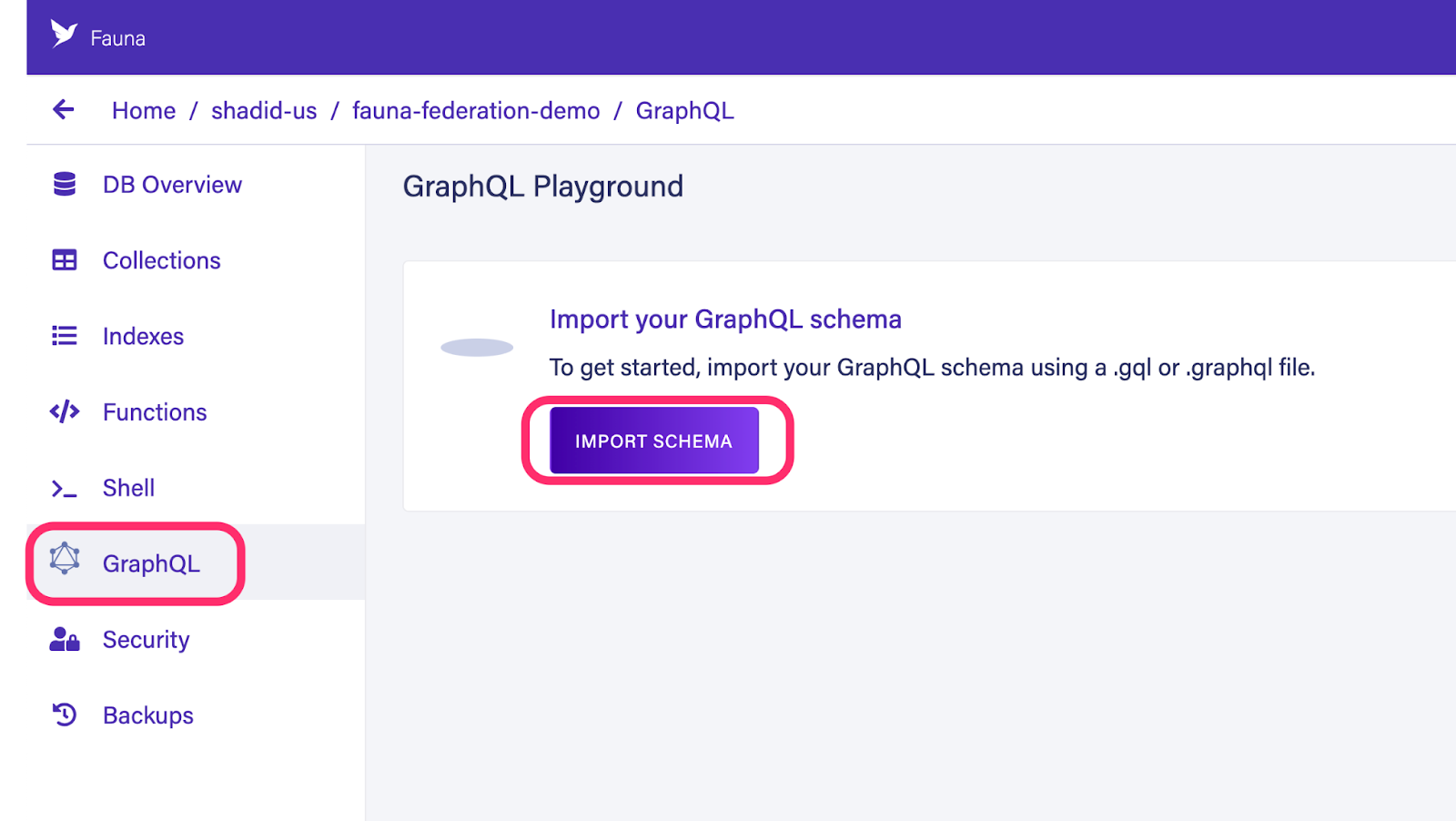
Configure Fauna
Head over to dashboard.fauna.com and create a new database. Create a new GraphQL schema. You can use the following schema.
type Shop {
name: String!
description: String!
coverImg: String!
products: [Product]! @relation
ownerID: String!
}
type Product {
name: String!
description: String!
price: Float!
category: String!
imageUrl: String
shop: Shop! @relation
}
type Query {
products: [Product]
}
Upload the schema to your Fauna database. Select the GraphQL option in your Fauna dashboard then select import schema.
Once you upload the schema your collections in your database will be generated.
Add Records to Your Collection
Next, create some records in Fauna using the GraphQL playground. Run the following mutation to create a new product.
mutation CreateProduct {
createProduct(
data: {
name: "fender stratocaster",
description: "The world's greatest electric guitar",
price: 1255,
imageUrl: "guitar.png",
category: "Music",
}
) {
_id
name
}
}
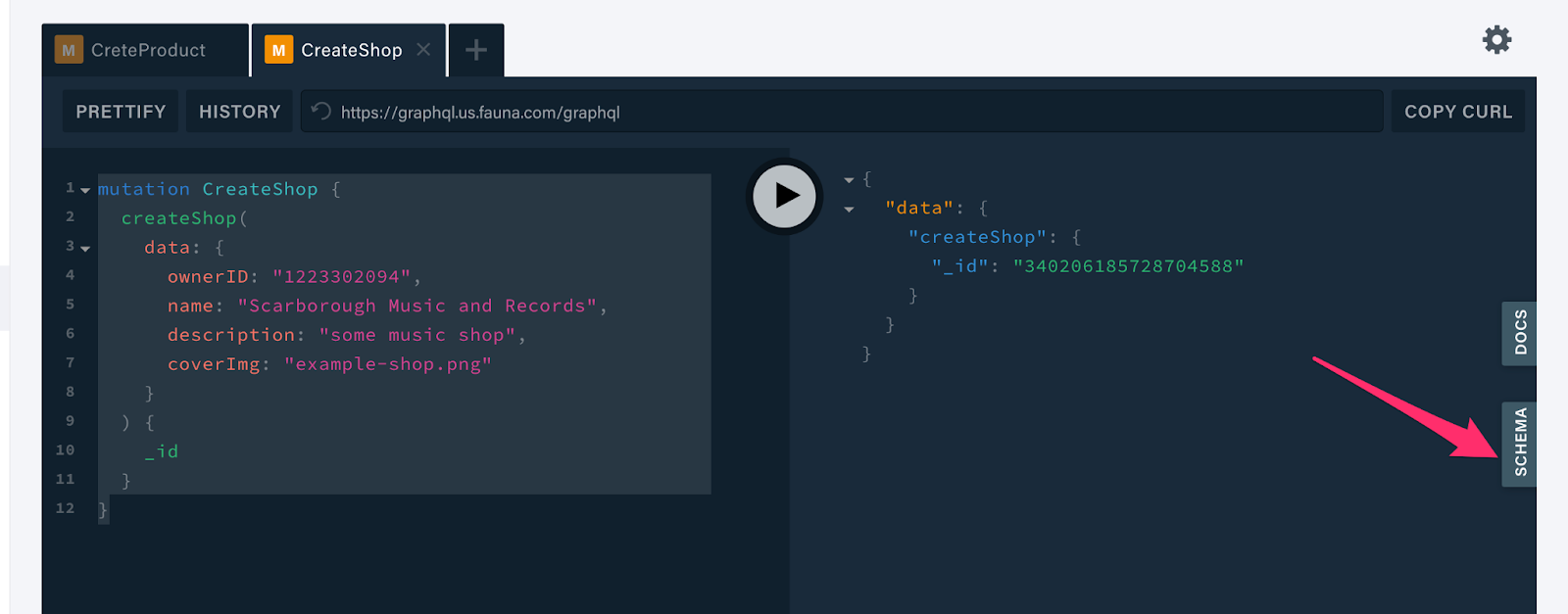
Next, create a Shop by running the following mutation.
mutation CreateShop {
createShop(
data: {
ownerID: "1223302094",
name: "Scarborough Music and Records",
description: "some music shop",
coverImg: "example-shop.png"
}
) { _id }
}
Integrate Fauna and Apollo
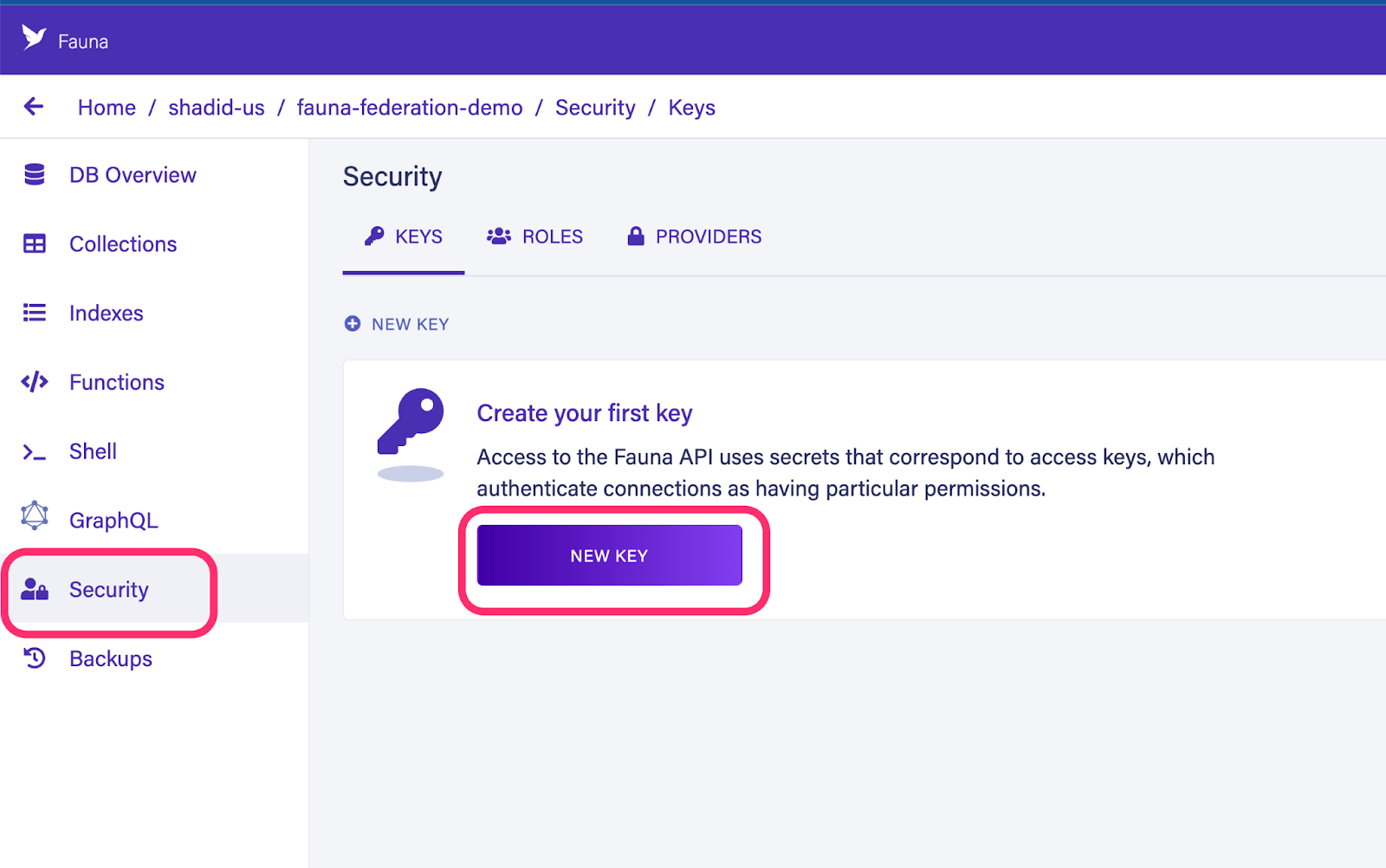
To integrate Fauna as a subgraph with Apollo Federation, you need the full GraphQL SDL from Fauna. You can download this from the Fauna GraphQL playground. Select schema from the playground and download the schema.

Next, navigate to security section and generate a new server key for your database.

Setting up supergraph
Create a new supergraph-config.yaml file. This file will contain the supergraph specification as well as subgraphs url and schema. Add the following code to your supergraph-config.yaml file.
federation_version: 2
subgraphs:
fauna:
routing_url: https://graphql.fauna.com/graphql`
schema:
file: ./fauna.graphql
locations:
routing_url: https://flyby-locations-sub.herokuapp.com/
schema:
subgraph_url: https://flyby-locations-sub.herokuapp.com/
Here, we are federating two subgraphs — one being Fauna and the other is a sample microservice from Apollo.
Run the following command to generate the supergraph
$ rover supergraph compose --config ./supergraph-config.yaml > supergraph.graphql
The previous command composes a supergraph schema from the specified subgraphs. The supergraph schema is saved in the supegraph.graphql file.
Local composition service with Apollo Gateway and Federation
Next, you create a local composition service. Create a new file called index.js and add the following code. This service acts as the gateway to your supergraph.
const { ApolloServer } = require('apollo-server');
const { ApolloGateway, RemoteGraphQLDataSource } = require('@apollo/gateway');
const { readFileSync } = require('fs');
const supergraphSdl = readFileSync('./supergraph.graphql').toString();
class AuthenticatedDataSource extends RemoteGraphQLDataSource {
willSendRequest({ request, context }) {
request.http.headers.set('Authorization', context.token);
}
}
const gateway = new ApolloGateway({
supergraphSdl,
buildService({ name, url }) {
return new AuthenticatedDataSource({ url });
},
});
const server = new ApolloServer({
gateway,
subscriptions: false,
context: ({ req }) => {
const token = req.headers.authorization || '';
return { token };
},
});
server.listen().then(({ url }) => {
console.log(`🚀 Gateway ready at ${url}`);
}).catch(err => {console.error(err)});
Make sure to install the required dependencies for this service. Run the following command to install the dependencies.
npm i apollo-server @apollo/gateway --save
Query your federated subgraph
Run the service with node index.js command. Navigate to http://localhost:4000/ in your browser. It will open up Apollo Studio.
You now have a federated graph up and running that uses Fauna as a subgraph. Run the following composed query to make sure everything is working correctly.
query FindProductByID($findProductByIdId: ID!) {
findProductByID(id: $findProductByIdId) {
_id
name
description
}
locations {
id
name
}
}
In the Variables field you will need to supply a product ID from your Fauna DB:
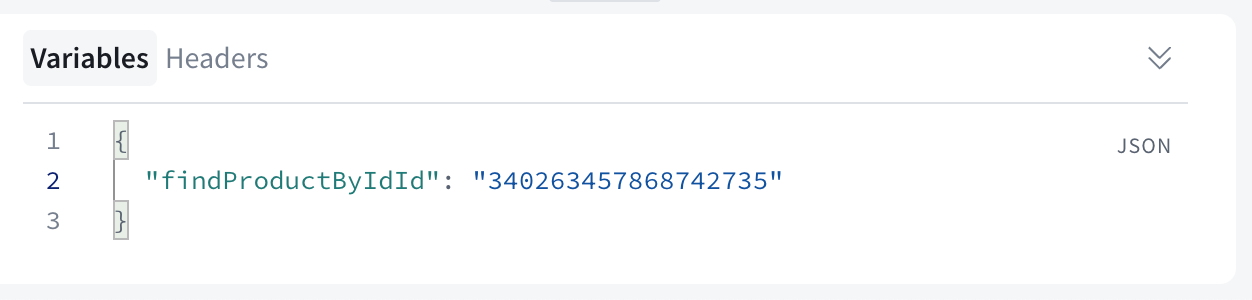
Once you’ve supplied your variables, make sure you pass in the authorization header. Use the Fauna secret key as the token for our authorization header.Your authorization header should be the following format Bearer fnAEukxxx:

The previous query returns a composed response from Fauna and locations microservice.
If you’d like to continue exploring federation with the subgraphs we created above, you can find the code for this example in this repository.
Conclusion
Combining Apollo Federation and Fauna allows engineers to be flexible, anticipate future API changes, and implement them easily without "breaking changes". In modern application development, engineering time is the most valuable resource. Apollo Federation and Fauna both focus on developer experience, helping engineers to be more productive and ship features faster at scale.
Have questions about using Fauna with Apollo Federation? Join the Fauna community channels and we would be happy to answer any questions you have. If you want to learn more about the Apollo Community forum. For more reference architecture and code examples with Fauna and Apollo, follow fauna labs on github.

Top comments (0)