
This tutorial will teach you how to build a serverless GraphQL service on the edge with Cloudflare Workers and Fauna — allowing you to take advantage of two edge serverless compatible technologies. Try the live demo here. You can find the complete code for this demo here.
Before diving into the code, let’s explore what edge serverless is and why it matters.
What is edge serverless?
Edge serverless is an infrastructural evolution of cloud serverless in which the computing resources that deliver serverless functions are located geographically closer to the end user.
Cloudflare Workers are, by default, edge serverless functions. They are globally distributed in a way that the end user always hits the nearest compute instance, lowering latency.
There are three main benefits of building your GraphQL service on edge serverless:
- You don't have to manage servers. Your application auto scales.
- You pay per usage for your infrastructure.
- Your app is faster. The computing resources that deliver serverless functions are located geographically closer to the end user which reduces latency for your application.
Why use Fauna as the database?
By default, Fauna is a serverless database with edge support. Like Cloudflare Workers, Fauna is distributed and the data gets replicated across different servers within a specified region group. When users request data, it always retrieves the data from the nearest geographical location reducing the latency.
You get the best of your edge infrastructure when your compute and database are both edge serverless compatible. In addition, Fauna is an easy-to-use database with zero administrative overhead.
Prerequisites
Make sure you have the following installed in your computer
- Node.js 16 or higher
- Cloudflare Wrangler CLI (install instructions)
Scaffolding a new Cloudflare Workers project
Run the following code to scaffold a new Cloudflare Workers project with Wrangler.
$ wrangler init <my-awesome-project>
The CLI wizard will walk you through some configuration questions and bootstrap your application. When it asks you Would you like to create a Worker select Yes and select Fetch handler option.
Open the src/index.ts file. You will see some code that reads as follows.
export interface Env {
}
export default {
async fetch(
request: Request,
env: Env,
ctx: ExecutionContext
): Promise<Response> {
return new Response("Hello World!");
},
};
Run wrangler dev and visit http://0.0.0.0:8787/. It should display “Hello World!”.
Setting up a GraphQL server in Cloudflare Workers
Run the following command to install all the dependencies.
$ npm i @graphql-yoga/common faunadb --save
Next, delete everything from index.ts file and add the following code. Here you are creating a simple GraphQL server with @graphql-yoga library.
import { createServer } from '@graphql-yoga/common'
const server = createServer({
schema: {
typeDefs: /* GraphQL */ `
type Query {
hello(msg: String): String
}
`,
resolvers: {
Query: {
hello: async (_, { msg }) => {
return `Hello, ${msg}`
}
},
},
},
})
server.start()
Run wrangler dev and visit http://0.0.0.0:8787/ in your browser. In your browser, a GraphQL playground will open.
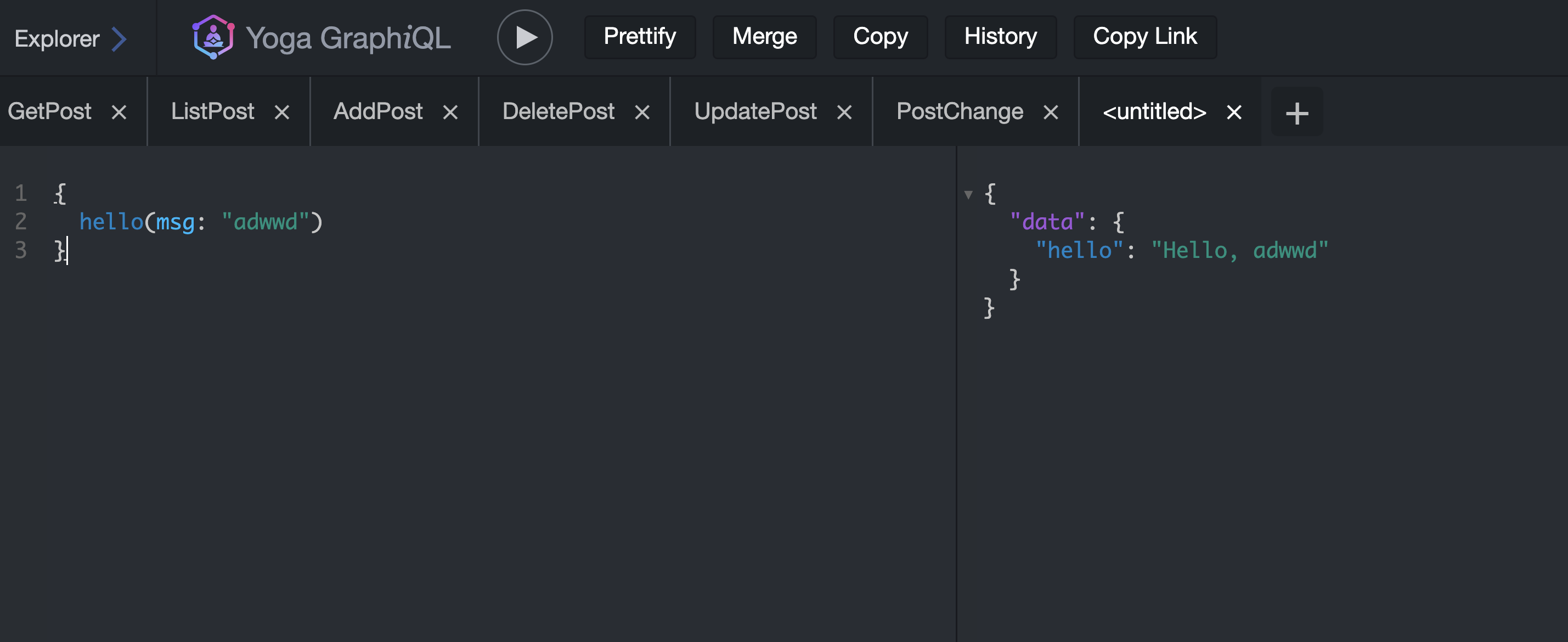
Make the following query in GraphQL playground to make sure everything is working as expected.
{
hello(msg: "adwwd")
}
Result:
{
"data": {
"hello": "Hello, adwwd"
}
}
Next, let’s go ahead and replace the GraphQL schema with something more practical. We want CRUD (Create, Read, Update and Delete) operations in our GraphQL service. Make the following changes to the schema to add CRUD.
import { createServer } from '@graphql-yoga/common'
const server = createServer({
schema: {
typeDefs: /* GraphQL */ `
type Post {
id: ID!
title: String!
content: String!
}
type Query {
getPost(id: ID!): Post
listPosts: [Post]!
}
type Mutation {
addPost(input: PostInput): Post
deletePost(id: ID): Boolean
updatePost(id: ID, input: PostInput): Post
}
type Subscription {
onPostChange(id: ID): Post
}
input PostInput {
title: String
content: String
}
`,
resolvers: {
Query: {
},
},
},
})
server.start()
You now have your schema ready. However, you cannot execute these queries and mutations since the resolvers are not yet implemented.
Before we can implement the resolver functions let’s go ahead and set up our database. We are using Fauna as our database.
Creating a Fauna database
Sign up for a free forever Fauna account and create a new database.
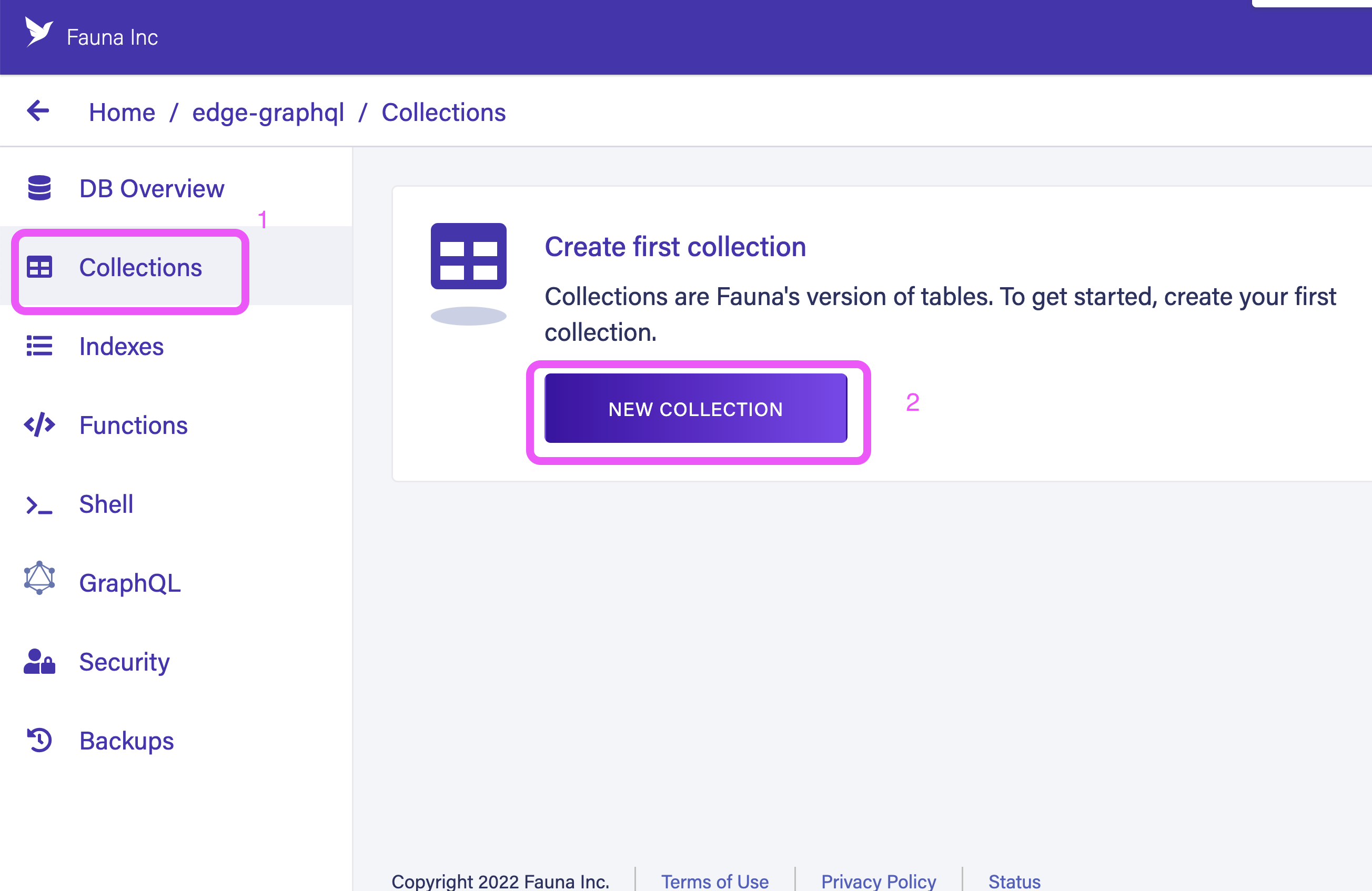
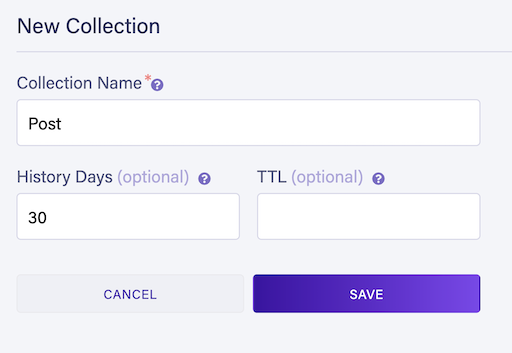
Create a new collection called Post.
Next, go over to the Security tab and create a new server secret for your database.
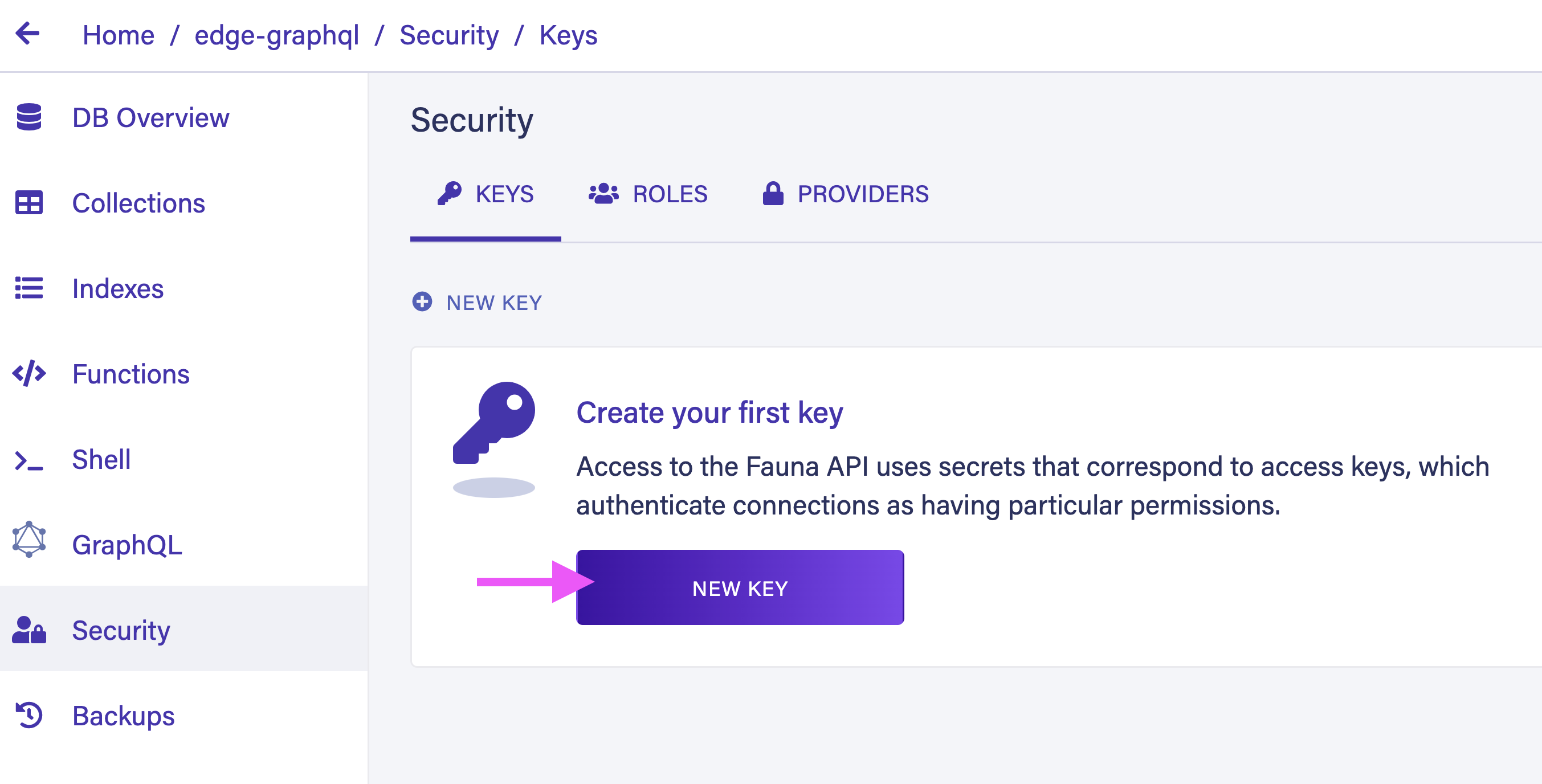
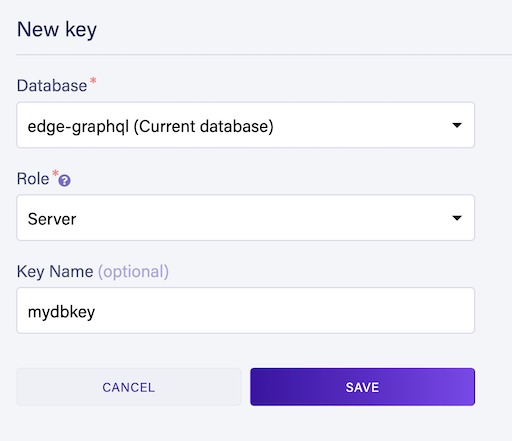
Save the generated database secret. Make sure you do not reveal this secret in your version control.
Back in the code, add the Fauna database key and domain in your wrangler.toml file as follows.
# wrangler.toml
name = "edge-graphql"
main = "src/index.ts"
compatibility_date = "2022-09-23"
compatibility_flags = ["streams_enable_constructors"]
node_compat = true
[vars]
FAUNA_SECRET = "fnAxxx...."
FAUNA_DOMAIN = "db.us.fauna.com"
Next, create a new file src/db.ts and add the following code. In the following code snippet, you initialize the Fauna database.
import * as faunadb from "faunadb";
export const q = faunadb.query as any;
declare const FAUNA_DOMAIN: string;
declare const FAUNA_SECRET: string;
export const faunaClient = new faunadb.Client({
domain: FAUNA_DOMAIN,
secret: FAUNA_SECRET,
});
Implementing resolvers
Add post (Mutation)
First, you need to enable node_compat mode for Cloudflare Workers since you will use modular JavaScript. Go to wrangler.toml file and add the following line.
name = "ggop"
main = "src/index.ts"
compatibility_date = "2022-09-25"
node_compat = true
[vars]
...
Inside the src/index file, under resolvers field, add a new resolver function addPost as follows.
import { createServer } from '@graphql-yoga/common'
import { faunaClient, q } from './db'
const server = createServer({
schema: {
typeDefs: /* GraphQL */ `
...
`,
resolvers: {
Query: {
},
Mutation: {
addPost: async (parent, { input }) => {
const post: any = await faunaClient.query(
q.Create(q.Collection("Post"), { data: input })
);
return {...post.data, id: post.ref.id};
},
}
},
},
})
server.start()
You use the Fauna driver functions in the resolver to add a new post to the database. If you are new to Fauna, the documentation for how to perform CRUD operations in Fauna.
Run wrangler dev in your terminal. Visit http://localhost:8787/ to interact with your GraphQL playground. Create a new GraphQL mutation to add post.
mutation AddPost {
addPost(input: {
title: "New Tittle"
content: "Another Post"
}) {
id
title
content
}
}
# Result
{
"data": {
"addPost": {
"id": "343885948385230924",
"title": "New Tittle",
"content": "Another Post"
}
}
}
Go back to the Fauna dashboard and notice that under Post collection a new record is generated.
Update and delete post (Mutation)
Similarly, you can create update and delete resolvers to update and delete posts. Make the following changes to your code.
// ...
const server = createServer({
schema: {
typeDefs: /* GraphQL */ `
// ...
`,
resolvers: {
Query: {
},
Mutation: {
addPost: async (parent, { input }) => {
const post: any = await faunaClient.query(
q.Create(q.Collection("Post"), { data: input })
);
return {...post.data, id: post.ref.id};
},
deletePost: async (_, { id }) => {
await faunaClient.query(
q.Delete(q.Ref(q.Collection("Post"), id))
);
return true;
},
updatePost: async (_, { id, input }) => {
const post: any = await faunaClient.query(
q.Update(q.Ref(q.Collection("Post"), id), { data: input })
);
return {...post.data, id};
}
}
},
},
})
server.start()
Run updatePost and deletePost mutation from your GraphQL playground to make sure everything is working as expected.
Get post and post list (Query)
Next, add the listPost and getPost resolver functions under Query.
import { createServer } from '@graphql-yoga/common'
import { faunaClient, q } from './db'
const server = createServer({
schema: {
typeDefs: /* GraphQL */ `
//...
`,
resolvers: {
Query: {
getPost: async (_, { id }) => {
const post: any = await faunaClient.query(
q.Get(q.Ref(q.Collection("Post"), id))
);
return {...post.data, id};
},
listPosts: async () => {
const posts: any = await faunaClient.query(
q.Map(
q.Paginate(q.Documents(q.Collection('Post'))),
q.Lambda((x: any) => q.Get(x))
)
);
return posts.data.map((post: any) => ({...post.data, id: post.ref.id}));
}
},
Mutation: {
// ...
}
},
},
})
server.start()
In the GraphQL playground try out the queries and make sure that everything is working as expected.
Implementing subscription
Cloudflare Workers support Streams API. Using this Streams API, you can send server-sent events (SSE) to your client. A client subscribes to the server in real-time through SSE.
Fauna also has a streaming API to listen to real-time database changes. Combining these two allows you to implement a complete serverless GraphQL subscription solution on edge.
Keep in mind that there is no WebSocket involved in this implementation.
Add a new subscription function called onPostChange to your resolvers field, as follows.
let stream: any = null;
const server = createServer({
schema: {
typeDefs: /* GraphQL */ `
`,
resolvers: {
Query: {
// ...
},
Mutation: {
// ...
},
Subscription: {
onPostChange: {
subscribe: async function* (_, { id }) {
let currentSnap: any;
let newVersion: any;
const docRef = q.Ref(q.Collection('Post'), id);
if(!stream) {
stream = faunaClient.stream.document(docRef).on('snapshot', (snapshot: any) => {
currentSnap = {
ts: snapshot.ts,
data: snapshot.data
}
}).start();
}
stream.on('version', (version: any) => {
newVersion = {
ts: version.document.ts,
data: version.document.data
}
});
let subscriptionTime = 0; // Terminate Subscription after 1000 seconds
while (subscriptionTime < 150) {
await new Promise(resolve => setTimeout(resolve, 2000, null));
subscriptionTime++;
if(newVersion && newVersion.ts !== currentSnap.ts) {
currentSnap = newVersion;
subscriptionTime = 0; // Reset Subscription Time
yield { onPostChange: { ...newVersion.data, id} }
}
}
await new Promise(resolve => setTimeout(resolve, 1000, null));
stream.close();
yield { onPostChange: 'Disconnected' }
}
},
},
},
},
})
server.start()
In the previous code snippet you use Fauna’s document streaming feature to subscribe to a database record. Whenever the record is updated or deleted, the Fauna client will be notified in real time. You can then emit this event to your GraphQL resolver.
Notice that this is an SSE implementation. This is why we have an iterator function that keeps track of a heartbeat (every two seconds) in the server. After five minutes you close the connection.
It is very important to close the connection to Fauna stream after a period of time, otherwise, you will be charged for the running connection.
Subscriptions can also be done through a Pub/Sub implementation. That way, you don’t have to consistently listen to database changes. Depending on your use case, a Pub/Sub layer might be more economical. However, Cloudflare Pub/Sub is currently in closed beta. Once this feature is generally available, we will create another tutorial using Cloudflare Pub/Sub and Fauna.
Where to go from here
Got questions about Fauna, Cloudflare, serverless, or GraphQL? Feel free reach out to us and ask questions in our forum or on our Discord.

Top comments (0)