Introduction:
Welcome to Chapter 3 of our exploration into the intricacies of PostgreSQL. In this chapter, we delve into the fascinating world of query processing, an essential component of database management. Understanding the inner workings of query processing is crucial for optimizing query performance, improving application responsiveness, and harnessing the full potential of PostgreSQL's powerful query engine.
Query processing becomes the most complex subsystem in the database, responsible for efficiently handling supported SQL queries. So, let's dive in and unravel the intricacies of query processing in PostgreSQL!
The chapter is divided into three parts to cover different aspects of query processing:
Part 1 (Section 3.1): This section serves as an introduction to query processing in PostgreSQL, providing an overview of the entire process.
Part 2 (Sections 3.2 - 3.4): This part delves into the steps involved in obtaining the optimal execution plan for a single-table query. Section 3.2 explains the process of estimating the cost associated with different execution plans, while Section 3.3 focuses on creating the plan tree. Additionally, Section 3.4 briefly describes the operation of the executor.
Part 3 (Sections 3.5 - 3.6): This part explores the process of obtaining the optimal plan for a multiple-table query. Section 3.5 describes three join methods: nested loop, merge, and hash join. Section 3.6 then explains the creation of the plan tree for multiple-table queries.
In this blog post, we will delve into Part 1 of Chapter 3 of the PostgreSQL official documentation, which provides an overview of query processing in PostgreSQL. Let's explore the key concepts and gain a better understanding of this important subsystem.
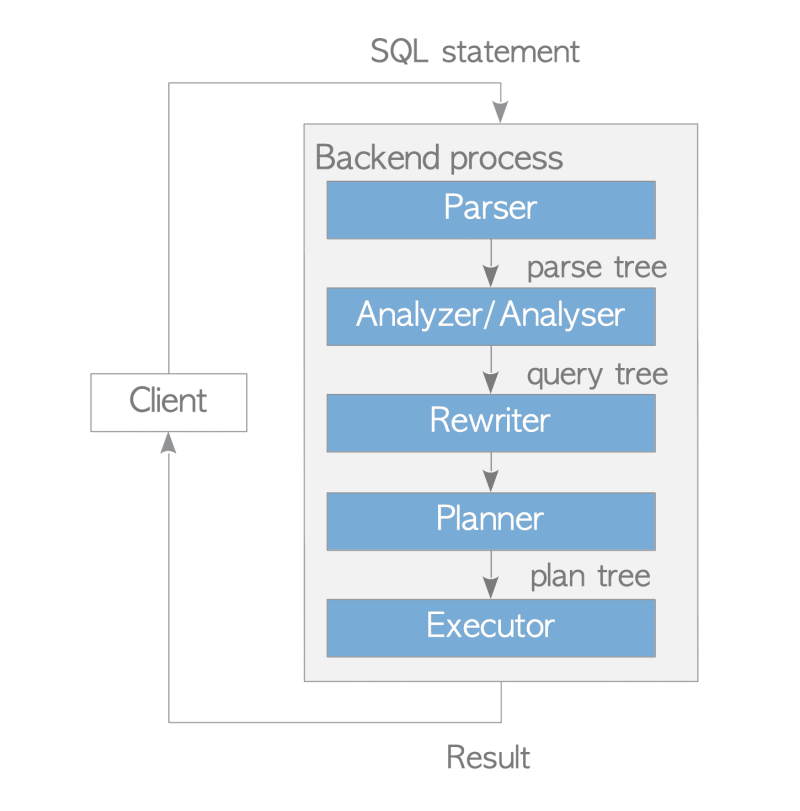
3.1 Query Processing Steps:
Query processing in PostgreSQL involves several crucial steps that collectively transform a user's query into an optimized execution plan. This blog provides a quick overview of the major query processing steps, including:
Parsing: The query parser analyzes the syntactic structure of the query, ensuring it adheres to the grammar rules of the PostgreSQL language. It checks for errors, validates the query structure, and creates a parse tree.
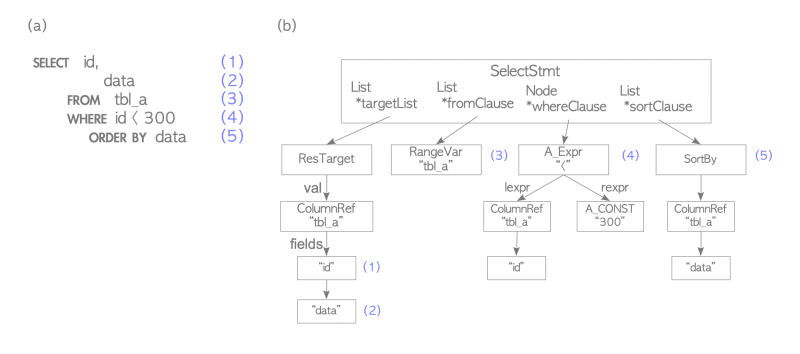
Fig. 3.2. An example of a parse tree -Fig 3.2(b) illustrates the parse tree of the query shown in Fig. 3.2(a)-.
Analyzer/Analyser:
The analyzer/analyser performs a semantic analysis of the parse tree generated by the parser. It validates the query's syntax, checks for the existence and correctness of table and column names, and resolves any ambiguities. This analysis results in the generation of a query tree.
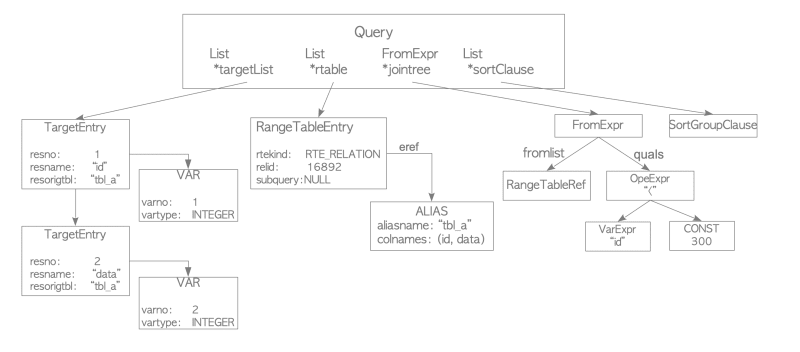
Fig. 3.3. An example of a query tree -Fig 3.3 illustrates the query tree of the query shown in Fig. 3.2(a) in the previous subsection-.
Rewriting: The query rewriter transforms the parse tree based on predefined rules and optimizations. It simplifies and expands the query, eliminates redundant operations, and resolves references to objects like tables and columns.
Planning: The query planner generates an optimal execution plan for the rewritten query. It explores various algorithms, access methods, and join strategies to determine the most efficient way to retrieve and process the requested data.
Execution: Finally, the query executor executes the optimized plan, retrieving and manipulating the data according to the plan's instructions. It interacts with the storage engine, retrieves data from disk or memory, and performs any necessary joins, aggregations, or sorting operations.
Understanding these query processing steps is crucial for diagnosing performance issues, identifying bottlenecks, and optimizing query performance in PostgreSQL.
Conclusion:
Part 1 of Chapter 3 in the PostgreSQL official documentation offers a valuable overview of query processing in PostgreSQL. We explored the five essential subsystems involved in efficiently executing SQL queries: parser, analyzer/analyser, rewriter, planner, and executor. Each subsystem plays a vital role in transforming an SQL statement into actionable results. Understanding how these components work together provides a foundation for optimizing query performance in PostgreSQL.
In our next blog post, we will dive into Part 2 of Chapter 3, where we will explore the steps involved in obtaining the optimal execution plan for single-table queries. Stay tuned for more insights into PostgreSQL's query processing capabilities!
Reference: Chapter 3 Query Processing

Top comments (0)