Introduction:
Welcome to Chapter 2 of our journey into PostgreSQL's inner workings (The Internals of PostgreSQL). In this chapter, we delve into the process and memory architecture of PostgreSQL, shedding light on the intricate mechanisms that make this powerful relational database management system tick. Understanding the underlying process architecture is crucial for optimizing performance and managing database clusters effectively. So, let's dive in!
2.1 Process Architecture:
PostgreSQL operates on a client/server model, employing a multi-process architecture that runs on a single host. The PostgreSQL server consists of several types of processes working together to manage a database cluster seamlessly. Let's take a closer look at these processes:

2.1.1 Postgres Server Process:
The postgres server process, formerly known as 'postmaster,' is the parent process responsible for managing all other processes within the PostgreSQL server. This process coordinates the lifecycle of other processes, accepts client connections, and facilitates communication between different processes.
When the pg_ctl utility is invoked with the start option, the postgres server process initializes and allocates a shared memory area in RAM. It also launches various background processes, replication-associated processes, and background worker processes, if necessary. The server process awaits incoming client connections and starts a backend process for each connection.
The postgres server process listens on a designated network port, with the default port being 5432. While it is possible to run multiple PostgreSQL servers on the same host, it is crucial to configure each server to listen on a unique port number (e.g., 5432, 5433) to avoid conflicts.
2.1.2 Backend Processes:
A backend process is initiated by the postgres server process and is responsible for handling queries issued by a connected client. Each backend process maintains a TCP connection with its associated client and manages all communication between the client and the PostgreSQL server.
When establishing a connection to a PostgreSQL server, clients must explicitly specify the database they intend to use. Each backend process operates exclusively on a single database, ensuring data integrity and isolation.
PostgreSQL supports simultaneous connections from multiple clients, allowing concurrent interactions with the server. The maximum number of allowed clients is controlled by the configuration parameter "max_connections," which has a default value of 100. By adjusting this parameter, administrators can manage the concurrency level and resource allocation for client connections.
It is worth noting that when many clients, such as web applications, frequently establish and terminate connections with the PostgreSQL server, it can impact performance. The overhead of connection establishment and backend process creation becomes significant in such scenarios, especially considering PostgreSQL does not natively implement connection pooling.
To mitigate this issue, it is common to employ a pooling middleware such as "pgbouncer" or "pgpool-II." These tools act as intermediaries between the clients and the PostgreSQL server, managing connection pooling and reducing the overhead of establishing new backend processes. Using connection pooling middleware can enhance the overall performance and scalability of the database server, particularly in scenarios with high connection turnover.
2.1.3 Background Processes:
In addition to the postgres server and backend processes, PostgreSQL employs various background processes to perform essential database management tasks. These processes handle critical operations such as vacuuming, which reclaims disk space by removing outdated or obsolete data, and checkpointing, which writes modified data from memory to disk. By offloading these resource-intensive tasks to dedicated background processes, the PostgreSQL server can ensure optimal performance for active client connections.
2.2 Memory Architecture:
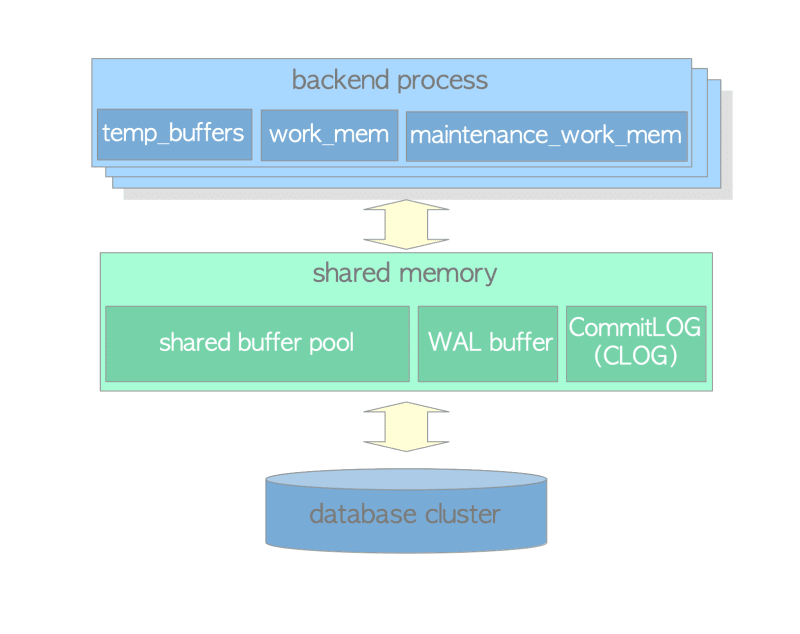
The memory architecture of PostgreSQL can be categorized into two main areas: local memory and shared memory. These areas serve distinct purposes and play vital roles in the efficient operation of the database system.
2.2.1 Local Memory Area:
Each backend process in PostgreSQL allocates a local memory area for its exclusive use during query processing. The local memory area is further divided into several sub-areas, each serving a specific purpose. Table 2.1 provides an overview of the major sub-areas within the local memory. You can explore the details of these sub-domains in depth in the chapters mentioned in the table

2.2.2 Shared Memory Area:
In addition to local memory, PostgreSQL also allocates a shared memory area when the server starts up. This shared memory area is utilized by all processes within the PostgreSQL server, facilitating efficient inter-process communication and data sharing. Similar to the local memory area, the shared memory area is divided into fixed-sized sub-areas, each serving a specific function.
Conclusion:
Understanding the process and memory architecture of PostgreSQL is essential for optimizing performance, managing database clusters, and ensuring the smooth operation of your PostgreSQL-powered applications. By comprehending the roles and interactions of the postgres server process, backend processes, and background processes, you gain insight into how queries are processed and how resources are managed. Additionally, familiarity with the memory architecture allows you to fine-tune memory settings, improving query execution speed and overall system performance.
Remember, mastering the intricacies of PostgreSQL's architecture empowers you to harness the full potential of this powerful relational database management system, enabling you to build robust and efficient applications that handle data with ease. So, let's continue our journey into the depths of PostgreSQL.
Stay tuned for an exciting dive into the internal workings of PostgreSQL's data storage In the next blogs!.

Top comments (0)