
1. Giriş
Yapay zeka ve makine öğrenimi, çağımızın en heyecan verici alanlarından biridir. Bu alanlar, insan benzeri zekanın yaratılması, karmaşık problemlerin çözülmesi ve veri odaklı kararların alınması gibi birçok uygulama alanında büyük potansiyel sunar. Bu kapsamda, doğal dil işleme (NLP) gibi alt alanlar, insanların doğal dilini anlama, işleme ve üretme yeteneği üzerine odaklanır.
Bu makalede, Q-learning algoritmasının doğal dil işleme alanındaki bir uygulamasına odaklanacağız. Özellikle, belirli bir hedef cümleyi oluşturma görevini ele alacağız. Q-learning, bir tür güçlendirme öğrenme tekniği olup, ajanın (burada algoritma) çevresiyle etkileşim kurarak en yüksek ödülü (reward) elde etmek için stratejiler geliştirmesine dayanır. Bu yöntemi kullanarak, hedef cümleyi oluşturmak için gereken karakter dizisini öğretecek ve modelin istenilen metni üretmesini sağlayacağız.
Bu bölümde, yapay zeka ve makine öğrenimi kavramlarına genel bir giriş yapacak ve ardından Q-learning algoritmasının temel prensiplerine odaklanacağız. Daha sonra, bu makalenin odaklanacağı spesifik problemi ve kullanılacak yaklaşımı tanıtacağız. Son olarak, makalenin geri kalanında ele alınacak konulara bir genel bakış sunacağız.
1.2 Q-Learning Algoritması Nedir ve Nerelerde Kullanılır?
Q-learning, güçlendirme öğrenme algoritmalarından biridir. Bu algoritma, ajanın (örneğin bir yapay zeka) çevresiyle etkileşimde bulunarak çevresinden öğrendiği bilgileri kullanarak en iyi eylemi seçmeyi amaçlar. Q-learning algoritması, ödül ve ceza gibi geri bildirimlerle ajanın davranışını şekillendirir. Bu algoritma, özellikle durumsal karar verme problemlerinde (örneğin oyunlar, robotik ve otomatik kontrol sistemleri) kullanılır.
Bu çalışmanın ilerleyen bölümlerinde, Q-learning algoritmasının metin oluşturma problemine uygulanması incelenecektir. Bu problemde, bir hedef cümle oluşturmak için Q-learning algoritmasını kullanarak modelin nasıl eğitileceği ve istenilen metni üretmek için nasıl kullanılacağı gösterilecektir.
2. Problem

Metin oluşturma problemi, yapay zeka tekniklerinin kullanıldığı bir alt alan olup, belirli bir metni (genellikle bir cümle veya paragrafı) otomatik olarak üretme amacını taşır. Bu problemde, bir hedef metin veya cümle belirlenir ve bu metni oluşturabilecek bir modelin eğitimi hedeflenir. Bu tür bir model, doğal dil işleme (NLP) alanında önemli bir uygulama alanına sahip olup, metin tabanlı sistemlerin geliştirilmesinde yaygın bir şekilde kullanılmaktadır.
2.2 Hedeflenen Cümle ve Karakterler Arasındaki İlişki
Bu belirli durumda, hedeflenen ifade Hello, how are you? şeklindedir. Bu ifade, temel bir iletişim örneğidir ve metin oluşturma modelinin bu ifadeyi üretebilmesi amaçlanmaktadır. Model, bu ifadeyi oluşturmak için adım adım ilerleyerek her adımda doğru karakteri seçmelidir. Fakat modelin karakter seçimindeki başarısı, Q-learning algoritması tarafından öğrenilecek ve geliştirilecektir.
2.3 Q-Learning ile Problem Çözme Yaklaşımı
Bu sorunun çözümü için, metin oluşturma sürecini modellemek için Q-learning algoritması kullanılmıştır. Q-learning, bir ajanın (burada metin oluşturma modeli) çevresiyle etkileşime girerek en iyi eylemi (burada karakter seçimi) öğrenmesini sağlar. Her adımda, model mevcut durumu değerlendirir, mevcut duruma bağlı olarak bir eylem seçer ve aldığı ödüle göre davranışını günceller. Bu süreç, hedeflenen cümle oluşturulana kadar devam eder. Bu çalışma kapsamında, metin oluşturma problemine odaklanacak ve Q-learning algoritmasının nasıl kullanıldığını ve bu algoritmaya dayalı olarak modelin nasıl eğitileceğini detaylı bir şekilde inceleyeceğiz. Ardından, eğitilen modelin kullanımı ve elde edilen sonuçların değerlendirilmesiyle ilgili ayrıntılara odaklanacağız.
3. Kod Yapısı ve Açıklamalar

Bu kısımda, kullanılan kodun yapısı, içeriği ve hedefleri detaylı bir şekilde ele alınacaktır. Kod, metin oluşturma problemi için Q-learning algoritmasının nasıl uygulandığını içermektedir. Ek olarak, kullanılan kütüphaneler, değişkenlerin rolleri ve algoritmanın işleyişi ile ilgili açıklamalar sunulacaktır.
3.2 Kodun İçeriği ve Amaçları
Python programlama dili ile yazdığımız kodumuzun temel amacı, Q-Learning algoritması ile belirli bir hedef cümleyi oluşturabilen vir modelin eğitilebilmesidir.
Kodun Yapısı:
- Hedeflenen cümlenin tanımlanması.
- Karakterlerin ve alfabenin belirlenmesi.
- Q-learning algoritmasının uygulanması.
- Eğitim ve öğrenme sürecinin gerçekleştirilmesi.
- Eğitilen modelin kullanılması ve tahminlerin yapılması.
3.3 Kullanılan Kütüphaneler ve Araçlar
- Numpy: Sayısal hesaplamalar için kullanılan bir kütüphane olup, matris işlemleri ve veri manipülasyonu için idealdir (Kaynak: Numpy)
- Matplotlib: Veri görselleştirmesi için kullanılan bir kütüphanedir ve eğitim sonrası elde edilen Q değerlerinin ısı haritası şeklinde görselleştirilmesinde kullanılacaktır. (Kaynak: Matplotlib)
3.4 Değişkenlerin Tanımları ve Rolü
Hedef cümle: Öğretmek istediğimiz cümle.
sentence = "Hello, how are you?"
Karakter listesi: Öğrenirken kullanacağı karakterler
characters = " abcdefghijklmnopqrstuvwxyz,?"
Learning rate: Öğrenme eğrisi
alpha = 0.1 # Learning rate
Gelecekteki ödüller için indirim faktörü:
gamma = 0.9
Epochs: Kaç kere öğreneceği
num_episodes = 10000
Bu değişkenlerin her biri, algoritmanın belirli bir adımında hangi eylemin seçileceğini, ödüllerin nasıl hesaplanacağını ve modelin nasıl güncelleneceğini belirlemek için rol oynar.
4. Kod
Bu bölümde kodu parça parça inceleyip açıklayacağız.
4.2 Kütüphanelerin indirilmesi
import numpy as np
import matplotlib.pyplot as plt
Burada Numpy ve Matplotlib kütüphanelerini import ediyoruz.
4.3 Gerekli değerlerin belirlenmesi
sentence = "Hello, how are you?"
characters = " abcdefghijklmnopqrstuvwxyz,?"
alpha = 0.1 # Learning rate
gamma = 0.9 # Discount factor for future rewards
num_episodes = 10000 # Number of training episodes
Q = np.zeros((len(sentence), len(characters)))
Zaten 3.3 Bölümde burada belirlediğim değerleri açıkladım. Sadece Q değerini açıklamamız gerekiyor.
Q: Her bir durum ve eylem kombinasyonu, o kombinasyonun değerini ifade eder. Bu değer, o durumda yapılan eylemin ne kadar arzu edildiğini veya avantajlı olduğunu gösterir. (Burada durum cümlenin oluşması eylem ise Harflerin seçilmesidir.)
4.4 Eğitimin yapılması
for episode in range(num_episodes):
state = 0
done = False
while not done:
action = np.random.randint(len(characters))
if state == len(sentence) - 1:
done = True
else:
# Determine the next state
next_state = state + 1
if sentence[state] == characters[action]:
reward = 1
else:
reward = 0
Q[state, action] += alpha * (reward + gamma * np.max(Q[next_state]) - Q[state, action])
state = next_state
Kodumuz yukarıda görüldüğü gibidir.
Parçalamak gerekirse:
state = 0
done = False
Bu bölümde:
state 0 sayısı ile belirlenir. Bu modelin cümlenin kaçıncı harfinde olduğunu gösterir.
done False olarak belirlenir. Bu bir eğitim sürecinin tamamlanıp tamamlanmadığını gösterir.
while not done:
action = np.random.randint(len(characters))
Bu bölümde:
- While Loop'umuz başlar ve action içinde rastgele bir karakter atanır.
if state == len(sentence) - 1:
done = True
Bu bölümde:
- Eğer state, cümlenin sonuna geldiyse done değerini True yapıyoruz.
if state == len(sentence) - 1:
done = True
Bu bölümde:
- Eğer state, cümlenin sonuna geldiyse done değerini True yapıyoruz. Bu sayede eğitim son buluyor.
else:
next_state = state + 1
Bu bölümde:
- Eğerki cümlenin sonuna gelinmediyse state değerini bir arttırıyoruz ve next_state diye bir değerde tutuyoruz.
if sentence[state] == characters[action]:
reward = 1
else:
reward = 0
Bu bölümde:
- Eğerki cümlede tahmin edilmesi gereken karakteri, modelimiz doğru tahmin edebildiyse reward'ı 1, eğerki doğru tahmin edemediyse reward'ı 0 yapıyoruz.
Q[state, action] += alpha * (reward + gamma *np.max(Q[next_state]) - Q[state, action])
state = next_state
Bu bölümde:
- Bu bölümde Q değerimiz reward değeri ve diğer değerlerle güncelliyor ve öğrenmeyi sağlıyoruz. Bununla birlikte en sonunda state değerini next_state değerine eşitliyor bu sayede cümle içindeki sonraki karaktere geçiş işlemini sağlıyoruz.
4.5 Tahminin yapılması
Tahmin süreci Eğitim sürecine kıyasla daha basit.
predicted_sentence = ""
state = 0
while state < len(sentence):
action = np.argmax(Q[state])
predicted_sentence += characters[action]
state += 1
print("Predicted Sentence:", predicted_sentence)
Bu tahmin kodumuz. Kısaca:
- Tahmin etmek istediğimiz cümlenin her harfini eğittimiz Q değerine göre modele tahmin ettiriyor ve bunu sırası ile bir String değerine kaydediyoruz (Kaydetme kısmı opsiyonel)
Örnek bir çıktı:
- 100 Tekrar ile eğitilmiş:

- 500 Tekrar ile eğitilmiş:

- 1000 Tekrar ile eğitilmiş:

İlerleyen zamanlarda örnek çıktıları karşılaştıracağız ama şimdilik Eğitim süresinin arttması ile modelimizin doğru tahmin etme beceresi paralel yükseliyor diyebiliriz. Bu çıkarımımız da bizi modelin öğrendiği düşüncesine götürüyor.
4.6 Modelin Göselleştirilmesi
En önemli bölümlerden biri olan Görselleştirme...
plt.figure(figsize=(12, 8))
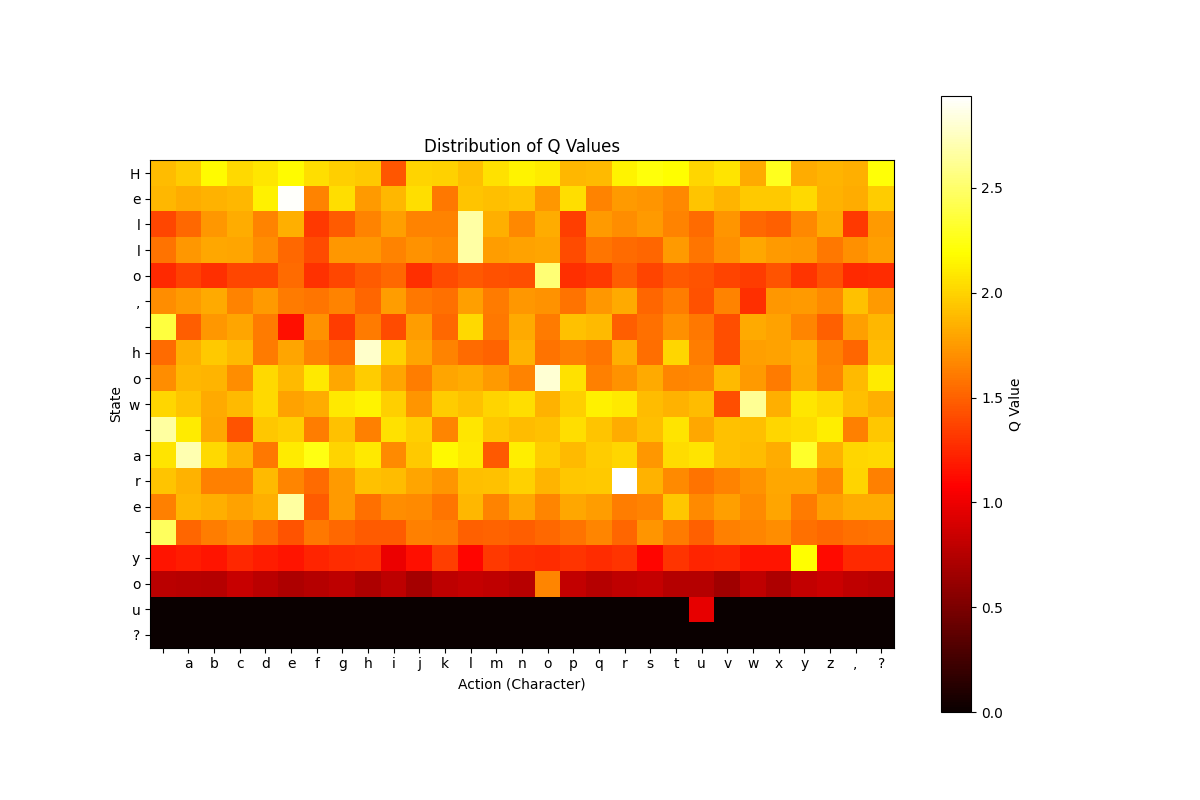
plt.imshow(Q, cmap='hot', interpolation='nearest')
plt.colorbar(label='Q Value')
plt.title("Distribution of Q Values")
plt.xlabel("Action (Character)")
plt.ylabel("State")
plt.xticks(np.arange(len(characters)), list(characters))
plt.yticks(np.arange(len(sentence)), list(sentence))
plt.show()
Yukarıda ki kod bloğu ile birlikte modelimizin Hangi durumda hangi aksiyonu daha doğru bulduğunu gösteriyor. Bu görselleştirme için Isı Haritası mdoelini seçtim. Çünkü anlaması ve okumasını daha basit olduğunu düşünüyorum ama siz dilediğiniz gibi diğer görselleştirme modellerini deneyebilirsiniz.
Örnek bir çıktı:
- 100 Tekrar ile eğitilmiş:

- 500 Tekrar ile eğitilmiş:

- 1000 Tekrar ile eğitilmiş:

5. Sonuçları karşılaştırma
- 100 Tekrar ile eğitilmiş:
- 500 Tekrar ile eğitilmiş:
- 1000 Tekrar ile eğitilmiş:
Sonuç olarak 3 ayrı tekrar sayısı ile eğitilmiş modelimiz var (100-500-1000). Modellerimizin hiç biri '?' bilemedi. Yüz tekrar ile eğitilmiş modelin çıktısı anlamsız olurken. Bin tekrar ile eğitilmis modelin çıktısı bir nebze daha anlaşılıt olmuş.
Ayrıca görüyoruz ki; Bin tekrar ile eğitilmiş modelimiz 'E' harfini nerelerde kullanacağını çok iyi bir şekilde öğrenmiş eğerki biraz daha eğitmeye devam etseydik yada parametlerimizi daha isabetli parametreler ile değiştirseydik, belkide soru işaretini de öğrenebilirdi ?..
Bunu da kendiniz deneyin...
6. Özet ve Kaynakça
Özetlemek Gerekirse:
Bu yazımda Q-Learning algoritmasına bir cümle tahmini projesi ile değindik. Kendiniz denemek isterseniz Github üzerinden kodu indirebilir veya Fotoğraflara ulaşabilirsiniz.
Github:
Article (English)
Makale (Türkçe):
(English) Sentence prediction with Q-learning
Sentence prediction with Q-learning
Try it yourself.
Codes
You can change this parameters:
sentence = "Hello, how are you?"
alpha = 0.1
gamma = 0.9
num_episodes = 10
| Code | Description | Type |
|---|---|---|
sentence |
Sentence, which model will predict |
String |
alpha |
Learning rate |
Float . |
gamma |
Discount factor for future rewards |
Float |
num_episodes |
Number of training episodes |
İnteger |
Screenshot of Result
(Türkçe) Q_Learning ile Cümle tahmini
Q_Learning ile Cümle tahmini
Kodlar
Bu parametreleri değiştirebilirsin:
sentence = "Hello, how are you?"
alpha = 0.1
gamma = 0.9
num_episodes = 10
| Code | Description | Type |
|---|---|---|
sentence |
Modelin tahmin edeceği cümle |
String |
alpha |
Öğrenme eğrisi |
Float . |
gamma |
Gelecekteki ödüller için indirim faktörü (?) |
Float |
num_episodes |
Eğitim sayısı |
İnteger |
Sonuçların Ekran Görüntüleri
Detaylı öğrenim için İngilizce Kaynaklar:
- https://www.youtube.com/watch?v=qhRNvCVVJaA
- https://www.techtarget.com/searchenterpriseai/definition/Q-learning#:~:text=Q-learning%20is%20a%20machine,way%20animals%20or%20children%20learn.
Detaylı öğrenim için Türkçe Kaynaklar:
- https://www.youtube.com/watch?v=zDKGmJMGoDg
- https://medium.com/deep-learning-turkiye/q-learninge-giriş-6742b3c5ed2b
Eğer ki bir "Öneri-İstek-Soru"'nuz var ise lütfen yorum bırakın yada mail üzerinden bana ulaşın...





Top comments (0)