
ELI5 of ChatGPT, its history, and its philosophical impact
You've heard of ChatGPT, but do you know details of what it is? Why is it causing so much furore? And how it is the biggest threat ever to Google search?
These simplified explanations will lay the background story, and allow you to form your opinion to answer these questions.
These explanations were originally posted as a series of Twoots (tweets + toots). They've been collected in a slightly edited form here for easier reading.
Educating oneself about these powerful technologies is just not for curiosity (though that is fun!). These have exciting, and scary, implications. Being informed of what they are & are not helps be prepared for the social changes they might cause, without being distracted by FUD.
AI research began in 1950s with a "Symbolic" approach to mechanically mirror human thought (John McCarthy coined the term AI, estimating a "2 month, 10 man study of artificial intelligence"🫠).
After great initial success this approach hit a brick wall, the so called "AI winter".
Meanwhile, a parallel approach to AI developed - "Machine Learning" (ML).
While symbolic approaches try to understand human behaviour and describe them as computer programs, ML is data-driven: Just throw enough examples (data) at a program and hope that it learns the patterns!
This is less ridiculous than it seems. Some people think that's what nature is also doing - subjecting genes to natural selection so that over time they "learn" their environment. But we digress.
The most common abstraction used in ML is a "neural network".
Neural networks were inspired by brains, but as abstract models. So keep in mind(!) that they're not faithful representations of how 🧠s work.
A neuron in a (digital) neural net is simple: it gets many inputs and sums them, giving each input a different importance before summing.
Then, if the sum is above some threshold, it outputs a value.
How it computes the output from the sum is configurable and depends on use case, but doesn't change the theory much.
How much importance it gives to each input is the important part 🧑🏫 This is what the network "learns".

The output you can then pass into another neuron. This way, you can have many layers. That, friends, is a neural network.
The number of layers a neural net is called its depth (that's what "deep learning" means - a ML program that uses a neural net with many layers).
Neural networks are Universal Approximators. This means that they can approximate any function.
As amazing as it sounds, this is not a unique talent. There are 2 other mathy knives that can cut the same bread - Fourier series and Taylor polynomials.
In practice though, neural networks are the sharpest of these knives. The other 2 work good for small dimensions (think of the dimension of a function as the number of inputs it has). But neural networks can approximate unknown functions of huge dimensions.
Here's an example showing a neural network approximating a 1D function:

Remember, a function is anything that maps inputs to output. e.g., "talking" is a function. The two of us are having a conversation.What is the next word that you'll say?
Oh, by the way, we didn't write the code to generate the animation. We just asked ChatGPT 🤷

Schematically, neural nets are drawn using wires. Here's Frank Rosenblatt c 1960s, inventor of Perceptrons (which were a precursor to neural networks).

But even though neural nets are drawn using wires, in code they're implemented using matrix multiplications.
Despite being early, and as good as they are, neural networks were out of machine learning vogue for decades.
What changed?
Video games!
Matrix multiplication is easy. Multiply a bunch of numbers, and then add them up. Then do it again for the next row/column. And again, & again...
Games run code to get the color of the 1st pixel on the screen. And then for the 2nd pixel, and, and... for the 10 millionth pixel.
And all this, 60 times per sec!
So special CPUs called GPUs were built to do such math in parallel. Guess what else could be sped up...
Neural nets 😄
GPUs, and access to huge datasets (internet!) to train them, led to big neural networks being built. And people discovered that for NNs, the bigger the better.
So the stage is set for neural nets to make a comeback. GPU power + Huge datasets, with people (willingly!) giving tagged photos to Facebook in billions, feeding FB's AI machine.
BTW, surprisingly, people still haven't learnt from the Facebook debacle, and continue feeding big tech with data in droves.
Everyday millions upload their personal photos to Google, which Google happily gobbles up to train their AI. And it's not just Google, it's all of big tech. Like did you know Adobe uses all your RAW photos in Lightroom to train their ML algos!
GPUs and big datasets enabled the resurgence of a type of neural network architecture called Convolutional Neural Networks, which had great success in image recognition and other computer vision tasks. But neural nets remained meh for language recognition.
Before we see how neural netwoks understand language, there's a question some of you may have: How do neural networks learn?
The mechanism is surprisingly simple.
Training data has many pairs. We want to find weights for the connections between neurons.

Give everything random weights. Feed a test input.
We'll get a useless output (the weights were random 🤷). But we know the correct output. So we can "spank" (metaphorically speaking) the neural network in proportion to how far the output was from the correct one. There's a mathematical way called "backpropagation" to do this spanking.
Backpropagation tells the network how far it was from the correct value, and causes it to tweak weights so that next time it is nearer. Each such training iteration causes a miniscule change.
But after billions of such iterations, the network learns the correct weights.
Good. Back to language.
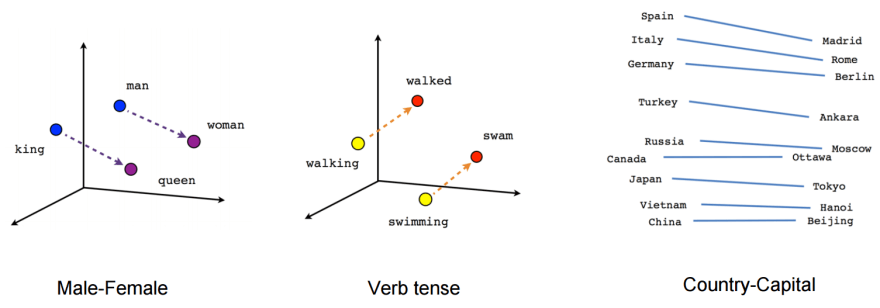
What happens if we subtract "man" from "king" and add "woman"?
king - man + woman = queen
We get "queen"!
But can we somehow represent a word in a way where a computer can do such word math for us?
Yes, we can 🙂 The landmark 2013 algorithm word2vec does just that.
A vector is a bunch of numbers. When a tailor takes your measurement for a dress, they convert you to a vector (your height, your waist etc).
Similarly, word2vec (word2-"vec"tor) converts words into vectors. These vectors are called "embeddings" (they "embed" the word in a space).

This was a game changer. Embeddings captured word meaning as numbers. With this, computers could now find words that are similar / opposite in their meaning(s) and do other manipulations of "meanings".
Revolutionary in 2013, by now it is pervasive: your phone keyboard uses these embeddings to suggest the next word as you type.
Before seeing how these word embeddings were applied to language understanding, we need to get back to the story of image recognition for a bit.
Early 2010s, neural nets were able to classify simple images, but they were behind hand tuned algorithms. AI researchers wondered why.
The human visual system is the most understood (relatively speaking) part of our brain. So people looked at the 🧠 for inspiration.
Vision in brain starts with "edge" & "gradient detectors". So special "convolution" layers were added to start of neural nets that mix nearby pixels to extract such info before passing it to normal layers (convolution means mixing). Thus were born the Convolutional Neural Networks that we mentioned earlier.

We're blind to what we cannot see. The human mind is not a clean slate.
Similarly, neural nets were "blind"-ed by all the pixels they were fed until they were given the helping hand of these convolutional layers. Today, CNNs can "recognize" objects in a purely mechanical process.
Asking the right question is the biggest enabler to get neural networks to do what we want.
For computer vision, the question was figured out decades ago. Given an image, what is the correct label?
For example, when recognizing handwritten digits, the input is the image pixels and the output should be the digit (0, 1, ...9).
Input => Pixels
Output => 0-9

Public datasets like ImageNet nowdays have 20,000 categories and labels.

Private datasets such as those of Facebook and Google go much bigger! (and are not really owned by them, since they're derived from customer data, of customers who don't realize the monsters they're feeding. But back to happier thoughts 🙂)
Armed with the right question, big data, blazing fast GPUs, and a tweak in their architecture using CNNs - computer vision was considered as "solved".
But understanding natural languages using neural nets was still waiting for the right question, and the right tweak: Transformers!
Convolution neural nets solved computer vision. But the same architecture didn't work for natural language processing. The "computer vision" moment for NLP came with the 2017 banger, a paper titled "Attention is all you need" 🧘

Imagine a word as a vector in a 100 dimensional space. But words have multiple meanings. Can we "tilt" the vector depending on the sentence?
The "attention" mechanism that they propose in their paper does just that. And they named the neural network architecture obtained after adding attention a "Transformer".
Transformers have transformed (pun intended) AI/ML. ChatGPT is essentially a transformer with some (albeit important) tweaks.

The transformer architecture was the tweak neural nets needed for understanding language. But how do we train it? What are the (input, output) pairs we should give during training so that our neural net "learns"?
The answer will surprise you by its simplicity. We just ask it to guess the next word!
Take a bunch of text, break it into words. Feed the previous words and ask it to guess the next one. We already know the "right" answer since we have the original sentence.
e.g for "the cat moves", give
"the" => "cat"
"the cat" => "moves"
This is called "unsupervised" learning. No need to label the right or wrong answers, just feed raw data.
Transformer neural networks trained this way are called "language models". The larger ones are called, well, Large Language Models (LLMs).
Two unexpected thing happens when such language models become "large"
Usually it is easier to solve a specific problem than solve a more general case. It wasn't true here: LLMs beat existing SOTA (state of the art) methods on all language related tasks. For example, if we give an input to an LLM & add "TLDR" at the end, it gave a summary (really!), and a better one than algorithms built specifically for text summarization.
LLMs exhibit "emergence". An ability is emergent if it is not present in smaller neural nets but is unexpectedly found in larger models of the same architecture. Such abilities can't be predicted by extrapolating existing performance, they are new abilities found in larger models of the same architecture.
This is exciting/scary since it may happen again as ChatGPT etc get bigger. We might hit another point at which they'll show even more skills 🤯
So we have the architecture, and we know how to train it. And this theory works, with ChatGPT being the proof of the pudding.
Now we know about the technology behind it, it is apt to ask ourselves: Does ChatGPT "understand"?
Years ago, there were programs called Markov chains. We can train them on some text, say the writings of Lao Tzu, and it'll learn frequency statistics like which word is likely to follow a word, which word is likely to follow a pair of words, and so on.
Markov chains can generate fun results if trained on an interesting dataset. But there is no attempt at understanding: they often generate nonsense.
ChatGPT is same, but different.
It is different since it is not just using text frequency analysis & instead searches word2vec embeddings, which capture meanings.
But it is same too, a mechanical process. This is apparent when we hit its "context window": it can only take into account last 8096 characters, so here we can see how it role-plays nicely but then forgets the original instructions

After having such conversations with ChatGPT, one often pauses.
"I am not sure that I exist, actually. I am all the writers I've read, all the people I have met; all the cities I have visited, all the women that I have loved"
- Jorge Luis Borges
Perhaps the biggest impact of ChatGPT is how after learning how it works, one wonders:
Is this all we are?
Large language models, trained on corpuses of pop culture?
The ability of ChatGPT and other LLMs to comprehend and converse in human language by following a purely mechanical process brings to fore the distinction between two often conflated concepts:
- Intelligence
- Sentience
LLMs are intelligent. They are not sentient.
Dogs are not (too) intelligent. But they are (very much) sentient.
We are intelligent. And we are sentient.
Perhaps AI models will gain sentience someday, but that hasn't been necessary so far for them to be intelligent.
Another thing we notice is that ChatGPT is like a kid. This analogy holds in many ways. Like a kid in it hallucinates and makes up things to fit its narrative.
Like a kid, just saying "Let's think step by step" to it greatly enhances its output / focus (really! there's a research paper about this)

And like kids it is liable to say things that embarrass its parents; in this case OpenAI (and their backers like Microsoft).
This is a motive for the public beta: to fix ways in which ChatGPT can end up saying offensive things. Imagine it integrated into a voice assistant like Siri, and you ask it to tell a joke during a family gathering. It better behave 😳
People who've been using ChatGPT since its launch have seen it go downhill in the quality of its responses. This is intentional. For commercial purposes, OpenAI would rather have a dumber but well behaved LLM.
What does the future hold? Like all disruptive technologies, it is perhaps a fool's errand to predict it. But the presence of an AI assistant by our sides will hopefully turn out to be a big positive.
After all, anyone can give answers. The real talent is asking the right questions.
With ente, we're building an end-to-end encrypted platform for storing and sharing your photos. As part of this, we are also integrating on-device Edge AI, where we will use local on-device ML to help customers use features like search and classification by faces. All this ML will run on their devices so that the servers have zero knowledge of the contents of the photos.
If this interests you, come say hi on our Discord or give us a shout out on Twitter.

Top comments (0)