
Introduction: Reaching 100M MQTT Connections with a Single Cluster
Not long ago, the scalable distributed IoT MQTT broker EMQX released version 5.0. This latest milestone version adopts the new back-end storage architecture, Mria database, and refactors the data replication logic. This makes the horizontal scalability of EMQX 5.0 exponentially improved, and it can more reliably carry larger-scale IoT device connections.
In the performance test before the official release of EMQX 5.0, we achieved 100 million MQTT connections + 1 million message throughput per second through a 23-node EMQX cluster for the first time in the world, which also makes EMQX 5.0 the most scalable MQTT Broker worldwide so far.
This article will describe in detail the new underlying architecture that exponentially improves EMQX's horizontal scalability, helping you understand the technical principles of EMQX 5.0 cluster expansion, and how to choose a suitable deployment architecture in different practical scenarios to achieve a more reliable device access and message transmission.
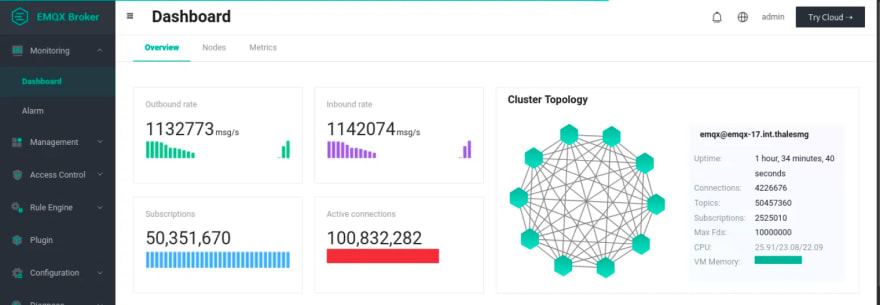
100 million MQTT connections testing result
For test details, please refer to: https://www.emqx.com/en/blog/reaching-100m-mqtt-connections-with-emqx-5-0
4.x Era: Building EMQX Clusters with Mnesia
Mnesia Introduction
EMQX 4.x adopts the distributed database Mnesia that comes with Erlang/OTP for storage, which has the following advantages:
- Embedded: Unlike databases such as MySQL and PostgreSQL, Mnesia and EMQX run in the same operating system process (similar to SQLite). Therefore, EMQX can read routing, session and other related information at a very fast speed.
- Transactional: Mnesia supports transactions and has ACID guarantees. And these guarantees are valid for all nodes in the entire cluster. EMQX uses Mnesia transactions where data consistency is important, such as updating routing tables, creating rules engine rules, etc.
- Distributed: The Mnesia table is replicated to all EMQX nodes. This can improve the distributed fault tolerance of EMQX. As long as one node is guaranteed to survive, the data is safe.
- NoSQL: Traditional relational databases use SQL to interact with the database. Mnesia directly uses Erlang expressions and built-in data types for reading and writing, which makes the integration with business logic very smooth and eliminates the overhead of data encoding and decoding.
In a Mnesia cluster, all nodes are equal. Each of them can store a copy of the data and can also initiate transactions or perform read and write operations.
The Mnesia cluster uses a full mesh topology: that is, each node establishes a connection to every other node in the cluster, and every transaction is replicated to all nodes in the cluster. As shown below:
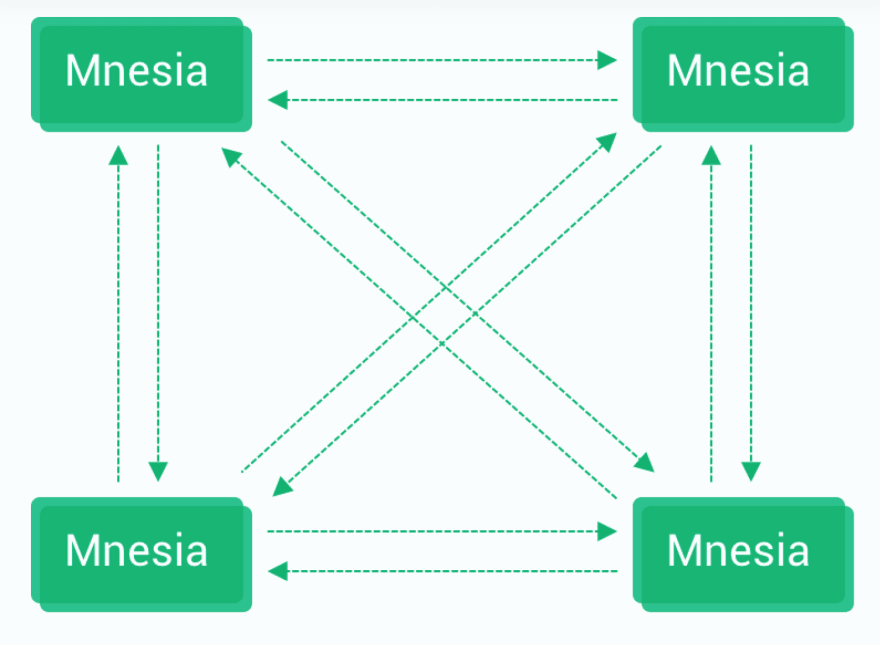
Mnesia's Limitation
As we discussed above, the Mnesia database has many significant advantages, and EMQX has also benefited greatly from it. However, its fully connected feature limits the horizontal scalability of its cluster, because the number of links between nodes increases with the square of the number of nodes, the cost of keeping all nodes fully synchronized is getting higher and higher, and the performance of transaction execution will also sharply decline.
This means that the cluster function of EMQX has the following limitations:
- Insufficient horizontal scalability. In 4.x, we do not recommend too many cluster nodes, because the overhead of transaction replication in a mesh topology will increase; we generally recommend that the number of nodes be kept at 3 to 7, and the performance of a single node should be provided as much as possible.
- Increasing the number of nodes increases the likelihood of cluster split-brain . The more nodes there are, the more the number of links between nodes will increase sharply, and the requirements for network stability between nodes are higher. When split-brain occurs, self-healing of the node will cause the node to restart and risk data loss.
Nevertheless, EMQX achieves the goal of 10 million MQTT connections in a single cluster with its unique architecture design and the powerful features of Erlang/OTP. At the same time, EMQX can carry larger-scale IoT applications through multiple clusters in the form of cluster bridging. However, with the development of the market, a single IoT application needs to support more and more devices and users, which requires EMQX to have stronger scalability and access capabilities to support ultra-large-scale IoT applications.
5.x Era: Building Large-Scale Clusters with Mria
Mria is an open source extension to Mnesia that adds eventual consistency to clusters. Most of the features described earlier still apply to it, the difference is how data is replicated between nodes. Mria switched from a full mesh topology to a mesh+star topology. Each node assumes one of two roles: core node or replicant node.
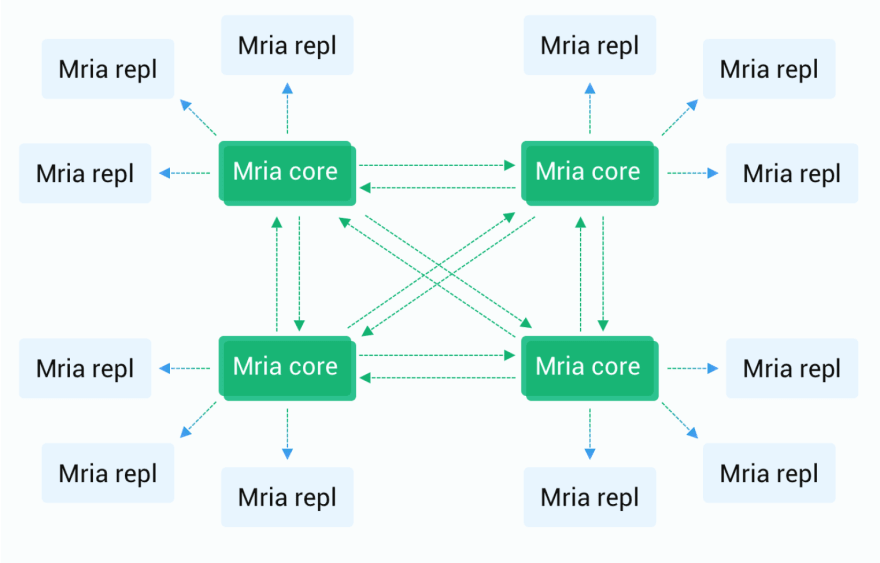
Core and Replicant Node Behavior
The behavior of Core nodes is the same as that of Mnesia nodes in 4.x: Core nodes form a cluster in a fully connected manner, and each node can initiate transactions, hold locks, and so on. Therefore, EMQX 5.0 still requires Core nodes to be as reliable as possible in deployment.
Replicant nodes are no longer directly involved in the processing of transactions. But they connect to Core nodes and passively replicate data updates from Core nodes. Replicant nodes are not allowed to perform any write operations. Instead, it is handed over to the Core node for execution. In addition, because Replicants will replicate data from Core nodes, they have a complete local copy of data to achieve the highest efficiency of read operations, which helps to reduce the latency of EMQX routing.
We can think of this data replication model as a mix of masterless and master-slave replication. This cluster topology solves two problems:
- Horizontal scalability (as mentioned earlier, we have tested an EMQX cluster with 23 nodes)
- Easier cluster auto-scaling without risk of data loss.
Since Replicant nodes do not participate in write operations, the latency of write operations will not be affected when more Replicant nodes join the cluster. This allows creating larger EMQX clusters.
Additionally, Replicant nodes are designed to be stateless. Adding or removing them will not result in loss of cluster data or affect the service state of other nodes, so Replicant nodes can be placed in an autoscaling group for better DevOps practices.
For performance reasons, the replication of irrelevant data can be divided into independent data streams, that is, multiple related data tables can be assigned to the same RLOG Shard (replicated log shard), and transactions are sequentially replicated from Core nodes to the Replicant node. But different RLOG Shards are asynchronous.
EMQX 5.0 Cluster Deployment Practice
Cluster Architecture Selection
In EMQX 5.0, all nodes default to Core nodes if no adjustments are made, and the default behavior is consistent with v4.x.
You can set the node as a Replicant node by setting the emqx.conf node.db_role parameter in or the EMQX_NODE__DB_ROLE environment variable.
Note:At least one core node is required in the cluster, we recommend starting with a setup of 3 Cores + N Replicants
Core nodes can accept MQTT client connections, and can also be used purely as a cluster database. we suggest:
- In a small cluster (3 nodes or less), it is not necessary to use the Core + Replicant replication mode. You can allow the Core nodes to undertake all the traffic to decrease the difficulty of getting started and used.
- In very large clusters (10 nodes or more), it is recommended to move the MQTT traffic from the Core nodes, which is more stable and horizontally scalable.
- In a medium-sized cluster, it depends on many factors and needs to be tested according to user's actual scenario.
Exception Handling
The Core node is insensitive to the Replicant node. When a Core node goes down, the Replicant node will automatically connect to another Core node in the cluster. During this process, the client will not be disconnected, but it may observe stale routing information; when the Replicant node is down, all clients connected to the node will be disconnected, but since Replicant is stateless, it will not affect the stability of other nodes. At this time, the client needs to set a reconnection mechanism to connect to another Replicant node.
Hardware Configuration Requirements
Network
It is recommended that the network delay between core nodes be less than 10ms. The actual measurement is higher than 100ms and it will not be available. Please deploy the core nodes in the same private network; Replicant and core nodes are also recommended to be deployed in the same private network, but the network quality Requirements can be slightly lower than between Core nodes.
CPU and Memory
Core nodes require a large amount of memory, and the CPU consumption is low when no connections are undertaken; the hardware configuration of Replicant nodes is consistent with v4.x, and its memory requirements can be estimated according to the connection and throughput configuration.
Monitoring and Debugging
The performance monitoring of Mria can be viewed using Prometheus or EMQX Dashboard. Replicant nodes go through the following states during startup:
- bootstrap : When the Replicant node is started, the process of synchronizing the latest data table from the Core node
- local_replay : When a node completes bootstrap, it must replay write transactions generated since the beginning of the bootstrap
- normal : When the cached transactions are fully executed, the node enters the normal running state. Subsequent write transactions are applied to the current node in real-time. In most cases, Replicant nodes will remain in this state.
Prometheus Monitoring
Core Node
-
emqx_mria_last_intercepted_trans: The number of transactions received by the shard since the node started. Please note that this value may vary from different core nodes. -
emqx_mria_weight: A value used for load balancing. It varies depending on the instantaneous load of the core nodes. -
emqx_mria_replicants: The number of replicators connected to the core node, replicating data for a given shard. -
emqx_mria_server_mql: The number of pending transactions, waiting to be sent to the replicator. Less is better. If this indicator has a growing trend, more core nodes are needed.
Replicant Node
-
emqx_mria_lag:Replica lag, indicating the degree to which the replicator lags the upstream core node. Less is better. -
emqx_mria_bootstrap_time:Time spent during replica startup. This value does not change during normal operation of the replica. -
emqx_mria_bootstrap_num_keys:The number of database records copied from the core node during boot. This value does not change during normal operation of the replica. -
emqx_mria_message_queue_len:The message queue length of the replication process. It should stay around 0 all the time. -
emqx_mria_replayq_len: The length of the replica's internal replay queue. Less is better.
Console Command
./bin/emqx eval mria_rlog:status(). More information about the running status of Mria database can be obtained.
Note: It can show some shards as
downstatus, which indicates that these shards are not used by any business applications.
Epilogue
The new underlying architecture enables EMQX 5.0 to have stronger scalability. While building a larger-scale cluster that meets user business needs, it can reduce the risk of split-brain under large-scale deployment and the impact after split-brain. This effectively reducing clusters maintenance overhead and provide users with more stable and reliable IoT data access services.





Latest comments (0)