Originally posted on Enmascript.com, for a better reading experience go to the original post.
Tracking data in our applications nowadays is pivotal to business growth, if done properly it can provide fundamental insights for an application that will allow us to understand how to improve it, data helps us understand our users which allows companies to understand their strengths and weaknesses better. Finally, good tracking marks the difference between success and failure, that's why getting it right is so important.
1.Why using XMLHttpRequest and Fetch is not always the right choice
Usually, when we need to track actions in our applications in javaScript, we will make use of an XMLHttpRequest or even better the Fetch API, this will allow us to make asynchronous requests which send valuable information to our servers or analytics services, this works very well for many types of tracking interactions, for example tracking when a user scrolled past a certain section of the page
or checking the behavior of users to understand why a call to action may not be performing well.
In summary, asynchronous requests are used constantly for tracking, and with reason, they allow us to send information quietly and in parallel to avoid interrupting the user's flow, but, there are some edge cases in which they might not be as efficient, like tracking an element when the page is about to get unloaded.
Suppose that you want to track certain data and send it but the user decides to leave the page and go somewhere else, if your request is still in-flight the data will not reach the server because it will get canceled when going away from your page, so in essence:
![]()
The first click generates a request and since it has enough time to be processed it ends up being successful, on the other hand the second click happens right before the page gets unloaded which causes the request to be interrupted and therefore canceled, this right here is the reason why using rudimentary asynchronous request can't ensure the resolution of tracking requests.
2. Why using redirects is not the golden standard
Another popular way of tracking data nowadays is by leveraging redirects, this basically consists of a 3 steps process:
![]()
- The user clicks a link, this link is not a direct connection to the destination URL, it is a link to an intermediary service.
- The intermediary service receives the request with the information, it then processes it and sends it over to each service that may need the data (this includes sending data to the tracking services)
- The user is finally redirected to the destination URL by the intermediary service.
This approach is good but it causes a delay in the user experience due to the redirection step that occurs synchronously, if the redirect takes long it may end up leading the user to leave the page, also if an unexpected error occurs in the redirecting layer the user might get stuck into this flow.
3. Enters the Beacon API
The Beacon API allows us to also send asynchronous requests to a web server but with a key difference, Beacon requests are guaranteed to be sent, yes, even after a page gets unloaded. This means that they are perfect to use for those cases in which:
- You may want to track clicks on links.
- When sending pivotal data in moments where users leave the site.
- In cases in which you are not able to ensure the integrity of a normal asynchronous request.
To use the Beacon API it is very simple, you can access the function sendBeacon through the navigator object:
const url = `https://myurl.com/api/tracking`;
const data = new Blob([JSON.stringify({ tracked: true })], {type : 'application/json; charset=UTF-8'});
const beaconQueued = navigator.sendBeacon(url, data);
if (beaconQueued) {
// The request was queued
} else {
// Something went wrong when trying to queue the request
}
We can send data as an ArrayBufferView, ArrayBuffer, Blob, DOMString, FormData, or URLSearchParams object. In the example above we are sending the information by using the Blob object, this is commonly used to send information to your server so you can manipulate the data like a JSON object.
Some key concepts about the navigator.sendBeacon function:
It returns a boolean
navigator.sendBeacon returns a boolean value, which means that the "Beacon" request was either enqueued (true) to be processed or not (false), this does not necessarily mean the request will be successful but as per the Beacon definition, the request is guaranteed to be executed and completed.
It is executed after higher priority tasks
After enqueued, the request will be executed only after more important tasks have been processed, this is important to understand because this means that the request won't necessarily happen right away in some cases.
Beacon Request Size Limit
According to the documentation of the processing model for the Beacon API:
Requests initiated via the Beacon API automatically set the keepalive flag, and developers can similarly set the same flag manually when using the Fetch API. All requests with this flag set share the same in-flight quota restrictions that is enforced within the Fetch API.
and if we then read the Fetch API specs especially on section 4.6 it says the following:
If the sum of contentLength and inflightKeepaliveBytes is greater than 64 kibibytes, then return a network error.
which means that the size limit is roughly 65.5 Kilobytes (just for general knowledge 1 Kibibyte = 1.024 Kilobytes)
All this means that if we change a normal Fetch request for a Beacon based request, the following will occur:
![]()
As you can see the request would not get canceled, it would get enqueued, then stalled for the necessary time and finally executed.
4.The Ping Attribute, a curious case
Not many people know about this, but there is an HTML attribute used in anchor tags that is specifically created to help track information asynchronously in a non-blocking manner.
The Ping attribute allows you to execute a POST request to an URL or list of URLs specified, it sends the word PING as the request payload. This property is not supported by all browsers but the fact that many popular browsers support it presents a great advantage.
It is used in the following way:
<!-- For a single POST request URL -->
<a href="https://enmascript.com" ping="https://enmascript.com/api/tracking"></a>
<!-- For Multiple POST request URLS -->
<a
href="https://enmascript.com"
ping="https://enmascript.com/api/tracking https://enmascript.com/api/tracking-2">
</a>
When clicking the first link above it will take the user as usual to https://enmascript.com but in parallel it will make an asynchronous POST request to https://enmascript.com/api/tracking. You might be thinking what is the use of a POST request in which request's payload is a simple word called "PING"?, well, the answer is that you don't really need to send the data as a request payload.
You can use querystrings to send your data to a server
<a
href="https://enmascript.com"
ping="https://enmascript.com/api/tracking/?url=https://enmascript.com">
</a>
In this way you would only need to parse the URL to get the data, in NodeJS for example, you can use Express and you will get access to the query string value through req.query.url, which would return https://enmascript.com.
You can send cookies
As with any post request, you can send information through your headers using cookies, here you can track the session and any data you may need regarding the recent action.
A real use case of the ping attribute: How Google does it
The ping attribute is used by no less than Google, and not on any page, they use it to track users on their search result's page.
If you go to google and make a search for "Enmascript" and inspect the first result, you will find this:
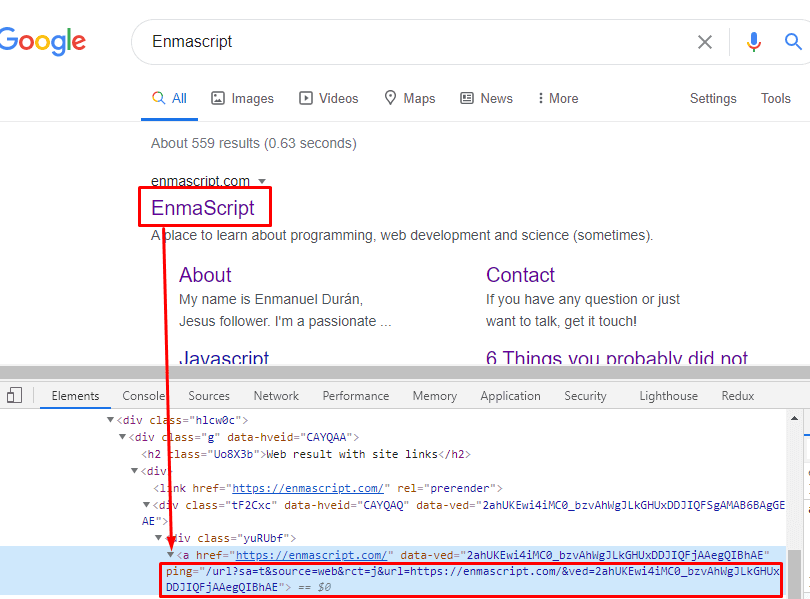
And if you open your network and click on the link you will find a POST request with the PING payload executed to that URL:

I you look closely you can see that google is sending data through query strings and if you inspect the request headers, you will see that cookies are also being sent.
Now, you might be thinking: this is great, but what about Firefox and browsers that do not support the attribute by default?
Glad you asked, you can fallback to use a Beacon request or use a good old server redirect (both already explained above), in Google's case, they decided to handle this by using the redirect approach, so if you search in Firefox you will see that they are not using the ping attribute anymore, instead, they change the anchor's href attribute to be their redirect URL which finally leads to the destination URL.

The goal of this article is to open your mind to other possibilities to improve the consistency of your application, specially on how to efficiently track data while giving users the best experience possible. Remember to always take into consideration your user's privacy and do not take this lightly, make sure to only track what is necessary and keep data anonymized.
Hope you enjoyed it!

Top comments (1)
Great explanation. 👏👏