
Every true podcast has a free and publicly available RSS feed that contains information about the show and each episode. In turn, those episode items include metadata about the show and a link to a hosted audio file. In this tutorial, we will download transcripts for the latest episodes of our favorite shows and store them in text files on our computer.
Before You Start
You will need a Deepgram API Key - get one here. You will also need to install jq and yq to traverse and manipulate XML in your terminal (the data format used for RSS feeds).
This tutorial will be a set of building blocks, slowly growing in complexity towards our end goal. We'll take it slow and explain each step so you can apply this knowledge in other contexts, too.
We'll use the NPR Morning Edition Podcast Feed: https://feeds.npr.org/510318/podcast.xml, but this can be swapped out for your favorite podcast.
Getting Started
Open up your terminal and run the following:
curl https://feeds.npr.org/510318/podcast.xml
This should display the full RSS feed - a bunch of XML (similar to HTML) containing information about the feed.
Get Just The Episode Items
The structure of the XML includes an rss tag containing a channel tag. Inside of channel is a whole bunch of metadata tags for the show and a set of item tags for each episode. item tags are not inside of a containing list as we might expect with HTML - they are all direct children of channel. Try running the following command:
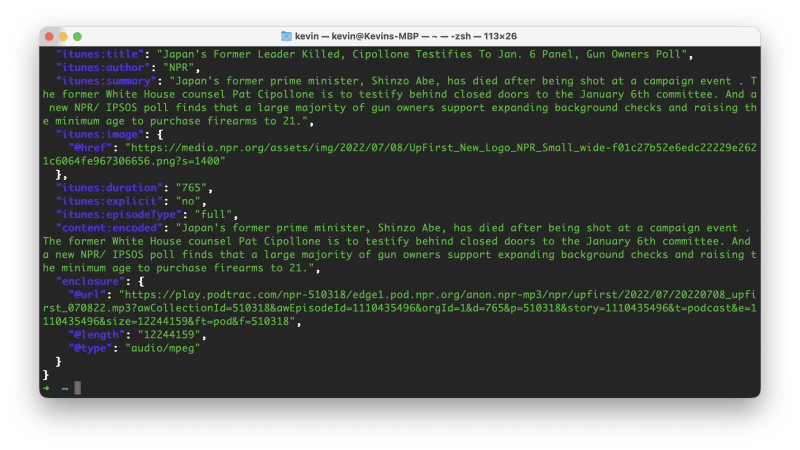
curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[]'
This pipes the curl output into the xq command and extracts all of the item tags. It also pretty prints it in the terminal, which I find quite helpful when exploring the data. What is after the xq command in quotes is known as the 'expression.'
Get Specific Items
We can specify an index position in the square brackets to extract specific items. This will return only the first (latest) item:
curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[0]'
We can also slice the results and list the items with the first n items. This will return only the first three items:
curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[:3]'
Important note - this returns an array (items surrounded in []) while before, it was just several objects being printed to the terminal. To turn this back into a set of objects we can further manipulate, append [] to the command:
curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[:3][]'

Displaying Specific Properties
Even once you extract a list of items, we can extract just a single property by continuing to use the dot syntax:
curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[:3][].title'
If we want to extract a single property from an array of objects, we can use map:
curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[:3] | map(.title)'

As opposed to JSON documents, XML also has attributes (like HTML). To access these, we use the following syntax:
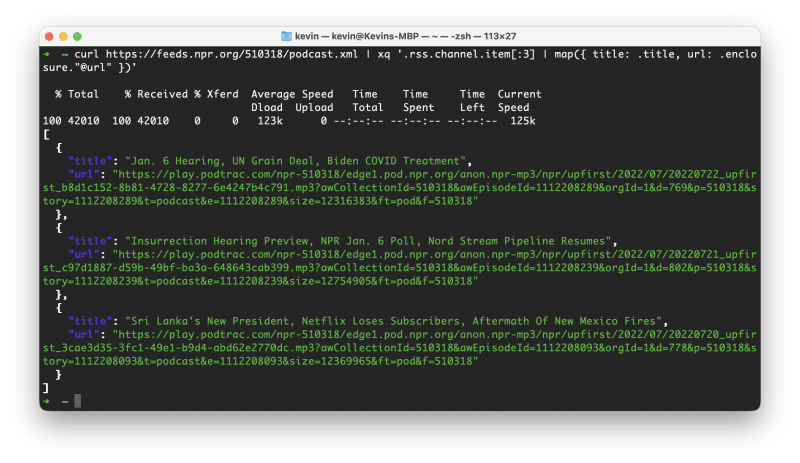
curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[:3] | map(.enclosure."@url")'
Want to create a new data structure? Here we create an object with just the title and url:
curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[:3] | map({ title: .title, url: .enclosure."@url" })'
Looping Through Objects
Objects don't really exist in BASH - so looping through them and extracting values can be a bit tough. Thankfully, a working approach is presented by Start & Wayne's Ruben Koster. Let's walk through it.
Firstly, store the output from the previous step in a variable:
DATA=$(curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[:3] | map({ title: .title, url: .enclosure."@url" })')
This can now be addressed in your terminal as $DATA:
echo $DATA
# Array of objects with title and url will show here
If you try and loop through this data, you'll notice something undesirable:
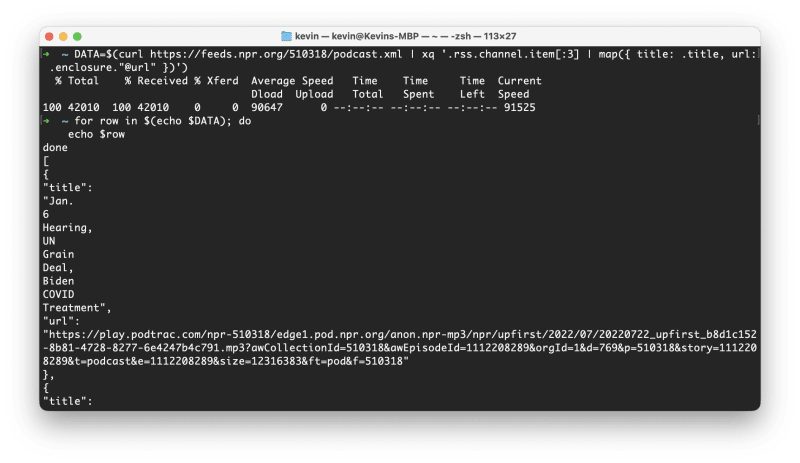
If the whole payload is thought of as a string, this is looping through each word. This isn't what we want. The solution is to base64-encode the data, so it's only one string, then decode it in the loop with a helper function:
for row in $(echo "${DATA}" | jq -r '.[] | @base64'); do
_jq() {
echo ${row} | base64 --decode | jq -r ${1}
}
url=$(_jq '.url')
title=$(_jq '.title')
echo $url, $title
done
Transcribing Each Episode
Now that each podcast item is available in a loop, with both the url and title properties individually addressable, we can generate a transcript using cURL. We go through it in more detail in our recent blog post.
Make sure you replace YOUR_DEEPGRAM_API_KEY with your own Deepgram API Key.
DATA=$(curl https://feeds.npr.org/510318/podcast.xml | xq '.rss.channel.item[:3] | map({ title: .title, url: .enclosure."@url" })')
for row in $(echo "${DATA}" | jq -r '.[] | @base64'); do
_jq() {
echo ${row} | base64 --decode | jq -r ${1}
}
RESPONSE=$(
curl -X POST "https://api.deepgram.com/v1/listen?punctuate=true&tier=enhanced" \
-H "Authorization: Token YOUR_DEEPGRAM_API_KEY" \
-H "Content-Type: application/json" \
-d "{\"url\":\"$(_jq '.url')\"}"
)
echo $RESPONSE | jq '.results.channels[0].alternatives[0].transcript' > "$(_jq '.title').txt"
done
This will create one text file for each episode.
Wrapping Up
jq and xq are exceptionally powerful tools, even more so when combined with cURL requests. With minimal adjustment, you can begin to alter the podcast fetched, the number of transcripts generated, or include additional metadata about the episode in the generated file.
If you have any questions, feel free to reach out - we love to help!

Top comments (0)