Artificial intelligence (AI) is now the cornerstone of software development in fields like quantitative research. Quantitative hedge funds often encounter challenges such as resource wastage and inadequate computing resources during workload surges.
To address these issues, cloud-based elastic computing offers an effective solution. It reduces time to market, allocates resources flexibly, and facilitates the adoption of latest hardware technologies.
JuiceFS, a cloud-native high-performance distributed file system, empowers quantitative hedge funds to enhance AI training and achieve elastic throughput in the cloud. It provides a cost-effective storage solution with accelerated caching, seamlessly integrating on-premises assets with cloud deployments, and optimizing computing resources.
In this post, we’ll discuss the challenges in AI quantitative research, benefits of elastic computing, storage pain points in an elastic environment, and how JuiceFS tackles them with innovative technology. We aim to provide insights to enterprises developing cloud-based machine learning platforms, helping them address challenges of inadequate throughput for their critical data.
Challenges for quantitative hedge funds: fixed IT resources and fluctuating workloads
Quantitative research analyzes market data using mathematical models to inform investment decisions. It's a prominent field in finance that applies AI techniques like machine learning. The graph below shows the daily task volume of quantitative firms, with the yellow line indicating fluctuations. Task volume notably rises during working hours and declines after regular office hours.
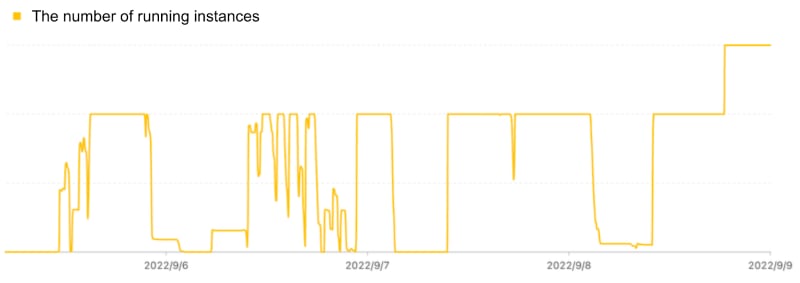
Most quantitative hedge funds rely on fixed IT resources in data centers, including CPUs, memory, and storage. However, this setup presents challenges with fluctuating workloads:
- Waste of resources and reduced efficiency occur when data centers provide fixed computing power, resulting in surplus resources during low-demand periods, while researchers experience queuing and delays during peak hours. Researchers and companies strive to maximize resource utilization and efficiency.
- Insufficient computing resources during workload surges: Researchers often require extensive computing resources for large-scale verifications or validating research papers. Resource insufficiency becomes problematic during staff recruitment or peak workload seasons.
- Inflexible scaling timelines: Data center scaling processes usually take around three months, but hardware shortages can extend this timeline to six months. The protracted supply chain poses challenges in meeting business demands.
Elastic computing offers a simple and efficient solution to these challenges.
Benefits of elastic computing in quantitative hedge funds
The adoption of cloud-based solutions has gained significant momentum among quantitative hedge funds in recent years. By establishing their research platforms in the cloud, such as on AWS, these firms benefit from seamless deployment and optimized resource utilization.
This section explores the advantages of elastic computing in quantitative hedge funds, focusing on minimizing time to market, facilitating flexible resource allocation, and enabling rapid adoption of the latest hardware technologies.
Minimized time to market
Cloud-based research platforms empower quantitative hedge funds to swiftly deploy their systems, eliminating the delays associated with hardware selection and procurement. This streamlined process grants expedited access to computing resources, accelerating research and development cycles.
Flexible resource allocation
Elastic computing empowers quantitative hedge funds to dynamically allocate computing resources based on demand. Researchers can easily adjust resources to meet their specific computing needs, regardless of whether they require substantial computing power or face low-demand periods. This flexibility ensures optimal resource utilization, eliminating the inefficiencies associated with fixed computing power in traditional data centers.
Hybrid cloud approach for established firms
Established quantitative hedge fund firms with existing IDC facilities can effectively leverage a hybrid cloud strategy. By utilizing their IDC assets as fixed computing power during average or low-demand periods, these firms optimize resource allocation. Simultaneously, they can expand their computing capacity by harnessing cloud resources for incremental workloads. This hybrid approach maximizes the use of existing assets while leveraging the scalability and cost benefits offered by the cloud.
Rapid adoption of the latest hardware
Elastic computing enables quantitative hedge funds to stay ahead by swiftly adopting the latest hardware advancements. Unlike traditional hardware procurement, which often involves lengthy depreciation periods of three to five years, elastic computing allows for prompt integration of cutting-edge hardware devices. This agility empowers hedge funds to leverage state-of-the-art technologies and algorithms, enhancing their competitive edge in the market.
Storage pain points in an elastic environment
In an elastic environment, storage presents challenges that are more complex to address compared to compute. While compute tasks are straightforward, storing data requires careful consideration of data retention during elastic computing processes. Additionally, when scaling compute resources, the storage system must be able to handle increased demands while ensuring high availability and scalability to prevent data loss or performance degradation.
Pain point #1: Balancing performance, cost, and efficiency
When enterprises select a storage solution, they typically consider three interconnected factors: performance, cost, and efficiency. Evaluating different options is crucial to find the most suitable solution for specific enterprise requirements.

During the model training phase, high-performance storage solutions are preferred. For instance, on-premises environments may use all-flash arrays or advanced hardware like AWS FSx for Lustre to achieve exceptional throughput performance.
However, these high-performance options come at a higher cost, so low-cost storage solutions for full data archiving are explored. On-premises environments can benefit from high-density storage solutions to reduce costs, while cloud environments may utilize object storage services like Amazon S3.
To strike a balance between cost and performance, enterprises often create two sets of heterogeneous storage environments:
- A low-cost storage system for full data archiving
- A high-performance storage system for model training
Managing data migration and data lifecycle becomes more complex in such multi-storage environments, especially when dealing with multiple regions or cloud environments. Therefore, an effective solution is needed to manage storage efficiently while ensuring speed and cost-effectiveness.
Pain point #2: Slow storage system scaling
Scaling storage systems is often challenging due to the following reasons:
- Complex data rebalancing: We can scale traditional storage systems by adding more hard drives. However, in distributed storage systems, scaling becomes more intricate. It involves data rebalancing to effectively manage all the data across the storage system. This process ensures efficient distribution and utilization of data across multiple storage devices.
- Performance impact: Storage hardware has inherent limitations in terms of performance. When a portion of the hardware's capacity is used for data migration during scaling, it can impact the performance of online applications. This performance degradation can affect the ability of applications to provide services effectively and meet user expectations.
For example, consider a scenario where a large storage cluster is reduced to only three machines, each equipped with two hard drives storing multiple copies of data. In distributed systems, data is usually replicated multiple times for data safety. In this scenario, circles, triangles, and diamonds represent individual files, and each shape has three copies in the distributed architecture.

When the storage capacity is insufficient, new machines need to be added to expand the storage space. However, it’s not just a matter of new data residing on the new machines; existing data must be rebalanced to ensure efficient data management. Specific algorithms are used to move data from old locations to new ones. Additionally, the capacity provided by hard drives is limited. If a portion is reserved for data migration, it can't effectively serve online application operations.
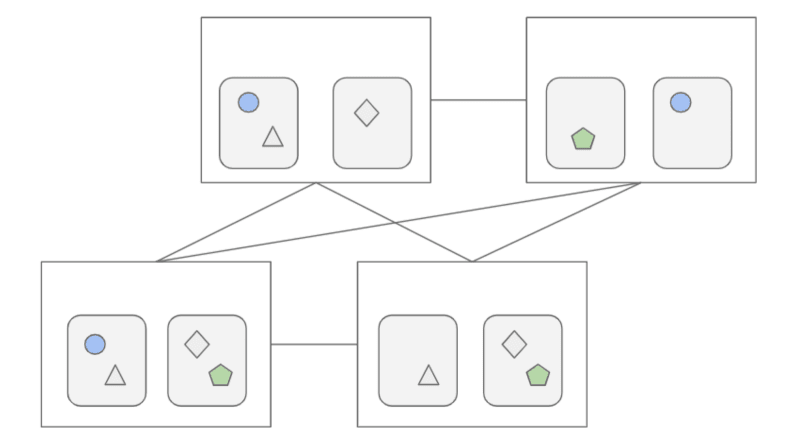
Storage scalability presents challenges, and timing data migration can be as unpredictable as timing the stock market. Ensuring seamless data migration without impacting online operations requires a complex task that often involves manual intervention by experienced professionals.
In addition to increasing capacity, in the event of a disk failure within a cluster, data must be transferred to new disks while maintaining three replicas of each data piece. Therefore, even without capacity scaling, large-scale storage clusters require daily data migration.
Under such challenging conditions for storage system scaling, storage limitations often hinder the implementation of new algorithms, researchers, or inspirations.
Pain point #3: Insufficient performance despite available capacity
Quantitative hedge funds often require scaling due to inadequate throughput performance, rather than insufficient storage capacity.
Hard drives have performance limitations. When existing drives reach their performance limit, new drives must be obtained to meet the increased performance requirements. Even with ample storage capacity, many quantitative funds still need to scale their systems to meet the new performance demands.
For example, consider a scenario where the data that needs to be read is stored within the range represented by the circles in the diagram. The required performance for accessing this data is extremely high. However, the hard drive corresponding to the circles has already reached its performance limit. Now, another researcher needs to read the triangles stored on the same hard drive, but the performance of this hard drive is also at its limit. As a result, accessing the triangle data will be significantly slower.
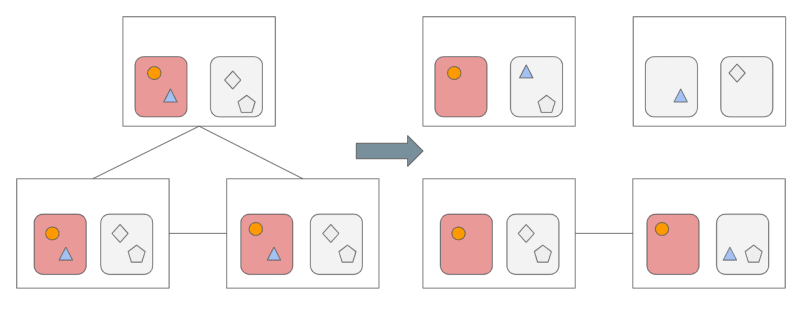
To improve performance, the data in the triangles needs to be migrated to a new hard drive. This is represented by the non-highlighted hard drives in the diagram.
The quantitative hedge funds industry faces this challenge due to its reliance on raw data from market sources. Although the volume of raw data processed is small compared to modern hard drive capacities, it’s shared among multiple researchers. Data sharing and simultaneous access cause performance bottlenecks, even when storage capacity is abundant. It is this characteristic that prompted quantitative funds to seek solutions like JuiceFS to overcome their performance limitations.
To achieve a better balance between overall performance and cost, it is essential to match storage with scalable performance, particularly in scenarios where hot data generation and extreme computation elasticity are required.
How JuiceFS scales performance and achieves cost-effectiveness
When we started developing JuiceFS in 2017, our goal was to design a file storage system specifically for cloud environments. We noticed that existing file storage products in the market were outdated, some even dating back to the 1990s. These products were still widely used in industries like quantitative hedge funds. However, considering the changes in our infrastructure and resource environment, it was crucial for us to align the JuiceFS development with the evolving trends in our current environment.
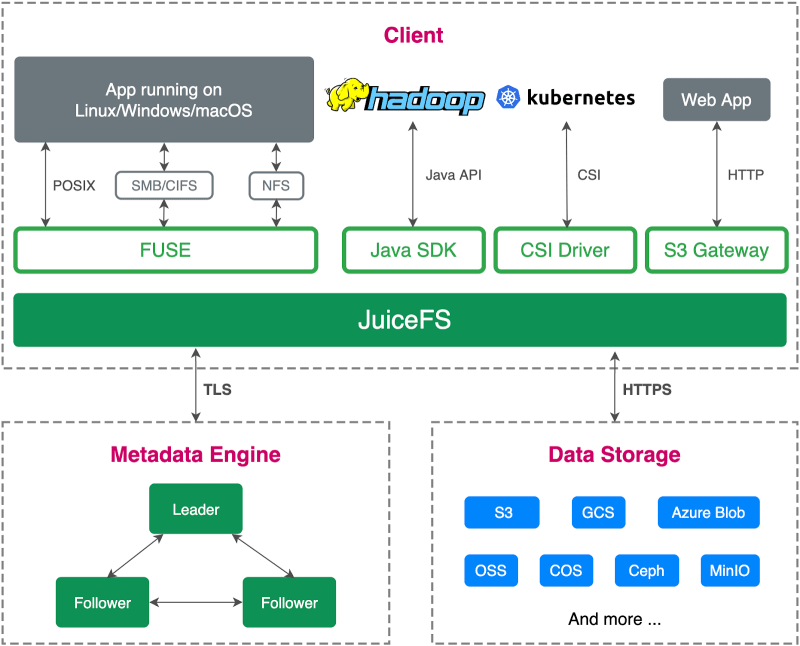
The JuiceFS architecture consists of three components:
- The metadata engine
- The data storage
- The client
The metadata engine
A file system is a technology used for organizing, managing, and accessing files and directories. On our computers, the file system lets us interact with data stored on physical media like hard disks through files and directories.
For example, in Linux, after formatting a hardware device as a file system, we can mount it to a directory. This creates a directory tree with directories, folders, and files. Each file can have assigned permissions and includes metadata, such as creation and modification timestamps. Juicedata has developed a specialized metadata engine to store this information. The performance of the file system relies heavily on the capabilities of this engine.
The data storage
The data storage stores file content. In the past, managing storage systems involved complex tasks such as data chunking, storage, replica management, and migration. However, in the cloud environment, these complexities have been addressed by services like S3. Thus, when we decided to build a file storage system in the cloud, we used S3 and expanded its functionalities. In JuiceFS, all file content is stored in the user's S3 bucket.
The client
The JuiceFS client provides a standard POSIX interface and supports multiple APIs like HDFS, enabling developers to choose the most suitable interface. We also offer performance scalability features to meet higher performance requirements.
To overcome the limitations of S3 in terms of performance and semantics for tasks like model training or quantitative analysis, JuiceFS serves as an intermediate solution. It stores data in S3 and provides POSIX and other APIs to meet diverse application needs. Through internal optimizations, JuiceFS achieves optimal performance.
Caching
JuiceFS incorporates caching to address throughput limitations for hot data in quantitative companies. When a user's GPU compute node accesses data, it fetches data from S3 and stores it in the JuiceFS cache. Subsequent accesses are served from the cache, delivering performance similar to all-flash file storage. The JuiceFS cache is dynamically scalable, providing elastic and scalable throughput. It can be combined with high-performance storage on compute nodes to create a multi-level cache, further enhancing performance.
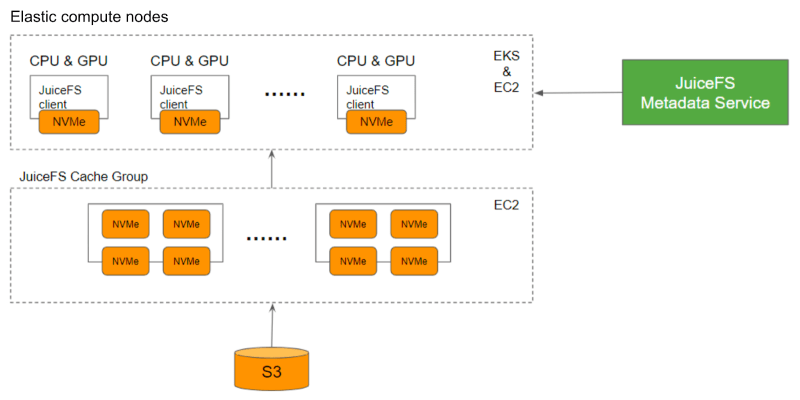
With JuiceFS, data can be stored cost-effectively in S3 while providing an accelerated cache layer that dynamically scales throughput performance.
To tackle data hotspot problems caused by limited NVMe drives storing hot data, cache grouping is employed. Users can create multiple cache groups to store and manage hot data, allowing for easy configuration based on their requirements. This solution effectively resolves data hotspot issues.

Users can define their own cache groups or allocate cache groups to each team. This improves hot data performance and enables near-linear scalability of the system. Additionally, closing these cache groups after work hours helps avoid unnecessary costs.
Hybrid cloud deployment
For quantitative hedge funds with on-premises assets, a hybrid cloud deployment option allows data to be stored in S3 while using the cache group in the on-premises data center for accelerated computation.
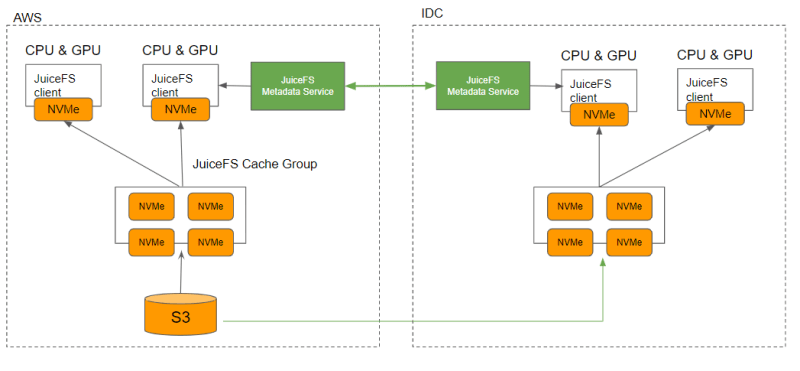
JuiceFS enables data replication between two JuiceFS instances in both cloud and on-premises environments, transparently to users without any additional steps required. By automatically storing hot data in a high-performance cache layer, JuiceFS ensures fast access to hot data, whether tasks are executed in the data center or in the cloud. This approach effectively addresses the challenge of integrating existing on-premises assets with flexible cloud deployments.
Conclusion
JuiceFS presents a game-changing solution for AI quantitative research. By optimizing resource utilization, accelerating time-to-market, facilitating seamless scaling, and enabling rapid adoption of cutting-edge technologies, JuiceFS empowers firms to unlock their full potential and thrive in the dynamic landscape of AI quantitative research.
If you have any questions or would like to learn more, feel free to join our discussions on GitHub and community on Slack.

Top comments (0)