
Python, used in around 53% of all Lambda functions, is the most popular language for doing Serverless. In this article, you'll get an overview of the need-to-knows for error handling Python in AWS Lambda.
Failure types
There are a lot of different things that can go wrong in your Lambda so let's break each of them down.

Syntax Errors
Syntax errors, also known as parsing errors, are perhaps the most common kind of failure. They get thrown before any program command is executed. Here's how one looks like:

Exceptions
Exceptions occur if a statement or expression is syntactically correct but an error is caused when executing it. As a developer, you can handle exceptions and make them non-fatal to your program. However, most exceptions are not handled and result in an error message like this:

Failed to import module
Worth noting separately is the import module exception. In essence, this is an exception as every other, yet it requires some special attention in Lambdas. It is raised before the execution reaches the function handler, meaning it does not reach the execution wrapped by the function handler. This usually prevents this type of failure to be reported by error alerting agents.

Read more about how to handle exceptions in Python.
AWS Lambda errors
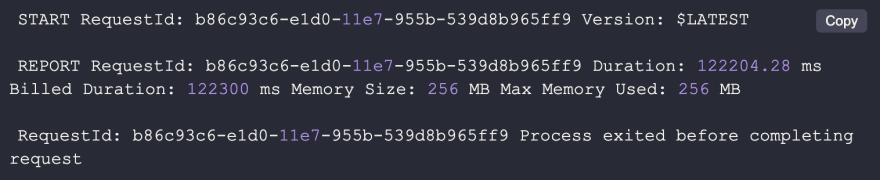
Resource constraint: TIMEOUT
When you are using The Serverless Framework the default timeout is 6 seconds, but you can configure it up to 5 minutes. Here's how a timeout error looks in CloudWatch.

Resource constraint: OUT OF MEMORY
Lambda executions can run into memory limits. You can recognize the failure when both the Max Memory Used and Memory Size values in the REPORT line are identical.
Example:
Configuration failures
In this case, the Lambda function handler that is referenced does not exist.

Handling Failures
Okay, so now we know what can go wrong. Fortunately, Lambda has a few tricks up its sleeve that we can use to remedy the situation.
Retry behavior in AWS
Synchronous invocations: (API Gateway, Amazon Alexa, etc.)
In this case, Lambda returns a 429 error to the invoking application, which is responsible for retries. Some synchronous event sources might have retry logic built-in, so be sure the check the Supported Event Sources from AWS.
Asynchronous invocations: (AWS SNS, AWS SES, AWS CloudWatch, etc)
These events are queued before they are invoked and if the execution fails, they are retried twice with delays between invocations. Optionally, you can specify a Dead Letter Queue for your function and have the failed events go to AWS SQS or SNS. However, if you do not specify a DLQ, the event is discarded after two retries.
Stream-based event sources (Amazon Kinesis Data Streams and DynamoDB streams):
In this case, Lambda polls your stream and invokes a Lambda function. If the invocation fails, Lambda will try to process the batch again until the data expires. To ensure that stream events are processed in order, the exception is blocking and the function will not read any new records until the failed batch is either successfully processed or expired.
Idempotent functions
Depending on the flow of your system, retries can be harmful. For instance, let's imagine a function that is responsible for adding a user row to the database and sending a welcome email. If the function fails after creating the user and gets retried, you will have a duplicate row in the database.
A good way to overcome this is to design your functions to be idempotent.
Idempotent functions are functions with a single task, which either succeeds or can be retried without any damage to the system. You could redesign the aforementioned function using step-functions. First being the function responsible for adding the user to the database and as a second step, another function sends the email. Read more about step functions here.
Improve logging
For later ease of debugging, I recommend logging out useful information like the event object (mind not logging out passwords, etc.), fishy DB and network requests, and other possible points of failure. Also, make sure if you handle a critical exception, to log the trace out. This makes it possible for log-based monitoring solutions like Dashbird to catch and process.
Log-based monitoring & alerting
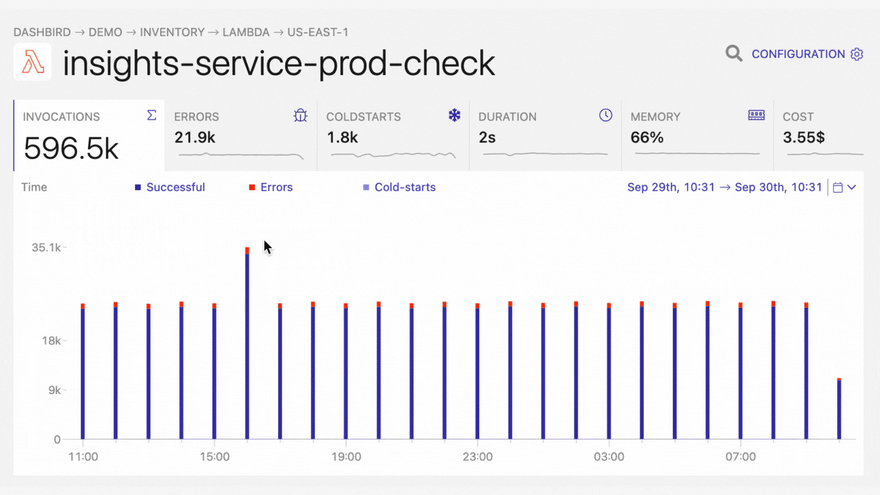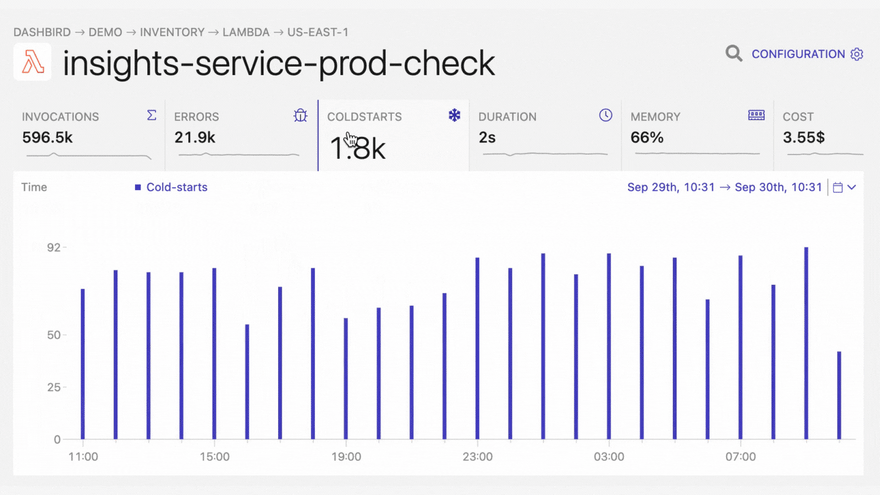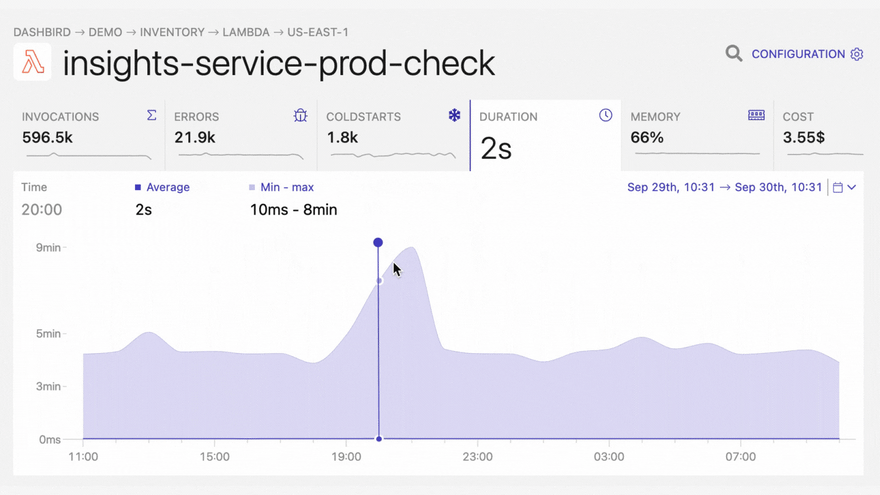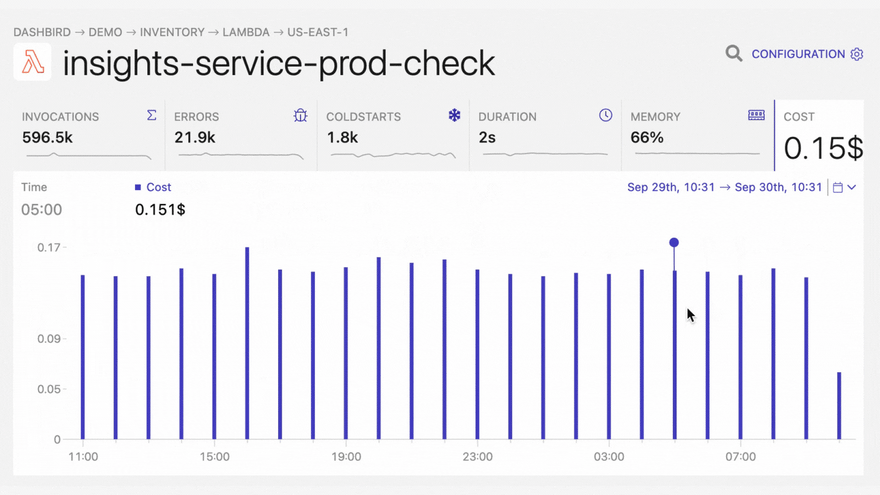
It's important to note here, that most of these errors don't get reported by default. In the best-case scenario, you will notice them in the CloudWatch metrics dashboard, if you happen to have it open. Also, failures that happen outside the program execution are difficult or impossible to be picked up by agents, since the execution is halted before it reaches the handler or from an upper level. A good solution to that problem is detecting these problems from CloudWatch logs. Using Dashbird - an easy-to-set-up serverless monitoring tool - on top of that makes it super easy and fast to detect errors and troubleshoot them in one place.
With Dashbird you'll be able to track your Python errors while getting an overall view of the status of your application. Once you have finished setting up your account you'll be able to see every function invocation, live tailing, error reports, cost breakdown, and much much more.
The good thing about Dashbird is that it has zero effect on your Lambda performance or AWS cost. It also integrates with your Slack, Pagerduty (via webhooks), or email account, which brings alerting right to your development chat.
Conclusion
This covers much of what you need to know about error handling in AWS Lambdas. Learn more about AWS Lambda errors and how to solve them in our Events Library.

Top comments (0)