
This simple FastAPI service will help you find data in a data lake

Photo by nine koepfer
Data lakes provide a myriad of benefits. They are data agnostic and don't require you to define a schema upfront. However, without a proper structure, it may be challenging to find the data that you need. In this article, we'll address this problem by creating a FastAPI abstraction allowing us to query the AWS Glue metadata catalog.
Why FastAPI for a data discovery service?
If we would implement it as a Python package instead, we would assume that everyone knows enough Python to use it. However, your company may have other developers (Java, C#, JavaScript, Go, ...) that need access to data from a data lake. By building a REST-ful service for data discovery, you are providing a programming-language agnostic interface for everyone. This API-first approach has further benefits:
- If you later decide that you want to build a UI for business users, your task will become much easier since you already have a REST API that provides data as JSON.
- You can combine all the functionality for this purpose in a* single service*.
- If you need to add new methods or change the existing ones, you can deploy changes easier by creating a new API version (ie, api_url/v3) without breaking any workloads that depend on the current version.
- You can extend the functionality to include real-time data streams, unstructured data, as well as to allow querying access logs to identify which data is used most frequently and by which users.
How do we start?
We can start by listing all the methods that can be potentially useful for data discovery:
- listing all databases or schemas,
- listing all tables for a specific schema,
- filtering for table names with a specific prefix or suffix,
- doing a full-text search on table names (say, all tables that have anything to do with orders or customers),
- doing a full-text search on table comments (ex., if we want to find any column related to logistics),
- showing a full table definition (all columns, data types, and column comments),
- showing partitions for a specific table,
- showing all files from S3 below a specific partition,
- showing all columns with specific comment,
- showing all tables that contain a specific column name,
- finally, the best way for data discovery is to just look at the first X rows of a full table.
How can we translate this to Python code?
We have three choices: either using lower-level AWS SDKs, doing queries on Athena's information_schema, or leveraging awswrangler. In the end, we may combine all of them to satisfy the requirements from the previous section.
1 - To list all databases (i.e., schemas) and tables, we can use the awswrangler package, especially the module wr.catalog.

2 - To filter for table names with a specific prefix or suffix, we can also use wr.catalog.tables. The same is true for retrieving table definition and doing a full-text search on those definitions:

3 - List all partitions of a specific table:

4 - Show table's DDL:

5 - List S3 directory path or show specific objects according to file type (ex. parquet files) and last modified date:

6 - Query column comments to find the dataset that you need:

7 - Describe Athena table definition:

8 - Search for specific column names:

The above methods constitute a basic MVP for a data discovery service. It allows querying schemas, tables, columns, column comments (aka data dictionary), showing a preview of the data, as well as exploring the underlying files, directories, and partitions.
By leveraging services such as AWS X-Ray and Lake Formation, we could add methods to query usage access patterns and identify the most and the least used datasets.
Side note: If you don't want to attach your boto3_session separately in each API method, you can attach a global session using:

Implementation: FastAPI MVP
The full code for this MVP can be found in this Github repository. Let's briefly discuss some of the details.
In the following demo, we can see all the endpoints applied on a Brazilian E-commerce dataset from Kaggle.
The screencast above demonstrates how we can use this API to discover and query e-commerce data stored in an S3 data lake. The end users can identify tables or schemas that they need. By drilling down into the underlying files, data scientists and analysts can explore this data in an interactive notebook or other tools of their choice. Reading a specific parquet, CSV, Excel, or JSON file from S3 with awswrangler is as simple as:

How can we serve this API at scale?
There are several options to deploy a REST API. If you already use AWS, you may find it useful to leverage serverless services built specifically for building resilient and scalable APIs: AWS Lambda and API Gateway.
With the excellent package called mangum, converting our FastAPI to a Lambda handler is as simple as importing this package (from mangum import Mangum) and adding a single line of code: handler = Mangum(app=app).
The Dockerfile to deploy the API to AWS Lambda looks as follows:

We use the official Python Lambda image with Python 3.8 and install all required packages. Then, we copy our remaining API code and specify the Lambda handler that will be used as an entry point to our container.
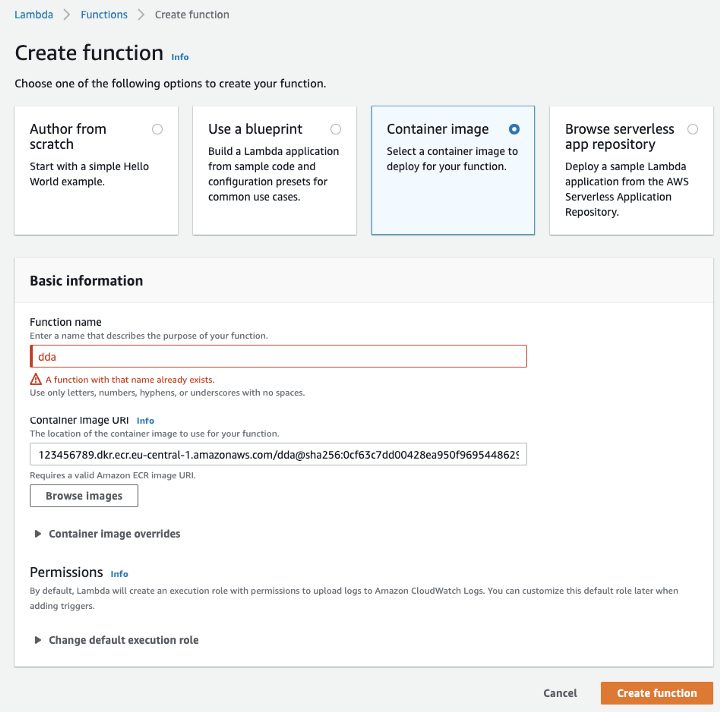
Finally, we have to push the container to ECR --- AWS container registry. To replicate this demo, replace 123456789 with your AWS account ID, and adjust your AWS region name. In case you're wondering: dda is my abbreviation for data-discovery-api.

AWS Lambda
The container image is deployed to ECR. Now, we need to create a Lambda function. We choose the container image option and select our ECR image.
Since querying some tables can take longer than Lambda's default timeout of just three seconds, we can extend it to three minutes.
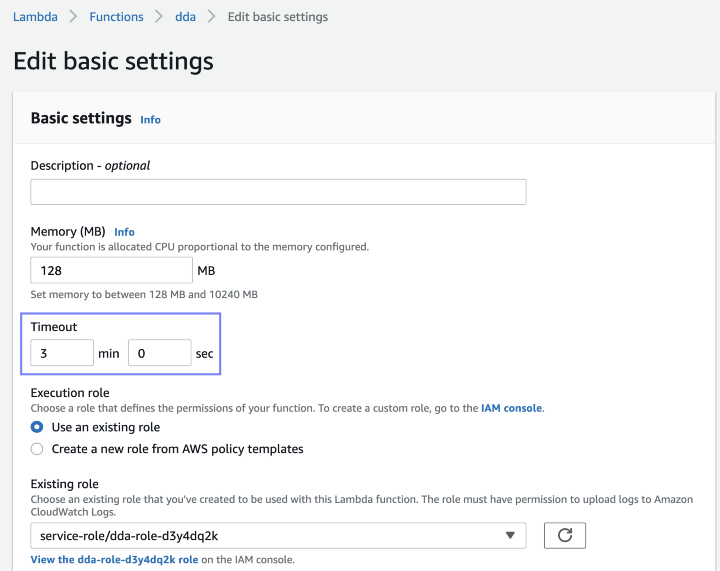
Finally, we need to attach IAM policies to grant our Lambda function permissions to retrieve data from AWS Glue, Athena, and S3 (of course, we should use more granular permissions for production).

API Gateway
After configuring the Lambda function with our container image, we can create a new API in the API Gateway console. We need to choose REST API and specify a name.

Then, we can add a method and resource to configure Lambda Proxy integration.

Once all that is set up, we can deploy the API and start serving it.
To see it step by step, here is a screencast that demonstrates API Gateway configuration, deployment, and testing the API:
How can we monitor our data discovery service?
Imagine that you deployed a similar service at your company and it turned out to be a resounding success. Now you need to ensure that it stays healthy, can be easily maintained, and runs without errors. At this point, you can either:
- Keep an eye on it manually (not recommended),
- Build an observability dashboard yourself by using AWS CloudWatch and related services,
- Make use of observability tools such as Dashbird.
The implications of each option:
- With option #1, you will likely go mad.
- With option #2, you would have to spend extra time building CloudWatch dashboards, jump between several CloudWatch logs and multiple AWS console tabs to fix any potential bugs.
- With option #3, you only have to sign in to your Dashbird account --- it automatically scans all serverless resources and provides you with visualizations you need to track the health of your APIs and microservices. You can then optionally (highly recommended!) build a project dashboard by combining API Gateway and Lambda resources, and set alerts on failure.

In the image above, we can see how Dashbird pointed out the task which timed out after 3 seconds (default Lambda timeout). It also reveals when the Lambda function experienced a cold start and shows the duration for each API call.
For API Gateway, we can see the average latency, number of API requests, and different types of errors that we encountered in the initial testing of the API.

Conclusion
In this article, we investigated how we can build a REST-ful service for data discovery. By leveraging Python libraries such as FastAPI, awswrangler, boto3, and Mangum, we can build useful APIs in just a few hours rather than weeks. Additionally, by deploying this service to API Gateway and Lambda, we can serve this API at scale with no operational headaches. Lastly, by leveraging Dashbird, you can add observability to your serverless resources without having to install any CloudWatch agents, pulling logs, or building any dashboards.
Thank you for reading! If this article was useful, have a look at related articles:





Top comments (0)