
Recently, I had to develop a full text search with Apache Solr for the LOCALLY CMS in CakePHP 3 and what an adventure that was! The reason being is that it is important that users are able to search for all information relating to Locations and impressions in our Location Intelligence and Consumer Engagement Platform (LOCALLY Engage)
If Solr is a complete new world to you, as it was to me when I started developing this, here is a quick definition about what Solr (It is pronounced “Solar”) is, provided by Solr project:
Solr is highly reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. Solr powers the search and navigation features of many of the world's largest internet sites.
Solr Integration with CakePHP

The diagram above, illustrates perfectly what I had to do in this task. So, in order to integrate Solr with other server applications for a search, such as LOCALLY CMS, basically we have to:
Define a schema
Deploy Solr
“Feed” Solr with the documents that the users will search
Create a link between Solr and CakePHP via Solarium PHP Solr client library
Implement the search in the CMS
I have a lot to share about all I’ve been working to achieve this task, so I will divide this in a few blog posts. In today's post, I will talk about Solr Core Configuration for the version 6.6, when Solr is configured to work with multi cores.
Full Text Search: Single core or multiple cores?
When you have a relational database, maybe your first choice would be having multiple cores, one for each searchable table of our database, which makes sense. However, we had some things to consider before making this choice:
Solr isn’t relational, all the searchable words are stored in an "inverse index" and this is what makes it so fast;
Multiple cores means multiple configuration, indexation and maintenance;
If you use multiple cores, at some stage you might need to “join” your data.
Our decision at LOCALLY was to have only one core “Search” configured. So, all the searchable data provided by our database tables was imported as documents in Solr using Data Import Request Handler.
Single core configuration
Solr is configured using XML files. For creating a single core in Solr, some files must be configured previously, basically: solrconfig.xml, schema.xml and data-config.xml. I won’t get in the details about solrconfig.xml once this file should work fine with Solr default configuration and no changes were needed for this task.
data-config.xml
This file is where we specify what is the source of our documents, as I mentioned before this was made using the Data Import Request Handler, getting the indexes from MySQL tables. All the configuration must be between tags.
Specifying the dataSource of the documents, a simple JDBC connection with MySQL.
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://HOST/DATABASE"
user="USER"
password="PASSWORD" />
For the entity and fields configuration, I used a database View instead of specify multiple tables and all its fields, because we’ve decided to have a single core. Plus you don’t want nobody searching in fields with sensitive information such as password, credit card and tokens, right?! So, also for safety reasons, a view was my choice.
Between the tags we specify another tag where we specify the table name (a view in our case) in the attribute name, primary key in the attribute pk, in the attribute query, a SQL query can be informed.
Inside the tags , we specify the fields of our query that will be visible in Solr after indexing the documents. The attributes column and name are essential.
Here is an example of this configuration.
<document>
<entity name="MyView"
pk="id"
query="SELECT * FROM MyView">
<!-- Fields that will be returned by the query -->
<field column="id" name="id"/>
<field column="name" name="name"/>
<field column="created" name="created"/>
<field column="modified" name="modified"/>
...
</entity>
</document>
And a complete example of data-config.xml.
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://HOST/DATABASE"
user="USER"
password="PASSWORD" />
<document>
<entity name="MyView" pk="id" query="SELECT * FROM MyView">
<!-- Fields that will be returned by the query -->
<field column="id" name="id" />
<field column="name" name="name" />
<field column="created" name="created" />
<field column="modified" name="modified" />
...
</entity>
</document>
</dataConfig>
schema.xml
This is another file with default configuration, but there are specific some points I’d to highlight and they are essential to have a full text search configured.
This file starts this way:
<?xml version="1.0" encoding="UTF-8"?>
<schema name="example-data-driven-schema" version="1.6">
<uniqueKey>id</uniqueKey>
...
</schema>
First important point in this document, the tag id must be specified. This is the same field specified in <entity name="MyView" pk="id"></entity> and the same of <field column="id" name="id" />.
The other fields of our entity (query) are informed in this format:
<!-- Query Fields -->
<field name="id" type="int" indexed="true" stored="true" />
<field type="string" indexed="true" stored="true" name="name" />
<field type="date" indexed="true" stored="true" name="created" />
<field type="date" indexed="true" stored="true" name="modified" />
For allowing the full text search, that means, the ability to search in any field of our documents, a special field can be informed, in our case the field name text will do the trick, this field is of text_general type, it’s multi valued which allows this field receive multiple values in different formats and types and not stored. After this, we can use a copyField, defined by the tag , this is equivalent to “say” to Solr:
For any index found ( source="*" ) , copy the result to the field ( dest="text") and return the result.
<field name="_text_" type="text_general" multiValued="true" indexed="true" stored="false"/>
<copyField source="*" dest="_text_"/>
Creating the core in Solr
With the files configured, we need to create the following folders in the Solr Server, where “Search” is the name of our core:
/path/to/solr/data/Search
/path/to/solr/data/Search/conf
/path/to/solr/data/Search/data
In /path/to/solr/data/Search/conf, we will place our 3 files: solrconfig.xml, schema.xml and data-config.xml and any other config files such as currency.xml, elevate.xml, etc.
Now, in the Solr Server, in the Core Admin, create a new core called “Search”:
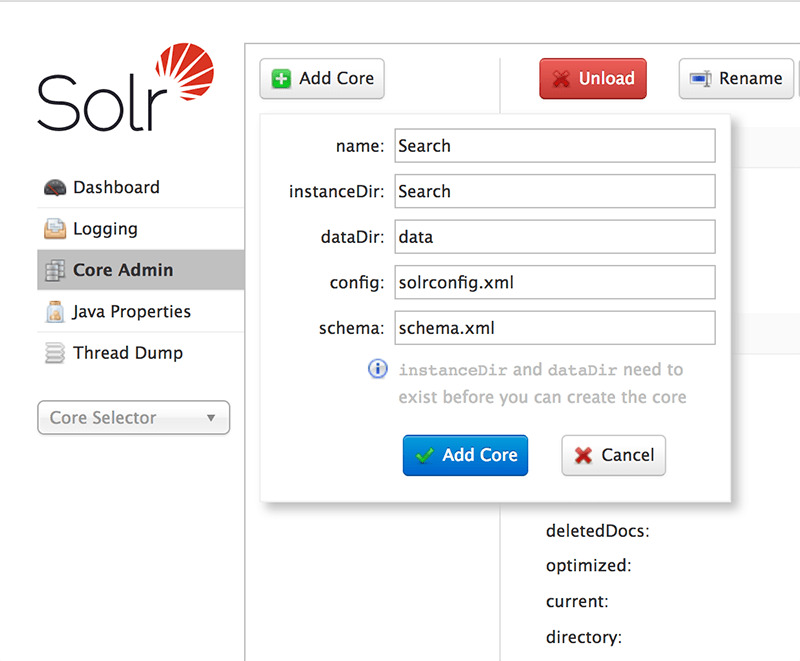
After that, select the core created in the Core selector and navigate to DataImport and execute a full import, for this, select the command “full-import” and click on the button “Execute” and after that “Refresh Status”. Alternatively, you can also check the “Auto-Refresh Status” field and then won’t be necessary click on “Refresh Status”. The response should be similar to this:

Performing a simple query:

That’s all for this post!
In the nexts blog posts I will keep talking about these points:
Solarium PHP Solr client library: Connection, Search options, returning results.
CakePHP Solr Behavior: Performing a search, adding, removing documents.
Displaying Solr search results in your front-end.

|
Lorena Santana - Platform Developer System analyst/Web development in the last +8 years with different technologies and methodologies. Experience with ERP's, CMS and frameworks such as CakePHP, Bootstrap and Wordpress. Full stack developer, self-taught, expertise in database modeling and maintenence, also in requirements gathering. Experience with agile methodologies and work well under pressure. Experience with interns.
|

Top comments (0)