
API gateway is an architectural pattern of a service that sits between a client and the internal backend services.
The gateway accepts all the client's requests and proxy them to the correct service, or even to multiple services in some cases.
It's used to implement centralized solutions for authenticating requests, rate limiting, collecting statistics, and limiting public access to a single point of entry.
Pros
Authentication
Having a single point of entry means that you can authenticate requests before proxying them to internal, and sometimes sensitive, backend services. The authentication logic doesn't have to be duplicated around different services and can remain only in the API gateway.
Rate limiting
You may want to limit the number of requests the users generate to your server to reduce the load. Instead of implementing this mechanism in every service, you can simply implement it once in your API gateway. It can be super handy to prevent a DDoS attack or a malicious user trying to break your system.
Single point of entry
In terms of security, this point is super important. If you follow strict enterprise standards, you may need to monitor the data that goes in and out of your system. Having a single point of entry to the system will make this task much easier. Only one service that needs to be monitored.
There are more advantages but they all rely on the fact that there is a single point of entry so you can implement any logic that you want only once. No need to move it around to other services.
Cons
Performance
When introducing a middle-man between the client and the actual service that fulfills the request, there will always be a performance overhead. The request has to go from the client to the API gateway. From there, continue to the service, go back to the API gateway and then to the client. You can reduce the round-trip time by streaming the requests and making sure the API gateway and the services are in the same zone (in the cloud provider). Nevertheless, there will be always a performance overhead.
Single point of failure
A single point of entry also means a single point of failure. If the API gateway is down, all clients will not be able to use the system. You will have to make sure this cannot happen and heavily monitor the API gateway. Otherwise, you have a ticking bomb in your system.
My decision
As I started breaking daily.dev monolith to smaller services, I added a custom API gateway. My main reason was to handle authentication in a centralized manner.
It was good for a while, but at the end of the day, I could not bear the idea that it affects my system performance. I have distributed tracing in place so I knew it for sure.
Last week, I decided to break the API gateway pattern and expose other services as well. The performance cost was too much to bear. It turned out great, at the end of the article I share some stats.
It's important to highlight that for every use case there could be a different solution, I'm just sharing my story here. It doesn't mean you have to remove your API gateway as well.
Breaking the gateway
Honestly, it was not hard to accomplish but a scary journey for sure. There was not much of a logic going on in the API gateway besides proxying requests and authenticating them. So I had to think about solving these two issues only. I made this proof of concept on my GraphQL service.
Authentication
Our authentication system is based on a JWT token that is stored in a cookie. The main benefit of JWT is that it's a stateless token. You don't need a database to verify the token, all you need is the key that it was signed with. I duplicated the JWT token verification function in the gateway to my GraphQL service so it can handle authentication by itself. This part was easy and straightforward.
Proxying requests
Now for the scary part. I needed to expose my GraphQL service to the public without changing the client or introducing any downtime. I manage my infrastructure on Kubernetes so there is only one way to expose services, Ingress. The ingress resource defines how to route external traffic between internal services. Behind the scenes, it creates a Google Cloud Load Balancer. Ingress supports a path-based routing so this was perfect for me.
One thing I knew, changing ingress settings can take a few minutes and can cause downtime. So changing the production ingress is out of scope. I decided to create a new ingress, test it, and then do the switch.
Here is the new ingress config, I don't want to go into details as it's out of scope but you can see the path-based routing. By default, requests are proxied to the gateway and but GraphQL requests are going to the API service.
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.global-static-ip-name: daily-ingress-ip
labels:
app: daily
name: daily-ingress
namespace: daily
spec:
rules:
- http:
paths:
- path: /*
backend:
serviceName: daily-gateway
servicePort: http
- path: /graphql
backend:
serviceName: daily-api-v2
servicePort: http
tls:
- hosts:
- app.dailynow.co
secretName: app-dailynow-co-tls
- hosts:
- api.daily.dev
secretName: api-daily-dev-tls
Once I deployed the new ingress, I set my local hosts file to point api.daily.dev to the new ingress so I can test it locally. I did some manual checks and confirmed that this new setup works, including the authentication.
I then proceeded with changing the DNS to the new ingress's IP. Only after a few days, I decided to remove the old ingress. Changing production infrastructure takes time and requires patience, don't rush it.
I made it! Did the switch with no downtime 🚀
Show me some stats!
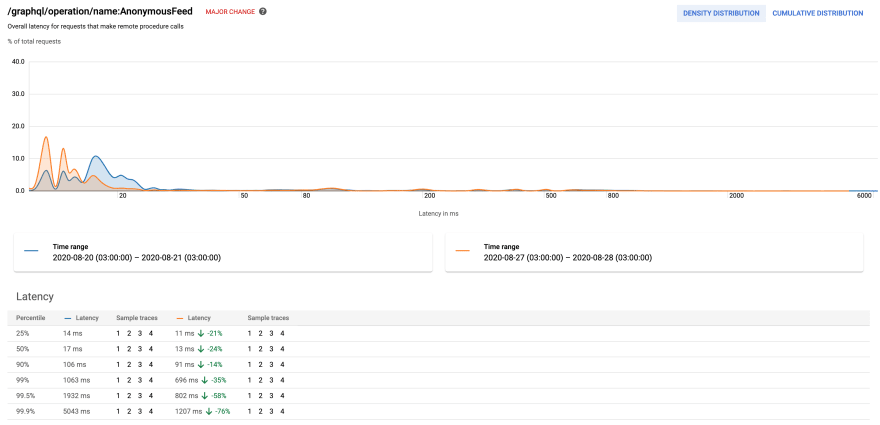
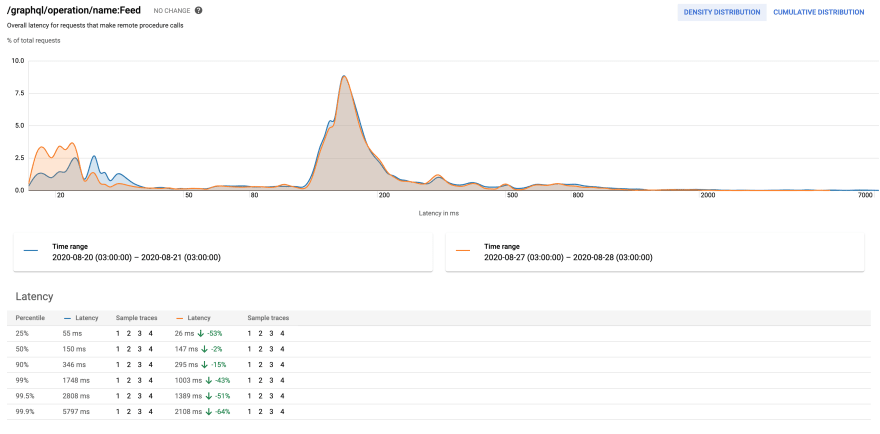
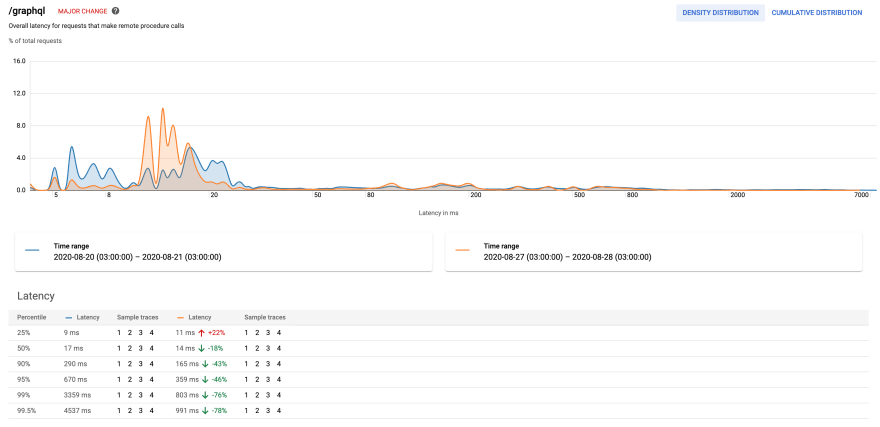
You did all this way just to see some stats, I know it! So here we go, I did 3 different comparisons:
- Performance of our anonymous feed which is the most popular request for non-registered users
- Performance of our registered-users feed which is the most complex query in the system
- Performance of the GraphQL route. It's a comparison that shows the overall trend of this change.
The charts compare the performance after the change to the performance before the change at the same time of the week.
Looking forward to hearing your thoughts ✨
Daily delivers the best programming news every new tab. We will rank hundreds of qualified sources for you so that you can hack the future.






Top comments (2)
From kubernetes.io:
Ingress
FEATURE STATE: Kubernetes v1.19 [stable]
An API object that manages external access to the services in a cluster, typically HTTP.
Ingress may provide load balancing, SSL termination and name-based virtual hosting
So you have "middle-man between the client and the actual service" ...
You are right. Ingress is a middle-man between the client and the actual service but it's inevitable.
To make sure my app is highly available I must use a load balancer (ingress) which is a different component than an API gateway although modern load balancers might have some API gateway features.
Before I had client -> ingress -> gateway -> service. Now it's client -> ingress -> service.