
TL/DR
Logstash + Rust = Vector ?
We can actually describe Vector as a Logstash built in Rust, with all the language’s advantages for free (high performance, cross-compilation), but the flaws of a still young product (few modules, no known references). Note that the documentation seems well done, and the first existing modules allow you to manage a lot of simple monitoring use-case. As we can agree that Logstash is not the best product in the world, let’s hope that Vector will find its place in the community in the coming months. In addition, Vector natively offers modules equivalent to the Logstash’s one, which means that the migration will not be complicated!
And so what ? We have time, right ? #LockedDown
Vector could be defined as an high-performance observability data router that makes transforming, collecting, and sending events (logs & metrics) easy.
Concept
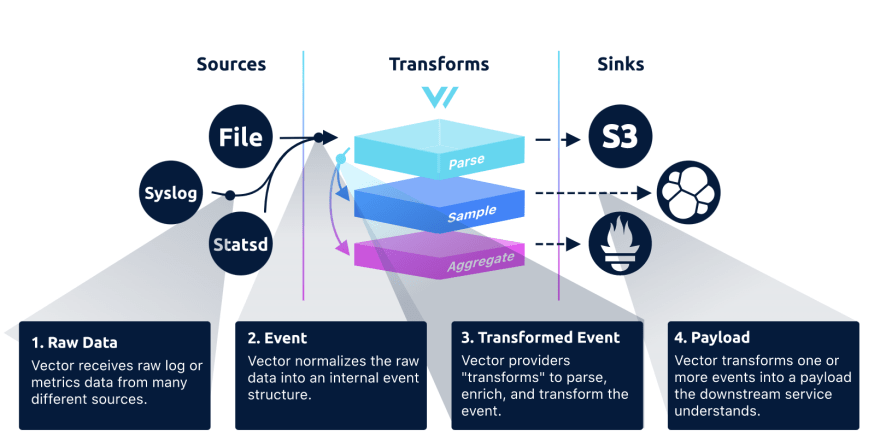
Basically, it’s an ETL based on the following concepts:
- Source (aka. E / Extract)
Reading raw data from the source.For example, we could read log into a file, listen a Kafka topic or get StatsD metrics
- Transform (aka. T / Transform)
Transform raw data, or complete data stream.For example, we could filter entries or parse a log using a regular expression
- Sink (aka. L / Load)
Destination for events. Each module’s transmission method is dictated by the downstream service it is interacting with (ie. individual events, bulk or stream). For example, we could save raw data into Amazon S3, indexing them into Elasticsearch or expose to Prometheus
Features
Fast
Built in Rust, Vector is fast and memory-efficient, all without runtime or garbage collector
One only tool, from source to destination
Vector is designed to be used by everyone, whatever the context, by offering several deployment strategies:
In this case, it serves as serves as an light-weight agent by running in the background, in its own process, for collecting all data for that host.

Here, it serves also an an agent, but we will have one process by service. 
In ths case, Vector is a separate service designed to receive data from an upstream source and fan-out to one or more destinations. 
By using and/or combining theses strategies, we can define several architecture topologies to collect our data.
In this topology, each Vector instance will directly send data to downstream services. It’s the simplest topology, and it will easily scale with our architecture. However, it can impact local performance or lead to data losses. 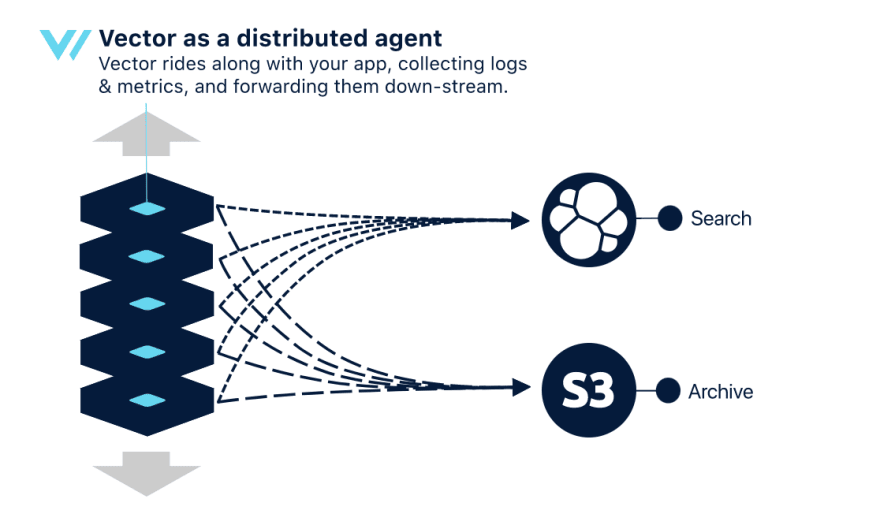
Here, each agent will send data to a dedicated centralized Vector instance, which will responsible to do the most expensive operations. So, it’s more efficient for client nodes, but a dedicated centralized service as a SPOF which could lead to data losses. 
Variant of the previous topology, in which we will add a broker upstream of the centralized service in order to remove the SPOF. This topology is the most scalable and reliable, but also the most complex and expensive. 
Easy deployment
Built with Rust, Vector cross-compiles to a single static binary without any runtime.
Well, but does it really works ?
I will be inspired by a previous blog post :

 Proof of concept architecture
Proof of concept architecture
In this case, we will use:
- Elasticsearch, search engine which provide full text search & analytics,
- Kibana, which provide an UI for exploring data, and create interactive dashboards
- Vector, as central service, to transform events and sending them to Elasticsearch,
- Kafka, as an upstream broker
- Vector, as an agent, to ingest raw source data and sending them to Kafka
So here, we are under a Stream based topology
Services and interactions are described in a docker-compose.yml file:
The Vector central service is configured as below:
- Reading events from Kafka
- JSON Parsing from events send by Vector agent
- Grok Parsing (same as Logstash Grok format) from raw log line
- Indexing into Elasticsearch
Fun fact, we can unit testing our configuration, as we can see in the [[tests]] section.
Note that each configuration step is based on at least one previous step.
On our webapp side, we will have an Vector agent configured as below:
- Reading logs from file
- Sending them to Kafka
Complete projet is available on github
Now, I can start all my services with docker-compose:
docker-compose build
docker-compose up
Then, you should be able to access the web app (http://localhost:80, in my case)  Web Application example (source: https://github.com/sbilly/joli-admin)
Web Application example (source: https://github.com/sbilly/joli-admin)
After few minutes browsing, you can go to Kibana UI. (in my case, http://localhost:5601), then click on Management tab, then Kibana > Index Patterns
 Adding vector-* index pattern
Adding vector-* index pattern
Here we go ! A vector-YYYY.MM.DD index should be created with my application logs.From there, I will be able to create my searchs, visualizations, dashboards or canvas in Kibana, and use all theses informations.
To conclude, it’s actually quite easy to use Vector as a substitute for Logstash/Beats in an Elastic stack, and it works.Remains to see if performance gains are real, and if the project can resist in the future and become a real alternative for the community.Until then, even very young, this project is full of promises and good ideas (unit tests, multi-topologies, …), and so deserves that we take a look!

Top comments (0)