
TL/DR
En 2 briques,
Logstash ? ETL !
Rust ? Vector !
On peut effectivement décrire Vector comme un Logstash qu’on aurait réécrit en Rust, avec tous les avantages inhérents au langage (performance, binaire natif), mais les défauts d’une solution encore très jeune (nombre de modules limités, peu de références). On notera que la documentation semble plutôt bien faite, et que les composants natifs permettent de gérer beaucoup de use-case simple de monitoring. Et comme on peut convenir que Logstash n’est pas le meilleur produit du monde, espérons que Vector trouve sa place dans les prochains mois dans la communauté. Et en plus, ca tombe bien, Vector propose nativement des modules équivalents à ceux de Logstash, ce qui fait que la migration ne sera pas compliquée !
Après-tout, on a le temps non ? #Confinement
Vector se défini comme un routeur de données d’observabilité haute-performance, qui permet la collecte, la transformation et l’envoi d’évênements (logs et/ou métriques).
Fonctionnement conceptuel
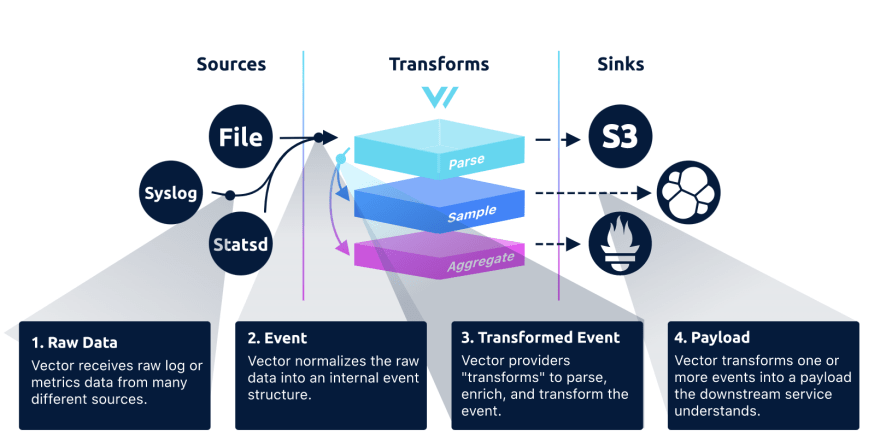
Il s’agit basiquement d’un ETL qui s’appuie sur les notions suivantes:
- Source (aka. E / Extract)
Récupération des données brutes depuis l’endroit où elles sont produites.
Par exemple, on pourra lire les logs dans un fichier, écouter une file Kafka ou récupérer des métriques de StatsD
- Transform (aka. T / Transform)
Transformation des données brutes, ou du flux complet de données,
Par exemple, on pourra filtrer des entrées ou encore parser un log selon une expression régulière
- Sink (aka. L / Load)
Destination des données lues et transformées. Chaque module enverra les données de manière unitaire ou sous la forme d’un stream en fonction du service cible.
Par exemple, on pourra sauvegarder les données brutes sous Amazon S3, les indexer dans un cluster Elasticsearch ou les exposer à Prometheus
Fonctionnalités
Rapide
Ecrit en Rust, Vector est très rapide avec une gestion efficiente de la mémoire.Le tout sans runtime, ni garbage collector.
Un outil unique, de la source à la destination
Vector propose plusieurs stratégies de déploiement afin de pouvoir être utilisé par tous, quelque-soit le contexte.
Ici, on lancera une instance de Vector en tâche de fond pour collecter toutes les données du serveur hôte

Dans cette stratégie, on lancera une instance de Vector par service à monitorer.

Ici, Vector est lancé en tant qu’un service dédié.

En utilisant et/ou combinant ces stratégies, on peut donc définir des topologies d’architecture de collecte de données
Dans cette topologie, chaque instance de Vector va directement envoyer les données au(x) service(s) cibles. Il s’agit du cas le plus simple, et qui permet de scaler facilement. Néanmoins, il peut induire des pertes de performance locales ou de données.
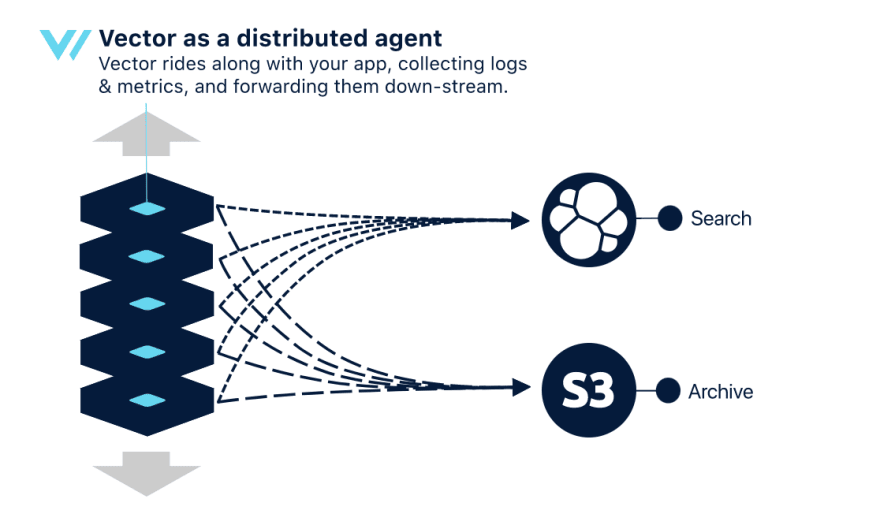
Ici, chaque instance de Vector va envoyer les données à une instance centrale, chargée d’effectuer les opérations les plus coûteuses. De fait, moins d’impact sur les performances locales des applicatifs, mais un service centrale en tant que SPOF

Variante de la topologie précédente, dans laquelle on va rajouter un broker en amont du service centrale afin de supprimer le SPOF. Cette topologie est la plus scalable et durable, mais aussi la plus complexe à mettre en place.

Simplicité de déploiement
Concu en Rust, Vector se présente donc sous la forme d’un binaire cross-compilé pour l’os cible, et ne nécessite pas de runtime type JVM
Bon, OK, mais ca marche au moins ?
Pour tester Vector, je vais m’inspirer d’un post précédent :

 Architecture de notre POC
Architecture de notre POC
Dans le cas présent, je vais m’appuyer sur :
- Elasticsearch, comme moteur d’indexation, de recherche & d’analytics,
- Kibana, comme IHM de visualisation et de génération de tableaux de bord interactifs
- Vector, en tant que service central, pour transformer les données et les envoyer vers Elasticsearch,
- Kafka, en tant que broker en amont de ma stack de monitoring
- Vector, en tant qu’agent, pour récupérer les données sources et les envoyer vers Kafka
On se positionne donc dans la topologie de Collecte Streamée décrite ci-avant
L’ensemble des services et des interactions sont décrites dans un fichier docker-compose.yml:
Le service central Vector est configuré comme suit:
- Lecture des événements depuis le broker Kafka
- Parsing du JSON de l’événement envoyé depuis l’agent Vector
- Parsing Grok (format Logstash) de la ligne de log brute
- Indexation vers Elasticsearch
Fun fact, il est possible de tester unitairement la configuration avec Vector, comme on peut le voir dans la section [[tests]] du fichier
On pourra également noter que chaque step de configuration se base sur au moins un step précédent.
Côté webapp, on ajoute un agent Vector configuré comme suit:
- Lecture des logs depuis un fichier
- Envoi vers le broker Kafka
Le projet de test complet est disponible sur github
Il ne me reste qu’à lancer tous mes services
docker-compose build
docker-compose up
Puis me rendre sur ma webapp (dans mon cas, http://localhost:80)
 Exemple d’application web (source: https://github.com/sbilly/joli-admin)
Exemple d’application web (source: https://github.com/sbilly/joli-admin)
Après une rapide navigation, je peux me rendre sur mon IHM Kibana (dans mon cas, http://localhost:5601), puis dans l’onglet Management puis Kibana > Index Patterns
 Ajout du pattern d’index vector-*
Ajout du pattern d’index vector-*
Et voilà ! Un index vector-YYYY.MM.DD a été crée et contient bien mes logs applicatifs. A partir de là, je vais pouvoir créer mes indexs, recherches visualisations, dashboards et autre canvas dans Kibana, et pouvoir utiliser ces informations de monitoring.
Pour conclure, il est effectivement assez facile d’utiliser Vector comme remplaçant de logtash/beats dans une stack Elastic, et le fait est que ca fonctionne. Reste à voir sur la durée si les gains de performance annoncé sont réels, et si le projet arrive durablement à s’imposer dans la communauté. En attendant, même très jeune, ce projet est plein de promesses et de bonnes idées (tests unitaires, multi-topologies natives, …), et mérite donc qu’on y jette un oeil!

Top comments (0)