EDIT: After both nights of the debate concluded I did a more thorough write up. I'd encourage you to check that out.

If you're watching the debate tonight and thought "how can I analyze the transcript data from this?" Here's some starter code to parse the transcript simply and easily.
import pandas as pd
import sklearn as sk
import requests
import bs4
# http request
r = requests.get('https://www.washingtonpost.com/politics/'
'2019/07/31/transcript-first-night-second-democratic-debate')
r.status_code
# Parse html
soup = bs4.BeautifulSoup(r.content)
graphs = soup.find_all('p')
utterances = [x.get_text() for x in graphs if 'data-elm-loc' in x.attrs.keys()]
# Parse utterances
utterances = utterances [2:]
seq = 0
data = []
for i in utterances:
graph = i.split()
if graph[0][-1] == ':':
text = ' '.join(graph[1:])
num_words = len(graph) - 1
name = graph[0][:-1]
seq += 1
elif len(graph) > 1 and graph[1] == '(?):':
# Cases like 'WARREN (?):'
text = ' '.join(graph[2:])
num_words = len(graph) - 2
name = graph[0]
seq += 1
else:
text = ' '.join(graph)
data.append({"name": name,
"graph": text,
"seq": seq,
"num_words": num_words})
df = pd.DataFrame(data)
# "Unknown", O'Rourke parsing errors
df = df[df.name != "(UNKNOWN)"]
df['name'] = df['name'].apply(lambda x: ''.join([char for char in x if char.isalpha()]))
# Example...
df.groupby('name').sum()['num_words'].plot(kind='bar')
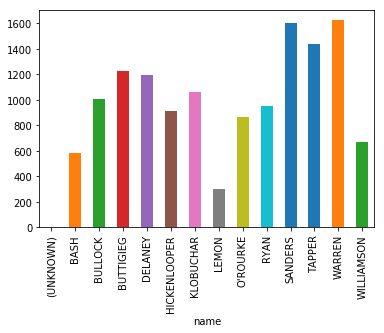
(Image taken mid-debate, those are not final numbers)
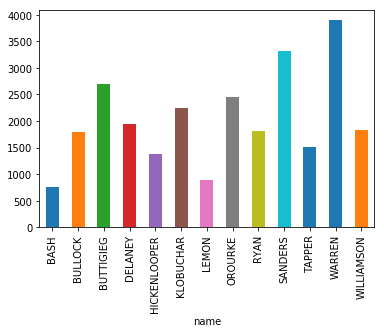
(Cleaned, post-debate numbers)
You can quickly get started with this code and more in an interactive notebook on Kaggle:
https://www.kaggle.com/charleslandau/democratic-debate-analysis-quickstart





Top comments (0)