
A long time ago I gave up on knowing anything about coding, tech, or development. Knowing things takes a long, long time.
My memory is not great and even if it was, it's hard to justify technical decisions with "...well I remember the docs said xyz." So I gave up on remembering things too.
Nonetheless, I want to explore and learn about new tools constantly. I want to be unconstrained in the solutions I compose. The only way I can live like this is to cheat a little bit.
The Greedy Part
"Greedy learning" is a mental model for rapid adoption of new technologies. It essentially means that we start with the laziest, most intuitive search, and graph everything from that point on.
The root node of the graph is you, because we're being greedy. The only intermediate node before we do a search is your intent. Let's say that we want to perform web requests in Python.
Our initial knowledge graph is:
self -> intent:"web requests python" -> search
Most of the time, you will perform the search on a public search engine, the intranet at your job, or a REPL. If you are very fortunate, you may have an "enterprise search" tool like Spotify Lexikon that makes intent-based search trivial. Regardless, at this step you must become as lazy as you possibly can.
For example, I have found that if I am interested in a topic, I can write awesome at the beginning of a search and I will often find an awesome list about it. Just like that, we have many subgraphs to explore.
search results "awesome data engineering" ->
intent:"explore_subgraph" ->
root_graph_update:new_search
Likewise, if I think I can guess the answer, my search may begin at the REPL, where I test my guess, and the error messages I invariably generate become new searches.
search results "print foo" ->
errors ->
intent:from_error ->
root_graph_update:new_search
We want to do all of this fast and lazy. We're speed-reading in the F-shape pattern. Everything should make intuitive sense. If it doesn't make intuitive sense, that indicates that we're missing something upstream in our knowledge graph.
To extend our intent:"web requests python" example, something about query parameters may come up which doesn't make intuitive sense. We don't abandon our scanning pattern and start deeply reading, but instead we generate a new intent to update our query parameters subgraph.
Rapid Adoption
At this point you may be thinking that I've created a long-winded manual for competitive Wikipedia surfing. Or a deep rationalization for my NADD. I hope I've done neither, and I think "rapid adoption" is the missing piece that sets this apart.
In as few iterations of greedy learning as possible, we need to learn a schema to satisfy our root intent. Fundamentally, this schema defines an actionable subgraph of nodes. Ideally, each root_graph_update modifies the schema, or we come to our problem with clear expectations. As quickly and as lazily as possible, we have a minimum actionable subgraph. Again, our "no memory or knowledge" assumption doesn't require us to start from scratch. It is perfectly valid to start with a schema that is intuitive so long as you update it frequently based on search results and your use case.
A Complete Example
(Full graph on Whimsical)
We'll begin with a basic root_graph as described above, for our example of a web request client in Python.
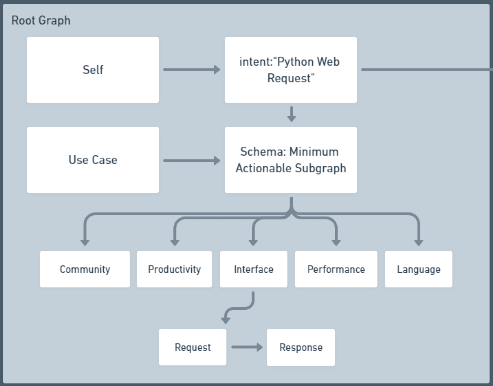
We have an intuition that a good tool for us will have some obvious qualities:
- It will have a strong community of support, such as lots of answers on Stack Overflow, or frequent releases on GitHub.
- It is written in, or has binding for, the language we care about.
- It has the required level of performance.
- It is productive. I certainly struggle to measure the productivity of software libraries. The number of lines of code required to complete a basic task is, perhaps, a good proxy.
- The interface fits our use case. For web requests, we're looking for a way to make the request, and read the response.
- We may also intuit that the response object should have methods like
.status_codeor.jsonbut let's keep our example simple for now.
- We may also intuit that the response object should have methods like
With our schema prepared, we proceed to search.
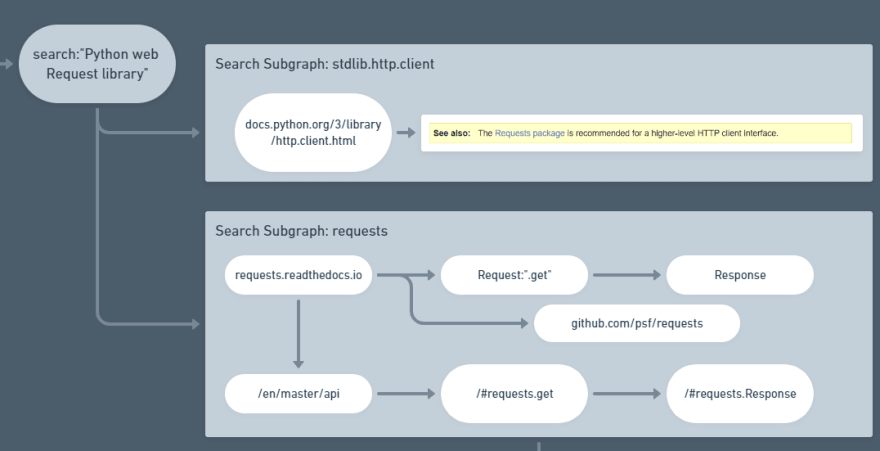
For me, the simplest and most intuitive search for this intent is to just restate the intent and append the word "library", ensuring that I get more results that can be imported, rather than tutorials.
The first thing that jumps out at us is stdlib.http.client — given that we are exceedingly lazy and greedy, we have a strong bias for standard library tools which require no installation.
Upon arriving at the docs, we discover the following callout:
See also: The Requests package is recommended for a higher-level HTTP client interface.
We don't need to read any further. In the terms of Kent Beck's 3X framework, we are firmly in the "explorers" camp. We leave the tab open so we can always come back to this page if the high-level interface doesn't meet our needs, and we move on to the requests package.
The requests docs immediately tell us a couple of things:
- The GitHub for this tool has more than 42,000 stars from developers and it's maintained by the Python Software Foundation, who also maintain Python itself. Strong community ✔️
- That this tool has a
Requestobject andResponseobject ✔️
So, we go hunting for the interface docs, and scanning through the quickstart. Reading a quickstart tells us which features the maintainers consider "core" to their user's experience. This matters because, as explorers, we have a strong preference for finding tools that support the features we care about as a core value, rather than kludges.
With the complete documentation of our Request and Response objects in hand, we are ready get our hands slightly dirty. We can perform a simple validation that the core functions work in a REPL:

At this point we are ready to check our subgraph against the schema. In the schema I outlined, we would do this by asking: Is it productive, performant, and Python? Does it have an interface to the features we need? Is it supported by a healthy community?
In your schema, perhaps none of these questions will matter, and you'll care about something else.
If our subgraph is valid, we can move to adoption. "Adoption" means:
- Slow way down. Up until now we've been trying to go as fast as possible. You could even write unit tests if you want.
- You might even want to stand up and stretch for a while before starting this part. Get into a different mindset.
- With the tabs for each part of the interface open, write the interface calls into our real use case.
- Refer to the appropriate docs actively as you write.
- Run the solution and refer to the open tabs for errors.
- If the solution doesn't work, update the
root_graphaccordingly and resume your search or generate a new search.
Arguments and Persuasion
I should end by warning you that this method has never worked for me where depth is the point. The way I think about this is as a distinction between arguments and persuasion.
- Arguments: making strong logical connections in support of a thesis (as with a knowledge graph). "These are the reasons for this change, and how."
- Persuasion: knowing the audience deeply and speaking to them from a place of radical empathy. "I know you, and what you want is this change."
If there's anything that fits this mental model of arguments, it's interfaces. An API documents a clear argument: Given xyz parameters and abc state, an endpoint /api/v2/users should return an instance of Response/Users.schema. Another example is troubleshooting.
Recording all of this has certainly been interesting for me as an exercise, and I hope you've found it useful. I'm always trying to learn more, so if you have feedback, let me know!

Top comments (0)