
I've been preparing a talk for my local ML user group and as a result I've had to synthesize a lot of ideas. In the talk I introduce a wide variety of "Machine Learning as a Service (MLaaS)" services and talk about how they fit in your toolkit. It's supposed to be a 45 minute talk, so the deck is pretty long... much longer than you would want for a blog post. In this post I'm going to:
- Summarize the heck outta this talk.
- Share the slides at the end.
Note: I am NOT affiliated with ANY product mentioned ANYWHERE in this post.
MLaaS...
...because what the world really needs is another aaS right?
Machine Learning as a Service is a tautology -- it's a label for any service that delivers machine learning. These services offer a variety of advantages to businesses and data scientists, such as:
- Near-State of the Art performance in some cases, without the up-front cost (e.g. training on many GPUs in parallel for many hours). Big Four firms (and their cloud plays) obviously have advantages when it comes to this space, especially in terms of their access to data. (See: Google Natural Language)
- “No Data Science Knowledge Required” and “AutoML” services that enable rapid prototyping and other optimizations. (See: H20 Driverless AI)
- Platforms that enhance time-to-market, optimize cost, or offer simplified integrations with supporting services. (See: Azure ML Studio)
- APIs that map endpoints to ML behaviors like training or prediction. (See: wit.ai)
- Devices that embed ML capabilities (See: Hover2)
Worth it?
There are several considerations to take into account when you're evaluating MLaaS versus "rolling your own" solution:
Cost: MLaaS can seem to offer a way to mitigate the cost of building a Data Science team. Data Scientists, Big Data Engineers, and ML Engineers attract great compensation and benefits, and building a competitive recruitment process for these teams can also be difficult.
Related note: you may avoid a lot of upfront costs with some MLaaS offerings, but per-call or per-use costs tend to bake that in.
Ownership: In many cases taking an MLaaS path means that you don’t fully own and control your models, or that you’re locked in to a platform. Rolling your own can mean having a greater degree of control. On the other hand, a proprietary model from a Big Four shop may be exactly what your organization wants.
Rapid Prototyping: MLaaS offerings can enable a low-cost rapid prototyping approach, especially for organizations that do not have a mature rapid prototyping practice (a skunkworks). In this way MLaaS can extend rather than displace data science capabilities.
Culture: Many organizations seek to build not only a data science team but a "culture of innovation" of which their data science practice is a part. Having a data science team creates an in-house nexus that can advocate for itself and identify lines of business that may not be apparent to other teams.
It's also worth noting that all the typical limitations of each delivery model apply:
Typical limitations of SaaS: you only get their features when they are up (SLAs), supported (LTS), you are budgeted for them ($$$), et cetera
Typical limitations of in-house production: growing pains, recruitment costs, cruft...
Service Categories
To give a better overview of the landscape I pulled out a few categories of services that are out there for you to use. These are non-exhaustive and overlapping categories that map to common use cases.
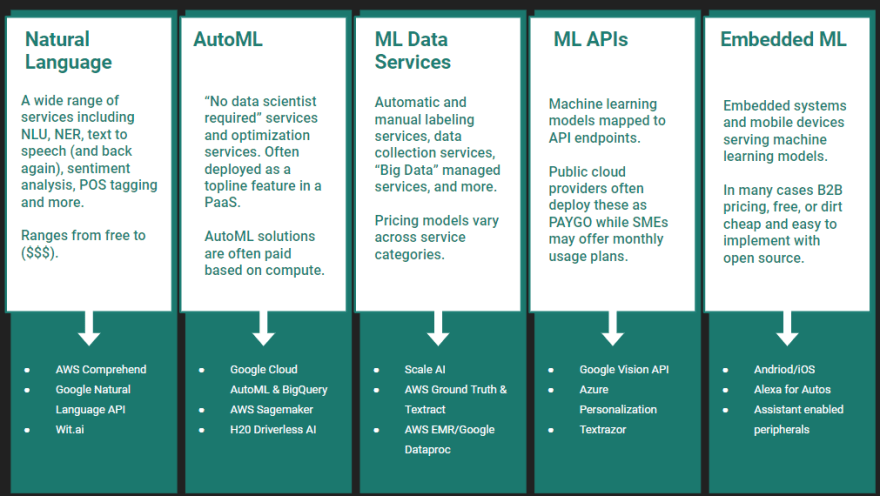
1. NLP Services
NLP is an area where state of the art results are expensive, use cases may lend themselves to generic out-of-the-box solutions, and large enterprises often have better access to data than market entrants. Some services in this category include:
2. AutoML
AutoML and "No Data Science Required" services are developed using techniques like transfer learning, heuristics, Bayesian hyperparameter tuning, platform optimizations, and more. They're probably doing proprietary stuff that we may never even hear about. Services in this category include:
Services in the AutoML space also have begun trying to distinguish themselves using "explainable AI" features. These are accomplished with techniques like LIME, which perturb the inputs and use the perturbations to infer how much the model values that input towards the final prediction.

Image from Marco Tulio Ribeiro and Pixabay
3. ML Data Services
There's a wide world of "managed Apache" out there, for example Spark as a Service products are available at all major cloud providers. One place that's looking pretty interesting right now is data labeling, with services like:
The idea behind these services is to use human labelers frequently until a model can begin to infer the labels. As the model gets better at labeling the data, only the observations where the model has low confidence get referred to human labelers.
4. ML as an API
This might be the category with the greatest overlap to other categories, but it's the easiest to grasp. Any API that serves predictions or training endpoints fits in this category. Some notables include:
5. Embedded AI
I'm definitely stretching the definition of an "embedded system" when I use this category, but the basic idea is just devices that ship with built-in ML features, or that plug in to your devices to imbue them with ML magic. Such products include:
Bonus: JaaS

Jupyter as a Service products like Google Colab and Datalore have been around for a long time now, so if you haven't checked them out yet, then now's the time. They're very mature web applications that act like a REPL on steriods. They don't replace an IDE, but have some great features and can be a great option for when you don't actually need a full-fledged IDE. Tools like JupyterHub that host and provide compute instances to Jupyter web clients can create a unified experience with reproducible experiments available alongside their documentation.
Slides
If you'd like to see the whole deck, complete with notes, here you go!
I'll be giving this talk for the first time in a couple weeks so I reserve the right to have errors in the slides. If you have any feedback I'd love it if you share that with me.
Thanks for reading!





Top comments (0)