
KNIME
KNIME Analytics is a Java-based data science tool. It is simpler to construct data mining applications with this software since it supports visual programming in the form of a workflow with numerous nodes, which eliminates the need for highly developed coding abilities, but also allows if you need it. It has a huge and varied plugin center and is commonly used in academic settings. It is an extensible data science platform that supports user-created scripts and codes in addition to visual programming. KNIME is a cross-platform software package that may be set up on several operating systems. Early versions of KNIME works with JAVA 8 but Updated KNIME requires JAVA 11 and higher versions. So, you can install one of the openjdk-11 or openjdk-latest packages before install the KNIME platform. After that You can start surfing with start downloading KNIME by this Link:)
- KNIME Workbench
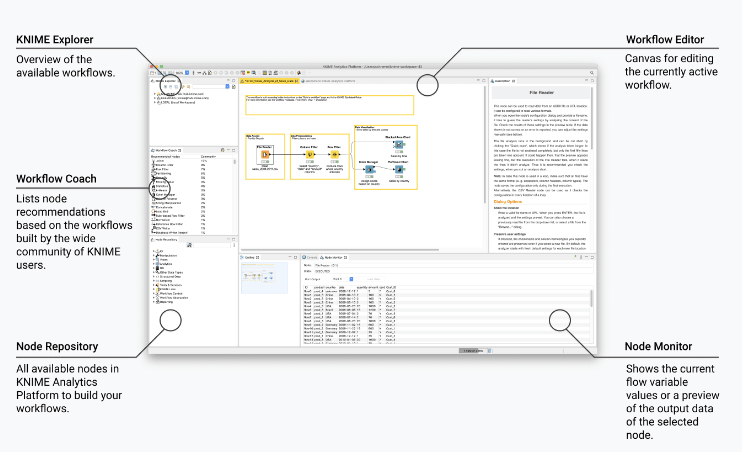
The main tab in the KNIME interface is the Workbench. This Workbench is the place where you will be building your workflows. It is also where you'll find all the resources you need to help you build your workflows.

Other Tabs are,
KNIME Explorer
Explorer is what you use to manage your workflows, workflow groups, and server connections and also you can access example workflows that have been built to demonstrate different functionalities in KNIME.Workflow Coach
This tab will recommend you the node that you can use as the next step after where you are now. These node recommendations are based on KNIME community usage statistics. You can add nodes from the workflow coach to the editor by dragging and dropping them, or by double clicking.Node repository
Currently installed nodes are available from the node repository. You build your workflow by dragging or double clicking nodes from the node repository to the workflow editor as in the workflow coach. There are two types of searches in the repository as crisp search and fuzzy search. The crisp search is the default mode and returns all nodes that either have the search term in the name or that are in a subcategory whose name includes the search term. The fuzzy search returns all nodes that are related to the search term.Description
This gives you information about the currently active workflow, or about an individual node selected either in the node repository or the workflow editor and tells you the purpose of the workflow, what it does, what you might need to run it plus links to blog articles, for example, or other web pages related to the workflow.Console
The console is where any warnings and error messages are shown that relate to your workflow, indicating what is going on under the hood.
Nodes, Data & Workflows
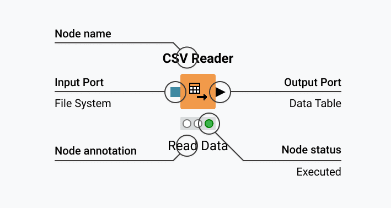
The following image illustrates a node and explains the different parts of a node.
Data access
The start of any project is to access the required data. So, refer below different nodes which we can access data in KNIME. You can access and blend data from different local end remote file systems: CSV files and other formatted text files, Excel workbooks, proprietary file formats of other tools, and more.
Reader Nodes
The common file types for which there are dedicated nodes are CSV, Tabular, and Excel files. For a more exhaustive list and description of all KNIME nodes for data access, download the free e-book "Will they blend?", a collection of blog posts centered around data access & blending.
Related Nodes:
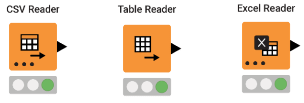
1.CSV Reader
2.Table Reader
3.Excel Reader
Accessing Databases
In KNIME, you can connect to any JDBC compliant database and manipulate data directly on the database. At any point, you can read the data into a local KNIME data table, and vice versa.
Related Nodes:
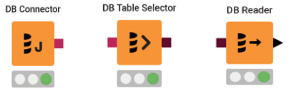
1.DB Connector
2.DB Table Selector
3.DB Reader
Data Cleaning
After accessed the data from one or more sources, you need to clean and transform it. One purpose of these steps is to reduce the irrelevant and retain the essential information. The possible operations include row and column filtering and transformations on numbers, strings, and rules.
Another purpose of cleaning data is to reduce bias and enhance clarity in the next steps, such as model training, statistics calculation, and creating dashboards. Missing value handling and outlier detection are helpful operations there.
Row & Column Filtering
A good start to transforming data is to exclude unnecessary information. Rows can be removed, for example, if they are duplicates, have missing values, or if they just don't belong to the subset of interest.
Related Nodes:

1.Row Filter
2.Column Filter
That's it for the Basic introduction and all data accessing, cleaning parts in KNIME for beginners and keep in touch for upcoming Data Standardization part with numbers, Strings and Rules.
Thank you!

Top comments (0)