
I know, I know… this is not only applicable for data pipelines, but I wanted to elaborate this with a set specific points, some of them might be shared among different development areas, but other will be directly related to data engineering.
The final delivery of a data engineering project resides not only in processing and storing some data, but also on the quality it has. At the end, data is nothing if it’s not meaningful, why should we pay for storage of something that does not generate a relevant insight?
The size of data in these kind of projects represents an associated cost (more specifically if we’re working on cloud), mainly: storage and computing. So, every execution of a pipeline will cost. That’s one of the reasons we should use the resources properly, avoid unexpected charges by executing low quality code or not optimized processes.
Some weeks ago I was in a conversation from where there was a great sentence: “quality is not negotiable” - And it’s totally true!
And now you might think: that's obvious, no? That should be! However, there are some practice that impact it in an indirect way: planning and estimation steps.
Currently, with agile methodologies, we need to give the importance to phases like design/plan and testing that some times are underestimated and are actually key parts for future processes: support and maintenance.
Estimations and then, negotiation are fundamental stages for every project. You’ll need to have the soft skills to justify the estimated development time and this must cover tasks to ensure our solution has the enough quality before deploy it to production.
There are two possible points in the time where you can ensure (or fix) the quality in your data: during development: the happy time…. Or during a prod fix, where, if before there was not enough time, at this point it’s even worse.
While data engineering is usually referred to develop data pipelines, that’s just one part of the job and the solution is much more than just the ETL source code and we can integrate elements like orchestration services, monitoring tools and other services or componentes to handle quality in our solution, so that the final output data keeps the desired standards and expectations.
Here is a list of recommendations that can help you while designing a data pipeline solution keeping the quality as priority and with the intention to reduce the post-deployment time on tasks like hot fixes, maintenance, adjustments, etc.
Explicit instead of implicit
Suppose we need to extract data from a table composed of 3 columns, but this table is not owned by our team. Then we need to load this data into a target table, with the same number and order of columns. If the initial development has read statements like “select *” it would work on the initial configuration, however your solution will depend on the source and target do not change over the time, due to it would broke the solution. In this example, if the source is not owned by your team, the chances of a change happen will increase.

Identify dependencies and ownerships
We use to work with different teams and stakeholders. All projects will have dependencies not only for downstream, but also upstream. Ideally, we shouldn't start coding to consume source or destination entity/service, without known the relevant information for our process.
So, identify all the dependencies that the pipeline will have, internal and external. This will help you to know point-of-contact or communication/information channels to get accurate information of those entities.
Example, if we’re going to consume an external API, we’ll need to consider as an external input dependency, from where we can get information like: authentication requirements, rates, limits, etc.
So, you will know what are the expectations from the source to be consumed and how much data you can extract, the format and all the information around it.
Avoid assumptions
Related to above example, we can not think just on an ideal scenario or happy path, consequently we need to know all the specifications from input to output in our dependencies to define and plan a solution.
Illustrating this in a use case:
We need to create an ETL to consume an API everyday based on a timestamp field (example: get all data for the previous datetime related to its execution). This ETL will be scheduled, but also, we want a backfill for the last year of data. Once this ETL was scheduled for some days we didn’t see any error, but once we ran it for the backfill, the job suddenly failed. Reason? The API has an api-call limit, and since we ran it for a considerable number of days, it reached the maximum limit and started to return error messages.
Above scenario is something we can predict, right?
If we have listed all conditions from our source, we can design a flow depending on what we want to achieve. There are multiple possible solutions for this use case, from an automated retry once the limit is reached based on some conditions, or performing the backfill on batches, etc. But to design it, relevant information must be documented and taken into consideration while design phase.
Make sure that everything its coded is based on a real fact, instead of assumptions. This might sound an implicit point, however it’s quite often to see it.
Identify edge cases and define action items
Considering the amount of data that the pipeline will process the possibilities that we faced not-expected data will increase. Errors in the data format, changes on the source names, etc.
However, this is not just related to the data and catch malformed information, let’s list some of the possibles scenarios we’ll need to think:
- source code: nulls, data format, schemas, etc.
- sources: timeouts, heavy data loads, network issues, etc.
- transformations/logic: Empty inputs, large inputs, etc.
- execution: empty outputs, etc
Make the possible errors part of the solution
From scenarios like a timeout-error while reading the source or an unauthorized-access error due to temporal sessions lock, and some of the above points as well will mean a runtime exception, and we don’t want that, right?
We need to keep in mind all of those edge cases to identify all possible alternatives that our pipeline should handle. Hence, anticipate to the errors and design a flow according them will help us to ensure quality in the output data. Enabling an auto-retry, working with alerts, etc will enhance the solution to make it smart enough to take actions depending on the type of error.
Start from the basics, it’s really helpful to draw to visualize and understand the problem better, before coding. Create a flow diagram will also help, do not underestimate all these resources, at the end, the code is just the final process of the development it’s kind of translating into the language the solution you already designed it.
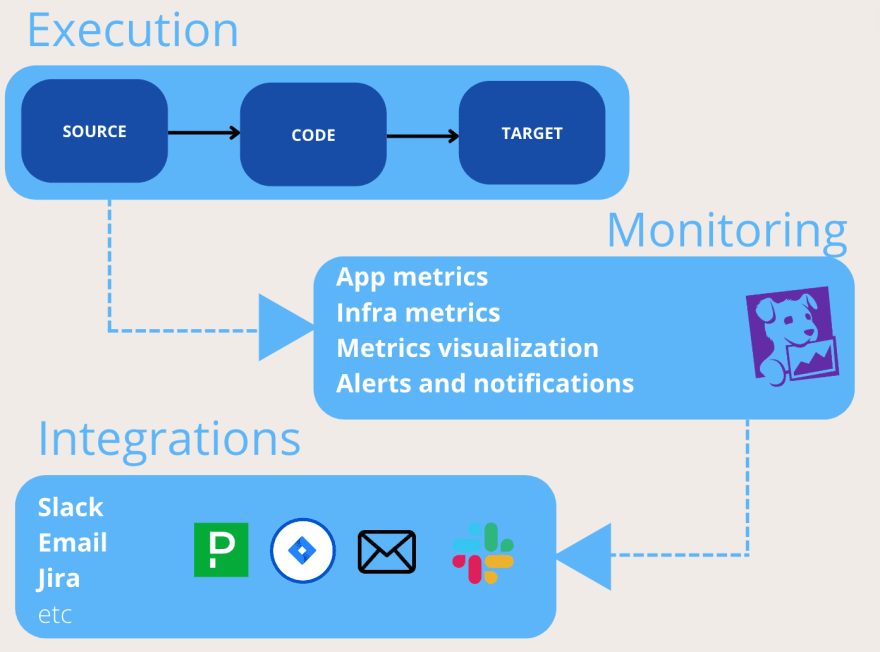
Monitor as much as you can
This is one of my favorite parts of the data pipelines development, where you can add integrations to get a real and accurate status of your project.
Usually, data engineering projects are composed of a set of data pipelines. So, it’s not just complicated, but almost impossible to manually check and identify the status of every single item in our solution. So, it’s required to identify information that help us to know relevant insights from our project.
Example, suppose we have a simple ETL, that reads from table A and writes into table B. For some reason, our team was not informed that table A is not longer updated and instead, now we should point to table C as our source. If we don’t monitor application metrics, like output rows or similar, we won’t never know that our ETL is not working as expected, I mean, it will continue read something that is not being updated, therefore it will generate empty output. This is definitely not good.
While working with orchestrations services like GCP-composer or GCP-GKE, we can schedule and eventually know the final status of our pipeline. However the previous example wouldn’t be identified, producing a false positive error.
By introducing monitors on meaningful metrics (like output rows, etc), we can integrate alerts that can be triggered if we produce empty outputs. Even better, we can integrate a monitor service (ie: datadog) for this data visualization, adding thresholds, warnings, alerts, etc. This is really powerful, being alerted in slack for a warning threshold limit or create a ticket on Jira in case an error, all posibles scenarios matched with the corresponding action.
Be ready for a change
Requirements might change during development, but also even after our solution is running on prod. So, developing a flexible and scalable solution will reduce a lot of time on those kind of changes. Some helpful actions for this would be:
- Avoid hardcoding - yeah, this is for everything!
- Parametrized inputs and configurations
- Try to abstract the logic to work in different possible ways (scheduled, adhoc, etc)
Avoid manual processes
Automation is a key, depending on the team structure you might have or not tasks like CICD or similar. If it’s part of your role activities, try as much as you can to reduce manual tasks, replace repetitive and ad-hoc tasks by automated processes.
If for some reason, you need to perform some SQL statements over an entity (table, schema, etc) in a regular basis, try to automate these processes even if they are not going to be scheduled. A parametrized script that handles the logic will reduce the chances of a human error on those kind of actions.
Testing
Yes, it’s part of development scope. The time of a fix will directly depend on the time that took to identify the bug first (then other points like complexity, impact, etc). Well, we can reduce the time by adding different layers of testing: unit testing, integration testing, etc.
And yes, this is one of the shared points among the different development areas. And its relevant since these layers will help us to identify the errors faster. All the logic, syntax and static issues must be handled by unit test, dependencies errors by integrations tests, etc. All of these quality filters before our code reach production.
Documentation
And again, yes. This is part and a very significant one of the development process. The code is not the unique deliverable, think the deliverable as a solution. If you buy a TV, laptop, cellphone, it will have an instructive.
Similarly, our solution must have a proper documentation from the design, development, change log, points of contacts, etc. All relevant information so that new team members can even have a good KT by just reading it. How this is applicable for data quality? Well, eventually we will have more people working together, so there should be a single source of truth: documentation. And even if we work alone in the project, will you remember how and why did your developed that ETL 2 years back? Sometimes we don’t even remember why we did yesterday, so better to have it documented somewhere, right?
And that’s all!
While there are a lot of different circumstances and cases in each and every project, these are some of the common tasks that I think can be applied to try to keep the quality in your data
Hope this helps!

Top comments (0)