
Introduction
When I started to work in data engineering projects, my first assignation was developing ETL’s with Scala and Apache-Spark. At that point, my background was as a software engineer in roles like web developer with Javascript and a little bit of native android development using Java.
Talking about the learning curve for Apache-Spark, the reality is that it was not complex due to the background: Java as strong-typed language helped with the first steps on Scala, Javascript for functional programming and SQL background for Spark transformations.
I mentioned above context due to during these years, I had the chance to work as a mentor for people that wants/needs to learn Apache-Spark.
From this experience I saw there are 2 common “profiles” depending on the background: people that has software engineering as a background and people working as SQL-developers (for ETL).
For the people with software development experience, the learning curve is usually shorter compared with only-SQL people. This because the profile is implicitly familiar with programming languages like Python, Scala, Java (which are the ones to work with Spark), terms like immutability and paradigms like functional programming.
SQL developers (not all) usually do not have above context or practical experience, therefore the learning curve is not only because of Apache Spark at all, it’s from programming languages, terms, paradigms, etc.
One key on the learning process is a constant progress and avoid frustration, the last section of this article lists some recommendations to help having a smooth learning process.
Let’s try to illustrate some core concepts of how Apache-Spark works, not matter the programming language and focused on SQL developers that want to start with this technology.
RDDs and dataframes
These are the basic data structures that Spark uses. While the RDD is the basic (and first) data structure, the data frame is an optimized one.
Let’s talk about data frames.
It is an object with a tabular structure, defined by a schema that can be provided by the developer or inferred by Spark. An easy comparison for better understanding is a SQL-table, that is a collection of rows with a defined schema.
So, how the data frame is “populated” with data? Well, there are multiple ways to do it, but the a real example would be if you want to read a SQL table or some files on a cloud storage using Spark. Let’s take a look into the below illustration:
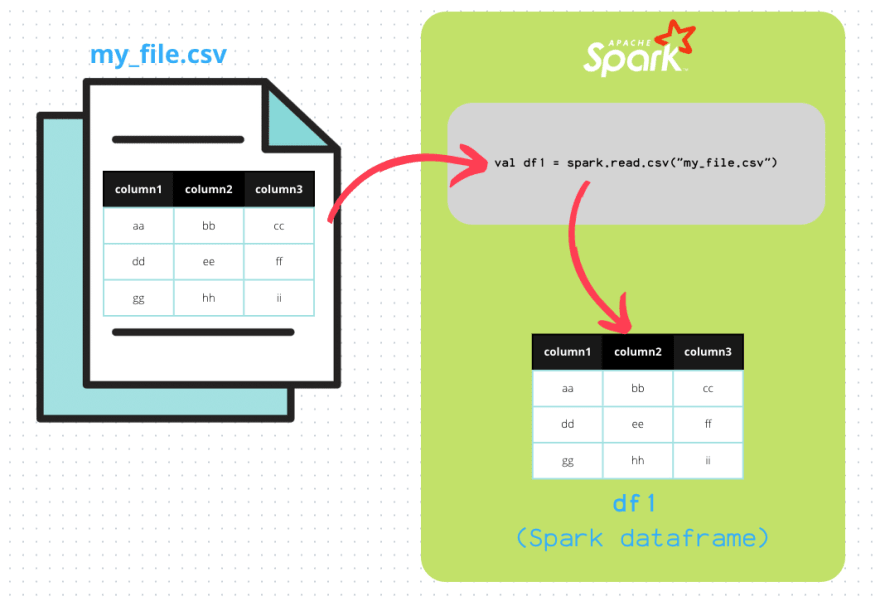
Above illustration is a representation of how this object can be created. The data is going to be read and living into the dataframe objects on the Spark session which is in memory of your cluster.
The data that’s in a data frame after read, it’s just a copy of the original source, meaning that if we perform some operations in the spark-dataframe it won’t affect the real source data. Example, if we make a string-column as uppercase, they will apply only for the data frame values, but not for the SQL table that was used on the read statement.
Immutability
On the previous example we mentioned a scenario to convert a string-column values into uppercase characters, let’s use same scenario to illustrate a programming concept used on objects like Dataframes and RDD’s.
There are multiple ways to do it, but for this example, let’s consider below example:

As you can see, there is a transformation (select statement) which is applied to the initial dataframe (df1). This function (select statement) will take 3 columns and for one of them (column 1) will generate an uppercase value for that column for each row, additional to that, the corresponding output column has an alias and for the other 2 column values there is not going to be a change applied neither on the value nor on the column name. So, the result (return value) will be a new dataframe: df2.
This example represents how dataframe transformations work.
This kind of functions where we manipulate the data, are not going to be executed at specific time, instead, Spark will perform some optimizations by set of transformations that can be executed together.
This groups of transformations are known as Stages (also keno as set of spark-tasks).
For now, what we need to keep in mind is, we can not manipulate directly the data of a dataframe, it can not be updated like a database table. But, we can create new data frames from a different one.
There is no restriction to create as many data frames as we want, at the end, the restriction won’t be the number, but the memory that we consume.
Transformations and actions
The previous section we talked about transformations. Now, let’s talk about actions and what are the differences between them.
In spark there are 2 categories for the data frames functions: transformations and actions.
While transformations are related business logic (ie. select, filter, groupBy, etc), actions are those functions which will trigger an execution for it and the previous stages (ie: show, collect, etc)
There is a concept in spark known as “lazy evaluation”, that basically refers that, spark won’t execute at that time the functions (transformations) only until there is a trigger (action). With that, Spark has a pre-execution and execution steps where it can optimize the logic internally (see more of Optimizer: https://data-flair.training/blogs/spark-sql-optimization/)
Shuffling
One thing to remember is that Spark is intended to be executed in a cluster (it also has the option to run in your local for development purposes), so the data is going to be distributed among the nodes to take advantage of distributed processing, making the process faster.
While optimization would be an advanced topic, we need to know at least, the principle of how the data is moved within the cluster: shuffling.
This means, when a dataframe is created, data is going to be distributed on the workers (cluster nodes), for operations like filter or map, every worker will have the enough data to process the data to the next stage (row level).
However, for operations like groupBy, the whole data should be compared to group according the stablished conditions. These data movement is known as shuffling, since we have data transferred over the network in our cluster. For a better understanding, let’s see below image
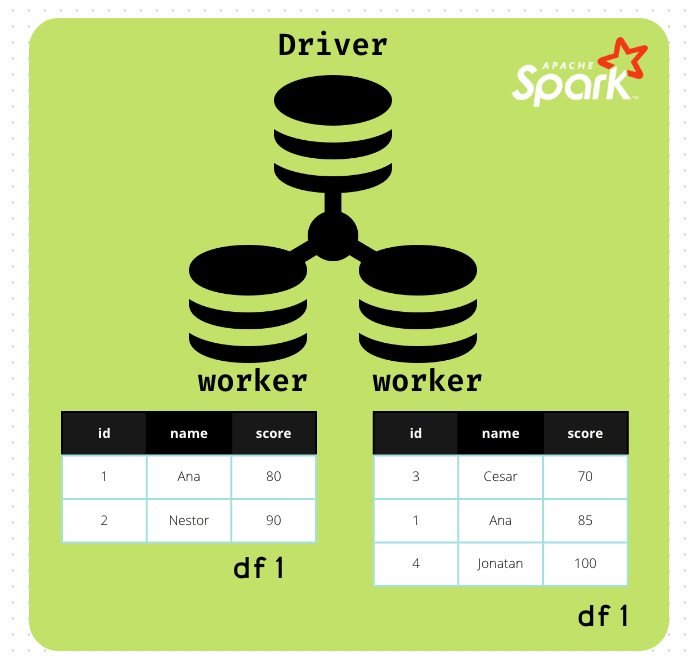
From above illustration we can see that both workers have a partition of the df1, it means portion of data is living on those workers. Therefore, if we want to apply a groupBy, workers should transfer data among the cluster nodes to group the rows.
Another common scenario when shuffle is applied is on the join statement. Records from both data frames needs to be compared in order to join the records.
One advanced topic and common interview question is regarding a best practice to join a large data frame with a tiny one.
This question has the main purpose to know how to manage shuffling in order to optimize performance. There is a feature in Spark that allows you to “send” the tiny dataframe to each of the nodes in the cluster: broadcasting. This will replace the previous action of comparing all the records among the cluster reducing the network traffic load and increasing performance.
Obviously, this has the condition of the tiny dataframe fits into the worker memory (remember Spark works in memory). While this can be done manually (explicit by the programmer), the version 3 of Spark has already integrated an optimization feature (enabled/activated by default) that internally performs the broadcast-join even when it’s not explicit declared in the code.
Data Persistance
All data that is load into a spark session, either dataframe or RDD, is loaded in memory and has the end of the lifecycle once the application is done. Meaning that if it’s not persisted explicitly, it won’t be available on future applications.
Recommendations
If you’re beginner on Apache-spark this list is a set of recommendations that might help you on your first steps with this technology:
- Learning by doing: Courses, tutorials and documentation are great resources for the learning process. However, you can not be a professional soccer player by just reading the regalement or watching matches everyday, right? Same thing for programming. Practice is the key! If something is not clear enough, don’t ignore it, get more examples and practice until you get it.
- If possible, start with strong-typed language (preferable: Scala): This might be special helpful if you don’t have much experience with programming (rather than SQL), because a strong-typed language will help you with debugging for initial errors while practicing with data transformations, plugging on IDE’s for code-snippets, code auto-complement, etc. At the end, once learned Spark core concepts, same can be applied on the rest of the languages (adapting the API restrictions for specific language).
- At the beginning, use notebooks: It’s important to remove frustration from the initial learning curve, so as much as we can we need to avoid extra steps and keep focus on the goal, in this case: learn Apache Spark. By using notebooks it will allow you to go directly to the practice step, without any additional configuration and/or setup.
- Unit testing: Take advantage of Spark and the possible programming languages and add unit testing for your code, try to keep it clean, follow principles like single-responsibility to ensure the quality of you pipeline.
- Databricks community edition: Related to the above point, Databricks community edition will provide you a pre-configured spark environment, including notebooks, storage (to create tables by loading files), etc. With few clicks you can create a Spark cluster, create tables and notebooks for practice without worry about installations, configurations, etc.
- Avoid re-invent the wheel and keep it simple: Spark, at the end, is for data processing, similar than you might have done with SQL (but cleaner and easier, ja!). Try to map the knowledge into the new technology. Example: Apache functions like filters and where are the same as SQL-where.
- Progressive learning: Avoid go deeper than needed, at least in the beginning. Try to understand the general basics first, before dealing with advanced topics of some specific topic. Example: at some time you’ll need to configure a spark-session with integrations, advanced configs for optimization, etc. However, at the beginning it’s not relevant. It will be more important if you domain data manipulation before go to the configuration stage.

Top comments (0)