
"Hey Siri! Can you wake me up tomorrow morning at 5 am?"
"Sure, setting an alarm at 5 a.m. tomorrow morning."
We have come a long way from the times where we had to beat down our alarm clock to stay silent. Now with just a single word we are able to do tasks, from keeping track of our daily schedule to getting information on various stuff, to even booking flight tickets and movie tickets. But how has all this been possible? Well, the answer to it lies in the field known as "Natural Language Processing".
We have finally been able to harvest the power of data and information we, as humans use, in the form of natural language, and have been able to teach machines on how to use that data, in the form of tasks such as sentiment analysis, paragraph summarization and chatbots, among many others.

Word Embeddings
But hey, how is it possible? I mean, as far as we know machine learning, or the ability to teach machines to do tasks themselves, requires the data to be in numerical format. How are we supposed to convert words and sentences into numbers 🤔?
Well, that's where the concept of word embedding came in. An approach of bag of words(called BoW) was used, where words were converted into vectors the size of a vocabulary.
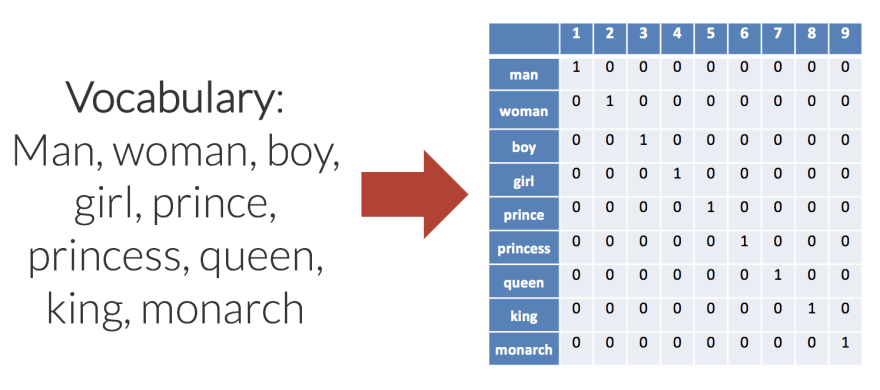
That solves our problems, phew!Wait, hang on! This method is fine and all, but it takes each word as independent of one another. It won't realize that queen and woman are very similar words. How are we supposed to deal with this then???
Now this is where the magic of word2vec comes in!
Word2Vec
Tomáš Mikolov, a Czech computer scientist working in the field of machine learning, published a paper named "Distributed Representations of Words and Phrases and their Compositionality", in 2013.
This paper revolutionized the world of NLP as it introduced an approach where vectors of similar types of words were grouped together in a vector space by finding the similarities mathematically. This not only allowed us to work on words and natural language in a mathematical fashion, but also reduced the amount of computational power required to process natural language vectors.
This technique was subsequently used by RNN, or recurrent neural network models, to train highly advanced state of the art NLP models, which included stuff like predicting the next alphabet given a sequence of alphabets (yes, it's what you see when there's a word recommendation when you are typing something on your phone). RNNs used memory from the previous alphabets/words, to predict the next alphabet/word in the sequence.
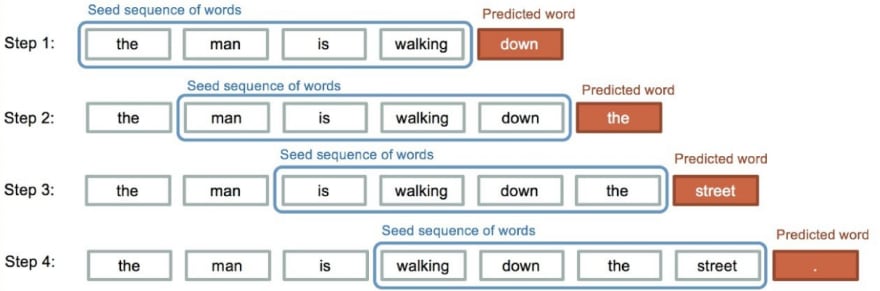
This led to even advanced models such as LSTMs and GRUs. Such models led to creation of technologies we just dreamed about, in the form of chatbots like Google Asssitant, to translation tools like Google Translate, to audio search and many more. Sequence to sequence generation models developed from here, where, given an input sequence, the model would generate an output sequence based of the previous word in the output, as well as the whole input sentence in general.
Transformer
Still there was one problem that persisted. The RNN models, especially in cases of tasks such as transliteration and translation, had to look at the entire input sentence to produce the transliterated or translated output, and this slowed down the whole process and consumed lots of computational power. And here came the "transformer" model by Google to the rescue.
Transformer models were released in 2017 by Google and they used something called as "attention mechanism".
Basically, given a sequence of words as input, the model would only look at specific words of the input required to generate the next word in the output sequence instead of looking at the whole input sequence. This enabled parallelism and allowed us to train our model/machine faster on way more data than earlier was possible, and accurately at that.
BERT
The technologies were getting advanced. With such a boost of natural language processing technology, all things seemed to be going great. But wait a second, why does it feel like we are missing something? Something really, really, REALLY important 🤔. Oh, wait, what about context? What if two words were used in two different sentences with both having different meanings? Say "I am going to the bank to deposit my money." and "I am going to the river bank for a stroll." both have the same word "bank", but completely different in meanings. Here came the breathtaking NLP framework by Google called "BERT".

BERT stands for Bidirectional Encoder Representations from Transformers.
What it did was, it gave attention on a given word in a sentence, while also identifying all of the context of other words in relation to that word. This opened up a new dimension of NLP,which had been locked till now, and became the source of an even more powerful model in 2020 which solved the problem of attention(or to say time being taken by it) and space complexity of transformers, called Reformers.
Reformer
The Reformer model combined two techniques to solve the problems of attention and memory allocation: locality-sensitive-hashing (LSH) to reduce the complexity of attending over long sequences, and reversible residual layers to more efficiently use the memory available.
In simple terms, it allotted a hash value to each input, and then re-ordered the hash values to chunk them together, thus applying the attention model to such chunks, which greatly reduced the computational power and memory needed as well as increased parallelism in general.The reversible residual layers helped to recompute the input from the input layer in the network, on demand, instead of storing the activation functions(basically the underlying mathematical function which builds up the neural network) throughout the network, thus leading to high memory management. This architecture by Google has opened lots of opportunities of even advanced tasks using NLP which would have been extremely difficult 5-10 years back. With this, one was able to now work on heavy NLP algorithms without needing lots of GPU/TPUs, etc.

The applications of NLP are limitless, with variations ranging from chatbots, to sentiment analysis and translation and transliteration, to even generation of captions and summarizing texts. We see chatbots being used nearly everywhere nowadays, and smart chatbots for business purposes are on high demand in today's world. To state a recent event, Facebook launched a "hateful memes challenge" where it invites people from across the globe to build a model for identifying whether a meme in general is conveying any negative feelings or not.
The rate of growth of this field is quite fast and insane. At this pace, we maybe able to develop and innovate tasks which we currently think as impossible ourselves. We are far from reaching the zenith of Natural Language Processing, and we are gonna get better and continue evolving in this field as this is all just the beginning of what we can achieve.
This was my first try on writing a technical article. All the related python codes and papers of the aforesaid models and technologies have been embedded in to texts, and you can refer to them all as they all are completely open source. Hope you guys liked it.
def convey_thanks():
print("Thank you for reading this 🙇♂️")
convey_thanks()





Top comments (0)