
Type safety with GraphQL has been a hassle, so tRPC was long overdue
tRPC has recently risen to fame in the TypeScript community, and I dare to say a library like this was long overdue. In the past, achieving type safety was a tedious task. The common options were either manually creating and managing types or using GraphQL with a code generator.
Interestingly, many engineers neglected one of the key features of GraphQL – language agnosticism. Furthermore, some of us complicated matters by generating a schema from our TypeScript code (or even writing it ourselves) and then converting everything back to TypeScript for our web application.
To make it easier to ensure type safety and never have to deal with the complex configuration of TypeScript and GraphQL again, I decided to give tRPC a try. Let’s see how they work under the hood and compare one against another.
tRPC requests based on procedures, while GraphQL requests selective data
tRPC is a tool specifically designed for TypeScript and monorepos. In simple terms, it integrates the types from the backend with the web client. You can optionally specify the return types, but tRPC can infer them automatically. This means you don't need to generate or reload anything. If there's a change in the input, it will immediately show an error in your frontend code. The frontend client is based on TanStack Query with some adjustments, so there's no need to learn new syntax to integrate the API.
On the other hand, GraphQL allows us to request only the necessary fields, which is a groundbreaking feature, particularly for mobile apps. However, I'm willing to sacrifice that for the speed and efficiency that tRPC offers. Let's demonstrate this through a simple step-by-step comparison of both approaches.
How tRPC and GraphQL work – Demo project
In both cases I’ll be implementing a simple search.
I’ll be using Prisma to model my PostgreSQL database. In schema.prisma file I’ll define a simple model:
enum FruitType {
CITRUS
BERRY
MELON
}
model Fruit {
id String @id @default(cuid())
createdAt DateTime @default(now())
name String
type FruitType
}
GraphQL setup
Creating the endpoint
For the GraphQL part I’ll be using NestJS as it allows a code-first approach for generating GQL schemas.
In order to generate the schema I’ll need to create a link between TypeScript and GraphQL. To do so I need to define a class for my return type decorated with @ObjectType.
@ObjectType()
export class FruitType {
@Field()
id: string;
@Field()
name: string;
@Field()
createdAt: Date;
@Field(() => FruitTypeEnum)
type: FruitTypeEnum;
}
GraphQL doesn’t understand TypeScript enums out of the box, so I also needed to register my enum.
registerEnumType(FruitType, {
name: 'FruitTypeEnum',
});
Next up is creating a resolver and a query inside of it which will return the fruit. Resolvers provide the instructions needed for turning GraphQL operations (a query in this case) into data.
To generate a GraphQL schema query I used @Query() decorator to which I provided the previously created return type and a query name.
Passing arguments to a query can be achieved through @Args decorator. Like before, I also need to specify the GraphQL type, not only the TypeScript one.
@Resolver(() => FruitType)
export class FruitResolver {
constructor(private prisma: PrismaService) {}
@Query(() => [FruitType], { name: 'fruit' })
async findAll(
@Args('search', { type: () => String, nullable: true }) search?: string,
) {
const fruits = await this.prisma.fruit.findMany({
where: { name: { contains: search, mode: 'insensitive' } },
});
return fruits;
}
}
After those steps I can see that my schema file reflects my API in GraphQL. The type I created is present as well as the enum and the query.
# ------------------------------------------------------
# THIS FILE WAS AUTOMATICALLY GENERATED (DO NOT MODIFY)
# ------------------------------------------------------
type FruitType {
id: String!
name: String!
createdAt: DateTime!
type: FruitTypeEnum!
}
"""
A date-time string at UTC, such as 2019-12-03T09:54:33Z, compliant with the date-time format.
"""
scalar DateTime
enum FruitTypeEnum {
CITRUS
BERRY
MELON
}
type Query {
fruit(search: String): [FruitType!]!
}
Frontend part
I start integrating my GraphQL API by setting up codegen.
import type { CodegenConfig } from "@graphql-codegen/cli";
const config: CodegenConfig = {
overwrite: true,
schema: "http://localhost:3000",
documents: "src/**/*.tsx",
generates: {
"src/gql/": {
preset: "client",
plugins: [],
},
},
};
export default config;
Then I need to write a query to define the data I want to fetch.
query findFruit($search: String) {
fruit {
id
name
type
}
}
After running the code generator my types are ready and I can use them to type ApolloClient's useQuery.
const { data: fruits } =
useQuery<FindFruitQuery>(FindFruitDocument, {
variables: { search },
});
As you can see I have to provide the type myself, useQuery doesn’t know the types just from providing the document.
tRPC
Creating the endpoint
Firstly I need to create a procedure - a piece of logic to be executed upon hitting a route.
This time around I won’t need to specify the return type, but I will need to create an input. I chose zod as my validator, but tRPC supports multiple validation libraries as well as custom validation.
import { z } from "zod";
export const findFruitInput = z.object({
search: z.string().optional(),
});
The procedure will have the input and prisma as its parameters, PrismaClient will be passed through tRPC’s context.
export const findFruit = async (
input: z.infer<typeof findFruitInput>,
prisma: PrismaClient
) => {
try {
const fruits = await prisma.fruit.findMany({
where: { name: { contains: input.search, mode: "insensitive" } },
});
return fruits;
} catch (e) {
console.error(e);
return [];
}
};
Now the logic is ready to be attached to a route. To achieve that I will create a router for all of my fruit related operations.
Routers can be created from any point of your application by using createTRPCRouter. They need to be connected to the main appRouter though.
By default you are provided with publicProcedures, but you can also use restricted ones by creating middlewares. Procedures use the builder pattern which makes them very flexible. I’ll be using input and query construction steps, in order to modify data one should use mutation, exactly like in GraphQL.
export const fruitRouter = createTRPCRouter({
find: publicProcedure.input(findFruitInput).query(async ({ input, ctx }) => {
return await findFruit(input, ctx.prisma);
}),
});
Frontend part
tRPC can be easily integrated into Next.js with some basic boilerplate code. Here are some examples of bootstrapers, I personally really like T3 stack.
The boilerplate code transforms a Next.js API route to work as an API handler. tRPC itself is not a backend framework, it attaches to an adapter of your choice. The full list of supported adapters can be found here.
import { createNextApiHandler } from "@trpc/server/adapters/next";
export default createNextApiHandler({
router: appRouter,
createContext: createTRPCContext,
onError:
env.NODE_ENV === "development"
? ({ path, error }) => {
console.error(
`❌ tRPC failed on ${path ?? "<no-path>"}: ${error.message}`,
);
}
: undefined,
});
The client configuration is also included in the boilerplate code.
Now whenever I want to use my query I simply call the proper TanStack Query method on a procedure from my router. Everything is fully typed out of the box, so there is very little room left for errors. I already know what kind of procedures I can call from each of my routers as well as which methods from TanStack Query are available for a given procedure.
const { data: fruit } = api.fruit.find.useQuery({ search });
Key tRPC strength
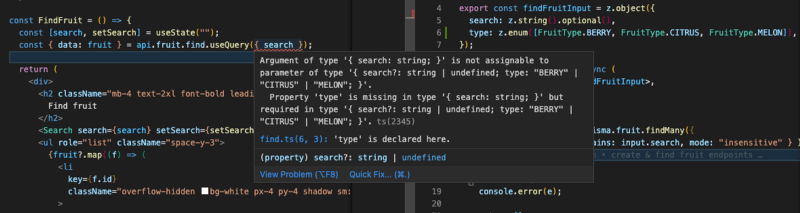
If I were to also search fruits by their type, I would have to include the new argument in the GraphQL query in my web app. The complier won’t automatically notify me of a new mandatory argument. If I forgot to fix the query, I’d get an error from the server. Changing the query also requires me to run codegen again.
Modifications like this one are much simpler with tRPC. After modifying my zod input object the compiler instantly prompts me to fix my input on the client side.
Conclusion
If you’re not planning on utilizing the language agnosticism and there are no circumstances under which the ability to only ask for necessary fields is key for optimizing queries and improving performance of your app, GraphQL may be a choice which will only add a bunch of chores to the development process.
A well designed tRPC API will result in a fully type-safe app which can be modified effortlessly. Every point of your app will be aware of available routes, their types (mutation/query) and inputs.
The only downside to tRPC I was able to observe so far is the lack of a convention which may result in hard to maintain code.
The authors of tRPC themselves are big fans of GraphQL and I couldn’t agree with them more:
If you already have a custom GraphQL-server for your project, you may not want to use tRPC. GraphQL is amazing; it's great to be able to make a flexible API where each consumer can pick just the data they need.
The thing is, GraphQL isn't that easy to get right - ACL is needed to be solved on a per-type basis, complexity analysis, and performance are all non-trivial things.
tRPC is a lot simpler and couples your server & website/app more tightly together (for good and for bad). It allows you to move quickly, make changes without having to update a schema, and avoid thinking about the ever-traversable graph.
At the end of the day what matters to me as a developer is the how effective a tool is and how much effort it needs from me to achieve that effectiveness. tRPC lowers the effort while improving the effect when compared to GraphQL.





Top comments (0)