
Before starting, just watch this very short YouTube video to see what exactly you can make with no cost by following this article until the end.
As you may already know, voice conversations have come to the ChatGPT app. That was officially announced by OpenAI:
- Event Livestream: OpenAI DevDay, Opening Keynote
- Blog: New models and developer products announced at DevDay
- Short video by CNET: Voice Conversations Come to the ChatGPT App
In this article, you can learn a way to build an AI voice assistant using Google Bard. You will create a Telegram bot API using the following stack:
- Node.js — the running backend server which will interact with Telegram to receive and send voice/text messages
- Python — scripts for TTS (text-to-speech), audio-transcribing (speech-to-text) and getting Google Bard answers
- Telegram — the client mobile app which will be used
- Google Bard — as an AI ChatBot service
- MongoDB — a database service
- Amazon Polly — AWS service for TTS conversion (free tier)
The prerequisites that you will need are:
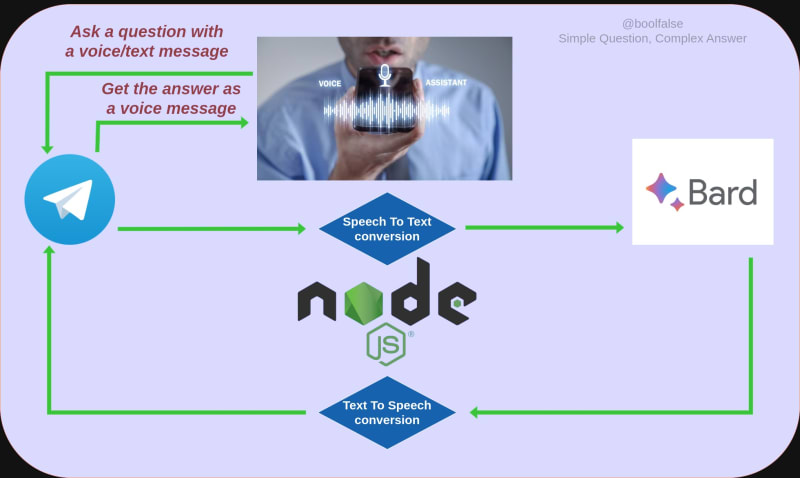
In the above image is the whole project’s lifecycle.
The required steps you need to follow are:
- Create a new AWS IAM user and give it access to Amazon Polly. Get the AWS Access Key and AWS Secret Key.
AWS provides free tier for Polly.
For Amazon Polly’s Standard voices, the free tier includes 5 million characters per month for speech or Speech Marks requests, for the first 12 months, starting from your first request for speech.
- Go to the AWS Management Console and sign in.
- Click Identity & Access Management (IAM).
- In the left pane, click Users.
- Click the name of the user you want to create access keys for.
- Click the Security tab.
- Under Access keys (access key ID and secret access key), click Create Access Key.
- AWS generates an access key ID and secret access key. Download the CSV file that contains your access key credentials, or copy and paste the access key ID and secret access key into a secure location.
- Click Close.
- Create a Telegram bot with BotFather. Get the Telegram Bot Token.
- Open Telegram and search for “BotFather”.
- Tap Start to start the conversation.
- Type
/newbotand send it to BotFather.- Enter a name for your bot.
- Enter a username for your bot. The username must end with the word “bot”.
- BotFather will reply with your bot’s token.
- Copy and paste the token in a safe place.
- Create a MongoDB Atlas cluster and set up IP whitelist. Get the MongoDB connection string.
Create a MongoDB Atlas cluster:
- Go to the MongoDB Atlas, and sign up for a free account.
- Once you are logged in, click New Cluster.
- Select the cluster tier and region that you want.
- Click Create Cluster.
Set up IP whitelist:
- Go to the Security tab of your cluster.
- Under IP Access List, click Add IP Address.
- Enter your IP address and click Add IP Address.
- You can also add a CIDR range to allow access from multiple IP addresses.
Get the MongoDB connection string:
- Go to the Connect tab of your cluster.
- Under Connection Strings, select the connection string format that you want.
- Copy and paste the connection string into a safe place. You will need it to connect to your MongoDB Atlas cluster from your Node.js app.
- Set the appropriate credentials in the connection string.
- Login to your Google Bard account via desktop web app to get the values of
__Secure-1PSIDand__Secure-1PSIDTScookies. Like so:

Now, as you have all the necessary credentials, you can start building a Node.js app:
mkdir sqca && cd sqca/
Initialize a basic Node.js app:
npm init -y
For a better VCS experience, modify the .gitignore file content using this.
Install some NPM packages that you will use in your app:
npm i aws-sdk axios dotenv fluent-ffmpeg mongoose telegraf
# optional
npm i -D nodemon
In the package.json setup “start” command like this:
"scripts": {
"start": "node ./src/index.js",
"dev": "nodemon ./src/index.js"
}
As you can see, we have to have some index.js file inside the src folder. Let’s create them:
mkdir src && touch src/index.js
As you need to use some functionalities, you can have separate src/utils.js file to implement them:
import AWS from 'aws-sdk';
import fs from 'fs';
import fluent from 'fluent-ffmpeg';
import axios from 'axios';
import { exec } from 'child_process';
export default {
// download .oga file
download: async (url, outputPath) => {
const writer = fs.createWriteStream(outputPath);
const response = await axios({url, method: 'GET', responseType: 'stream'});
response.data.pipe(writer);
},
// check if user folder exists, if not create it
folderStructureSync: (folder) => {
if (!fs.existsSync(folder)) {
fs.mkdirSync(folder);
}
},
// convert .oga to .wav
convert: async (inputPath, outputPath) => {
return await fluent(inputPath).toFormat('wav').save(outputPath);
},
// extract text from .wav
speechToText: async (filePath) => {
const result = await new Promise((resolve, reject) => {
const pythonExec = process.env.PYTHON_EXEC_PATH || 'python';
exec(`${pythonExec} python/transcribe.py "${filePath}"`, (err, stdout, stderr) => {
if (err) {
console.error(err.message);
reject(err);
} else {
resolve(stdout);
}
});
});
return JSON.parse(result);
},
// get answer from Google Bard
getAnswer: async (text) => {
const gb1psid = process.env.GOOGLE_BARD_SECURE_1PSID;
const gb1psidts = process.env.GOOGLE_BARD_SECURE_1PSIDTS;
const result = await new Promise((resolve, reject) => {
const pythonExec = process.env.PYTHON_EXEC_PATH || 'python';
exec(`${pythonExec} python/answer.py "${gb1psid}" "${gb1psidts}" "${text}"`, (err, stdout, stderr) => {
if (err) {
console.error(err.message);
reject(err);
} else {
resolve(stdout);
}
});
});
return JSON.parse(result);
},
// empty folder
emptyFolder: async (folder) => {
fs.readdir(folder, (err, files) => {
if (err) {
console.error(err.message);
}
for (const file of files) {
fs.unlink(`${folder}/${file}`, err => {
if (err) {
console.error(err.message);
}
});
}
});
},
// text to voice
textToVoice: async (text, folderPath) => {
AWS.config.credentials = new AWS.Credentials(process.env.AWS_ACCESS_KEY, process.env.AWS_SECRET_KEY);
AWS.config.region = "us-west-2";
// text-to-speech service
const Polly = new AWS.Polly({signatureVersion: 'v4', region: 'us-west-2'});
const params = {'Text': text, 'OutputFormat': 'ogg_vorbis', 'VoiceId': 'Joanna'};
const data = await Polly.synthesizeSpeech(params).promise();
if (data.AudioStream instanceof Buffer) {
const fileName = Date.now();
const filePath = `${folderPath}/${fileName}.wav`;
await fs.writeFile(filePath, data.AudioStream, (err) => err && console.error(err));
return {success: true, file_path: filePath, message: 'Text to voice success!'};
} else {
return {success: false, message: 'Text to voice failed!'};
}
},
// filter answer from Google Bard
filterAnswer: async (originalText) => {
let text = originalText;
if (text.includes('Google Bard')) {text = text.replace('Google Bard', 'SQCA bot');}
if (text.includes('Bard of Google')) {text = text.replace('Bard of Google', 'SQCA bot');}
if (text.includes('Bard')) {text = text.replace('Bard', 'SQCA bot');}
if (text.includes('https://bard.google.com')) {text = text.replace('https://bard.google.com', 'boolfalse.com');}
return text;
},
};
For interacting with DB you can have some src/handlers.js:
import User from "../models/userModel.js";
import Message from "../models/messageModel.js";
import settings from "../config/settings.js";
export default {
getUser: async (userTelegramId) => {
return await User.findOne({ telegram_id: userTelegramId });
},
createUser: async (createObj) => {
return await User.create(createObj);
},
updateUser: async (userId, updateObj) => {
await User.updateOne({ _id: userId }, updateObj);
},
createMessage: async (createObj) => {
return await Message.create(createObj);
},
updateMessage: async (messageId, updateObj) => {
await Message.updateOne({ _id: messageId }, updateObj);
},
isLimitExceeded: async (userId) => {
const today = new Date();
const todayStart = new Date(today.getFullYear(), today.getMonth(), today.getDate());
const todayEnd = new Date(today.getFullYear(), today.getMonth(), today.getDate() + 1);
const voiceMessagesLength = await Message.aggregate([{
$match: {
user: userId,
// answer_status: { $ne: 4 },
answer_status: 1,
createdAt: { $gte: todayStart, $lt: todayEnd },
},
}, {
$group: {
_id: null,
total: { $sum: '$question_voice_duration' },
},
}]);
const voiceMessagesLengthSum = voiceMessagesLength.length > 0 ?
voiceMessagesLength[0].total : 0;
const messagesCount = await Message.countDocuments({
user: userId,
answer_status: 1,
createdAt: { $gte: todayStart, $lt: todayEnd },
});
return messagesCount >= settings.max_questions_per_day ||
voiceMessagesLengthSum >= settings.max_voice_messages_length_per_day;
},
};
You can keep some configuration files in a separate config folder.
- config/commands.js
export default {
start: "Start bot (automatically called when you start the bot)",
help: "Help (show the commands list)",
test: "Test (on success, the bot will reply with voice)",
// new: "New session (forget the previous conversation context)",
};
- config/db.js
import mongoose from "mongoose";
const connectDB = async () => {
try {
const conn = await mongoose.connect(process.env.MONGO_URL);
console.info(`MongoDB Connected: ${conn.connection.host}`);
} catch (err) {
console.error(`Error: ${err.message}`);
process.exit(1);
}
};
export default connectDB;
- config/settings.js
export default {
max_questions_per_day: 10, // 10 questions per day
max_voice_messages_length_per_day: 60, // 60 seconds per day
};
Create models in a models folder:
- models/messageModel.js
import mongoose from 'mongoose';
const messageSchema = mongoose.Schema({
_id: {
type: mongoose.Schema.Types.ObjectId,
required: true,
auto: true,
},
user: {
type: mongoose.Schema.Types.ObjectId,
required: true,
ref: 'User',
},
question_type: {
type: String,
required: true,
default: 'text', // 'text', 'voice', 'command'
},
command: { // question_type: command
type: String,
required: false,
},
question_text: { // question_type: text
type: String,
required: false,
},
question_voice_url: { // question_type: voice
type: String,
required: false,
},
question_voice_duration: { // question_type: voice
type: Number,
required: false,
},
answer_type: {
type: String,
required: true,
default: 'text', // 'text' or 'voice'
},
answer_text: { // answer_type: text
type: String,
required: false,
},
answer_voice_url: { // answer_type: voice
type: String,
required: false,
},
answer_status: {
type: Number,
required: true,
default: 0, // 0: pending, 1: answered, 2: rejected, 3: error, 4: limit_exceeded
},
}, {
timestamps: true,
});
const Message = mongoose.model('Message', messageSchema);
export default Message;
- models/userModel.js
import mongoose from 'mongoose';
const userSchema = mongoose.Schema({
_id: {
type: mongoose.Schema.Types.ObjectId,
required: true,
auto: true,
},
telegram_id: {
type: Number,
required: true,
unique: true,
},
name: {
type: String,
required: true,
},
username: {
type: String,
required: true,
unique: true,
},
limit_exceeded: {
type: Boolean,
required: true,
default: false,
},
limited_until: {
type: Date,
required: false,
},
isAdmin: {
type: Boolean,
required: true,
default: false,
},
}, {
timestamps: true,
});
const User = mongoose.model('User', userSchema);
export default User;
You may already have noticed that in src/utils.js there are two methods, where functions calls some external python scripts: transcribe.py for speech-to-text conversion, and answer.py to retrieve the answer from the Google Bard response. Create those script files in a separate python folder:
- python/transcribe.py
import speech_recognition as sr
from os import path
import json
import sys
if len(sys.argv) < 2:
result = {
"success": False,
"message": "Audio file not provided!"
}
print(json.dumps(result))
AUDIO_FILE = path.join(path.dirname(path.realpath(__file__)), sys.argv[1])
# use the audio file as the audio source
r = sr.Recognizer()
with sr.AudioFile(AUDIO_FILE) as source:
audio = r.record(source) # read the entire audio file
# recognize speech using Google Speech Recognition
try:
# to use another API key, use `r.recognize_google(audio, key="GOOGLE_SPEECH_RECOGNITION_API_KEY")`
result = {
"success": True,
"message": r.recognize_google(audio)
}
print(json.dumps(result))
except sr.UnknownValueError:
result = {
"success": False,
"message": "Google Speech Recognition could not understand audio!"
}
print(json.dumps(result))
except sr.RequestError as e:
result = {
"success": False,
"message": "Could not request results from Google Speech Recognition service; {0}".format(e)
}
print(json.dumps(result))
- python/answer.py
import sys
import json
from Bard import Chatbot
def process_parameters(gb1psid, gb1psidts, text):
if gb1psid is None or gb1psidts is None or text is None:
result = {
"success": False,
"message": "Command sample: python answer.py \"<gb1psid>\" \"<gb1psidts>\" \"<text>\""
}
return json.dumps(result)
# Process the parameters as needed
chatbot = Chatbot(gb1psid, gb1psidts)
answer = chatbot.ask(text)
result = {
"success": True,
"message": answer
}
return json.dumps(result)
# Retrieve parameters from command line arguments
gb1psid = sys.argv[1] if len(sys.argv) > 1 else None
gb1psidts = sys.argv[2] if len(sys.argv) > 2 else None
text = sys.argv[3] if len(sys.argv) > 3 else None
# Process the parameters and return the result
try:
result = process_parameters(gb1psid, gb1psidts, text)
print(result)
except Exception as e:
result = {
"success": False,
"message": str(e)
}
print(json.dumps(result))
Finally, let’s work on the main src/index.js file. Here’s a high level view of it:
// IMPORTS
import dotenv from 'dotenv';
dotenv.config();
import { Telegraf } from "telegraf";
import { message } from "telegraf/filters";
import utils from "./utils.js";
import handlers from "./handlers.js";
import path from "path";
import commands from "../config/commands.js";
import connectDB from "./../config/db.js";
import settings from "../config/settings.js";
// INITIALIZATIONS
connectDB();
const bot = new Telegraf(process.env.TELEGRAM_BOT_TOKEN);
// EVENT LISTENERS
bot.command('start', async (ctx) => {
// ...
});
bot.command('new', async (ctx) => {
// ...
});
bot.command('help', async (ctx) => {
// ...
});
bot.command('text', async (ctx) => {
// ...
});
bot.command('voice', async (ctx) => {
// ...
});
// START THE BOT
bot.launch();
// TERMINATION SIGNALS
process.once('SIGINT', () => bot.stop('SIGINT'));
process.once('SIGTERM', () => bot.stop('SIGTERM'));
In the above code let’s inject event listener callbacks step by step:
- Start the bot
bot.command('start', async (ctx) => {
const userTelegramId = ctx.message.from.id;
let answerMessage = '';
// check if user exists in DB, if not create it
let dbUser = await handlers.getUser(userTelegramId);
if (dbUser) {
// build multiline text message
answerMessage += 'I\'m an assistant. Just ask me anything using text or voice messages.'
} else {
dbUser = await handlers.createUser({
telegram_id: userTelegramId,
username: ctx.message.from.username,
name: ctx.message.from.first_name,
});
// build multiline text message
answerMessage = `\u{1F64B} Hello ${dbUser.name}! \n\n`;
answerMessage += 'Below are the commands you can use:\n\n';
Object.keys(commands).forEach((command) => {
answerMessage += `/${command} - ${commands[command]}\n`;
});
answerMessage += '\nYou can send up to 10 questions per day, and in case of voice messages, up to 60 seconds per day.';
answerMessage += '\n\nHappy hacking! \u{1F680}';
}
// send text to user
await ctx.reply(answerMessage);
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'command',
command: 'start',
answer_text: answerMessage,
answer_status: 1,
});
});
- New chat
bot.command('new', async (ctx) => {
const userTelegramId = ctx.message.from.id;
// check if user exists in DB, if not create it
let dbUser = await handlers.getUser(userTelegramId);
if (!dbUser) {
dbUser = await handlers.createUser({
telegram_id: userTelegramId,
username: ctx.message.from.username,
name: ctx.message.from.first_name,
});
}
let answerMessage = "Previous conversation ended. You can start a new one \u{1F609}";
// send text to user
await ctx.reply(answerMessage);
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'command',
command: 'new',
answer_text: answerMessage,
answer_status: 1,
});
});
- Special message for help
bot.command('help', async (ctx) => {
const userTelegramId = ctx.message.from.id;
// check if user exists in DB, if not create it
let dbUser = await handlers.getUser(userTelegramId);
if (!dbUser) {
dbUser = await handlers.createUser({
telegram_id: userTelegramId,
username: ctx.message.from.username,
name: ctx.message.from.first_name,
});
}
// build multiline text message
let answerMessage = `These are bot commands:\n\n`;
Object.keys(commands).forEach((command) => {
answerMessage += `/${command} - ${commands[command]}\n`;
});
answerMessage += '\nJust use them if need!';
// send text to user
await ctx.reply(answerMessage);
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'command',
command: 'help',
answer_text: answerMessage,
answer_status: 1,
});
});
- Text messages
bot.on(message('text'), async (ctx) => {
const userTelegramId = ctx.message.from.id;
const questionMessage = ctx.message.text;
// check if user exists in DB, if not create it
let dbUser = await handlers.getUser(userTelegramId);
if (!dbUser) {
dbUser = await handlers.createUser({
telegram_id: userTelegramId,
username: ctx.message.from.username,
name: ctx.message.from.first_name,
});
}
// check if 'limited_until' exists and not expired
if (dbUser.limited_until && new Date() < dbUser.limited_until) {
const answerMessage = `Sorry, you have exceeded the daily limit.` +
`\nIt is max ${settings.max_questions_per_day} messages per day, ` +
`and max ${settings.max_voice_messages_length_per_day} seconds for the voice messages.` +
`\n\nPlease try again tomorrow! \u{1F609}`;
// send text to user
await ctx.reply(answerMessage);
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'text',
question_text: questionMessage,
answer_status: 4,
});
return;
}
// get answer from Google Bard
const resAnswerText = await utils.getAnswer(questionMessage);
if (!resAnswerText || !resAnswerText.success) {
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'text',
question_text: questionMessage,
answer_status: 3,
});
// send text to user
await ctx.reply(resAnswerText.message || "Sorry. We couldn't get answer!");
return;
}
const folderPath = path.resolve(`./voices/${userTelegramId}`);
// check if user folder exists named userTelegramId, if not create it
utils.folderStructureSync(folderPath);
// filter/modify the response answer got from Google Bard
const filteredAnswer = await utils.filterAnswer(resAnswerText.message.content);
// text to voice
const resTextToVoice = await utils.textToVoice(filteredAnswer, folderPath);
if (!resTextToVoice || !resTextToVoice.success) {
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'text',
question_text: questionMessage,
answer_text: resAnswerText.message?.content || '',
answer_status: 3,
});
// empty folder
await utils.emptyFolder(folderPath);
// send text to user
await ctx.reply(filteredAnswer); // || "Sorry. We couldn't convert text to voice!"
return;
}
// send voice to user
const answerVoice = await ctx.replyWithVoice({
source: resTextToVoice.file_path,
});
// get answer voice
const answerVoiceFile = await ctx.telegram.getFileLink(answerVoice.voice.file_id);
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'text',
question_text: questionMessage,
answer_type: 'voice',
answer_text: resAnswerText.message?.content || '',
answer_voice_url: answerVoiceFile.href || '',
answer_status: 1,
});
// empty folder
await utils.emptyFolder(folderPath);
if (!dbUser.isAdmin) {
// review user limit
const limitExceeded = await handlers.isLimitExceeded(dbUser._id);
if (limitExceeded) {
const limit = new Date().getTime() + 24 * 60 * 60 * 1000;
await handlers.updateUser(dbUser._id, {
limit_exceeded: true,
limited_until: new Date(limit),
});
} else {
await handlers.updateUser(dbUser._id, {
limit_exceeded: false,
limited_until: null,
});
}
}
});
- Voice messages
bot.on(message('voice'), async (ctx) => {
try {
const questionVoiceFile = await ctx.telegram.getFileLink(ctx.message.voice.file_id);
const userTelegramId = ctx.message.from.id;
// check if user exists in DB, if not create it
let dbUser = await handlers.getUser(userTelegramId);
if (!dbUser) {
dbUser = await handlers.createUser({
telegram_id: userTelegramId,
username: ctx.message.from.username,
name: ctx.message.from.first_name,
// isAdmin: false,
});
}
const fileName = ctx.message.voice.file_unique_id;
const folderPath = path.resolve(`./voices/${userTelegramId}`);
// check if 'limited_until' exists and not expired
if (!dbUser.isAdmin && dbUser.limited_until && new Date() < dbUser.limited_until) {
const answerMessage = `Sorry, you have exceeded the daily limit.` +
`\nIt is max ${settings.max_questions_per_day} messages per day, ` +
`and max ${settings.max_voice_messages_length_per_day} seconds for the voice messages.` +
`\n\nPlease try again tomorrow! \u{1F609}`;
// send text to user
await ctx.reply(answerMessage);
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'voice',
question_voice_url: questionVoiceFile.href,
answer_status: 4,
});
return;
}
// check if user folder exists named userTelegramId, if not create it
utils.folderStructureSync(folderPath);
// download .oga file
await utils.download(questionVoiceFile.href, `${folderPath}/${fileName}.oga`);
// convert .oga to .wav
const resConvert = await utils.convert(`${folderPath}/${fileName}.oga`, `${folderPath}/${fileName}.wav`);
if (!resConvert) {
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'voice',
question_voice_url: questionVoiceFile.href,
answer_status: 3,
});
// empty folder
await utils.emptyFolder(folderPath);
// send text to user
await ctx.reply(resConvert.message || "Sorry. We couldn't convert your voice message!");
return;
}
// set this timeout to wait for converting (1000-3000ms is enough)
setTimeout(async () => {
// extract text from .wav
const resSpeechToText = await utils.speechToText(`./../voices/${userTelegramId}/${fileName}.wav`);
if (!resSpeechToText || !resSpeechToText.success) {
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'voice',
question_voice_url: questionVoiceFile.href,
answer_status: 3,
});
// empty folder
await utils.emptyFolder(folderPath);
// send text to user
await ctx.reply(resSpeechToText.message || "Sorry. We couldn't extract text from your voice message!");
return;
}
// empty folder
await utils.emptyFolder(folderPath);
// get answer from Google Bard
const resAnswerText = await utils.getAnswer(resSpeechToText.message);
if (!resAnswerText || !resAnswerText.success) {
// add a message to DB
await handlers.createMessage({
user: dbUser._id,
question_type: 'voice',
question_text: resSpeechToText.message || '',
question_voice_url: questionVoiceFile.href,
answer_status: 3,
});
// send text to user
await ctx.reply(resAnswerText.message || "Sorry. We couldn't get answer!");
return;
}
// filter/modify the response answer got from Google Bard
const filteredAnswer = await utils.filterAnswer(resAnswerText.message.content);
// text to voice
const resTextToVoice = await utils.textToVoice(filteredAnswer, folderPath);
if (!resTextToVoice || !resTextToVoice.success) {
await handlers.createMessage({
user: dbUser._id,
question_type: 'voice',
question_text: resSpeechToText.message || '',
question_voice_url: questionVoiceFile.href,
answer_text: resAnswerText.message?.content || '',
answer_status: 3,
});
// send text to user
await ctx.reply(filteredAnswer); // || "Sorry. We couldn't convert answer to voice!"
return;
}
// send voice to user
const answerVoice = await ctx.replyWithVoice({
source: resTextToVoice.file_path,
});
// get answer voice url
const answerVoiceFile = await ctx.telegram.getFileLink(answerVoice.voice.file_id);
await handlers.createMessage({
user: dbUser._id,
question_type: 'voice',
question_text: resSpeechToText.message || '',
question_voice_url: questionVoiceFile.href,
question_voice_duration: ctx.message.voice.duration,
answer_type: 'voice',
answer_text: resAnswerText.message?.content || '',
answer_voice_url: answerVoiceFile.href || '',
answer_status: 1,
});
// empty folder
await utils.emptyFolder(folderPath);
if (!dbUser.isAdmin) {
// review user limit
const limitExceeded = await handlers.isLimitExceeded(dbUser._id);
if (limitExceeded) {
const limit = new Date().getTime() + 24 * 60 * 60 * 1000;
await handlers.updateUser(dbUser._id, {
limit_exceeded: true,
limited_until: new Date(limit),
});
} else {
await handlers.updateUser(dbUser._id, {
limit_exceeded: false,
limited_until: null,
});
}
}
}, 3000);
} catch (err) {
console.log(err.message || "Something went wrong!");
}
});
For make sure your python scripts will work successfully, install these dependencies (you may use pip3 instead of pip for your case):
pip install SpeechRecognition
pip install bardapi
pip install --upgrade GoogleBard
In the end, create a voices/.gitignore file which will make you sure to have a directory for temporary audio files, which will be downloaded from Telegram API:
*
!.gitignore
Now your project is probably ready for work. To check that, just run:
npm run start
If you want to check the project in a development mode, then run:
npm run dev
If you want to deploy your project on a real server to run that 24/7, then you can use some wildely used dependency like forever. Make sure to have it installed. You can install it globally:
npm i forever -g
Run the project like so:
forever start -c "npm run start" ./
For listing all the forever-processes, run:
forever list
For stopping the runing project you can use the command below with the actual process-ID:
forever stop <PID>
That’s it!
You can check out the demo on this Telegram channel: sqca_bot.
Here’s the ⭐ GitHub repository, where you can find the code.
Feel free to ask any questions you may have about this article.
If you liked this article, please feel free to follow me here. 😇
To explore projects working with various modern technologies, you can follow me on GitHub, where I actively publicize much of my work.
For more information, you can visit my website: boolfalse.com
Thank you !!!

Top comments (0)