
Written by Leonardo Losoviz✏️
This article is part of an ongoing series on conceptualizing, designing, and implementing a GraphQL server. The previous articles from the series are:
- Designing a GraphQL server for optimal performance
- Simplifying the GraphQL data model
- Code-first vs. schema-first development in GraphQL
- Speeding up changes to the GraphQL schema
- Versioning fields in GraphQL
The internet is lousy with articles about what sets GraphQL apart from other APIs, namely REST. They all tout it for its strong type system, excellent developer experience, premier tooling, and ability to iterate rapidly on the schema, all without under- or overfetching. This is all true.
But what about directives? Surprisingly, very little has been written about them. Their implementation in the most popular GraphQL servers is not trivial, which may explain why directives are often overlooked.
According to the Apollo documentation:
Most of this document is concerned with implementing schema directives, and some of the examples may seem quite complicated. No matter how many tools and best practices you have at your disposal, it can be difficult to implement a non-trivial schema directive in a reliable, reusable way. Exhaustive testing is essential, and using a typed language like TypeScript is recommended, because there are so many different schema types to worry about.
It might also have something to do with the limited availability of directives in some popular GraphQL APIs. For instance, neither GitHub’s nor Shopify’s public schema offers a single directive. There simply aren’t many good examples for developers to follow.
Directives are generally not difficult to implement; if that’s the case for a particular GraphQL server, it’s likely because its architecture was not prioritized for directives. Some GraphQL servers have better support for directives than others.
So it makes sense that directives don’t always factor into the GraphQL-versus-REST discussion, but it’s a shame because they’re among the most powerful features of GraphQL. In this tutorial, we’ll attempt to fill the void by explaining how directives can enhance and empower our GraphQL APIs.

What are directives?
Simply put, a directive is a function that augments some other functionality. It is defined using the @ symbol. For instance, in the query below, the @upperCase directive is applied to the title field, converting its result to uppercase.
query {
post(id: 1) {
title
ucTitle: title @upperCase
}
}

{
"data": {
"post": {
"title": "Hello world!",
"ucTitle": "HELLO WORLD!"
}
}
}
You can think of directives like aspect-oriented programming (AOP) because they can be used to cross-cut other functionalities. For instance, in addition to being applied to a Post‘s title field, the @upperCase directive from the query above can be applied to any field of type String, such as the User‘s name , as shown in this query.
Thinking in terms of AOP, the best use cases for directives are the cross-cutting ones, where the functionality is generic and can be reused on different parts of the application. These include:
- Analytics/logging/metrics
- Authorization
- Caching
- Configuring default values
- Output manipulation
- Validation
It’s also possible to execute these cross-cutting functions in the resolvers themselves through middleware, as made available by Prisma’s graphql-middleware package. However, I believe directives are a better fit.
All directives are not created equal
It’s not immediately clear in the GraphQL documentation, but there are two types of directives:
- Schema-type directives, which are defined in the SDL and executed when building the schema
- Query-type directives, which appear in the query and are executed when resolving the query
We can visualize their differences through the three reserved directives in the GraphQL specification: @skip, @include, and @deprecated. These directives belong to the following types.
-
@deprecatedis a schema-type directive used to mark a field as deprecated in the schema definition -
@skipand@includeare query-type directives used to decide whether to execute a section of the query at runtime
However, the spec doesn’t call them query- or schema-type directives. Instead, it uses directive locations to define where a directive can appear.
There are two groups of directive locations: executable directive locations (i.e., query-type) and type system directive location (i.e., schema-type). Then, the @skip and @include directives can only be added to FIELD, FRAGMENT_SPREAD, or INLINE_FRAGMENT locations (i.e., fields or fragments in the query), and @deprecated can be added to FIELD_DEFINITION or ENUM_VALUE locations (i.e., the definition of a field or of an enum in the schema).
These two types of directives also provide a different level of visibility into the end user. Schema-type directives are private. They’re used by the GraphQL schema admins/designers/owners to configure the schema and are not exposed to the end user who is executing a query against the GraphQL endpoint. Why would the end user need to include the @deprecated directive when running a query? Query-type directives, on the other hand, are public. They’re provided to the end user to enhance their own custom queries.
Earlier I mentioned that GitHub and Shopify do not offer directives. That means their public schemas do not expose any query-type directive, but it says nothing about schema-type ones, which are private and accessible only to their own teams. Why don’t they have query-type directives? It could be because they have no compelling use case from which their users could benefit. It’s also possible that whatever functionality they require can also be implemented in the client application instead of at the API layer. For instance, a website can easily implement the @upperCase directive in JavaScript.
It seems that schema-type directives are more useful than query-type directives. Moreover, considering the aforementioned use cases for directives, only one use case (output manipulation) belongs to the query-type realm. All others (analytics/logging/metrics, authorization, caching, configuring default values, validation) are of the query type.
That said, both schema and query-type directives are very useful.
Why are directives important?
Let’s get down to the crux of the matter, the reason why I believe directives are a wonderful (and largely unappreciated) feature: they’re unregulated. Other than describing their syntax, the spec doesn’t say much about directives, giving each GraphQL server implementer free rein to design their architecture and decide what features they can support and how powerful they can become.
In fact, directives are a playground for both GraphQL server implementers and end users alike. GraphQL server implementers can develop features not currently supported by the spec, and users can develop features not yet implemented by the GraphQL server.
Directives’ unregulated nature is a feature, not a bug. To illustrate where directives come from and where they’re heading, let’s pause for a quick history lesson.
Debating the spirit of directives
Directives were originally introduced to support the @deprecated directive. Check out this issue logged on GitHub, for example.
On Nov. 4, 2019, maintainer tgriesser wrote:
[…] the SDL was never intended to be used as the means to construct the schema, and the @deprecated directive is only present in the SDL because it can also be represented in the introspection query
[…]
The fact that handwritten directives exist in the AST when writing-SDL first is only a result of that fact that it is valid syntax, but it’s not necessarily meant to be utilized in this way.
The team designing GraphQL at Facebook hadn’t seen the need to progress from there (circa 2015) and even considered removing directives altogether. As Lee Byron, co-creator of GraphQL, commented back then:
[…] we’re actually considering a change that removes directives from the schema completely.
Then, a short while later:
To be clear, directives are not designed to be extended by users of graphql, but by future versions of graphql core itself.
That’s the reason we’re considering removing them from schema. It’s too confusing as schema is something a user of graphql defines and produces, and directives being accessible from the same portion of code is the thing that doesn’t look like the others.
Directives were never removed, and different actors in the GraphQL ecosystem used them to extend their own functionalities, becoming essential elements for their solutions. As use of directives became more widespread, there were growing requests to grant directives a more important and standardized role. See this comment from 2018:
[…] since the GraphQL ecosystem has grown, I think we should think about interoperability with 3rd-party libraries. The examples that I am thinking about is Apollo cache control and Prisma, which are using directives to provide some metadata to make awesome underlaying features work.
There is no intention to freely incorporate directives into the spec, other than the exceptional use for @skip, @include, and @deprecated. Lee Byron replied to the above comment:
Directives are purely a feature of the GraphQL language and are not part of type definitions – this is because different tools will use and interpret directives in different ways.
With this, Byron indicated that he hadn’t changed his position on the issue. He better explained this in a comment from 2017:
Right now directives are purely a feature of the GraphQL language and IDL [“Interface Definition Language”, another name for SDL], so a schema not created using IDL definitionally won’t contain directives. When building a schema in code, you have the full power of the host programming environment, so directives shouldn’t be necessary. Directives are a tool for supplying additional intent to be later interpreted by the host programming environment.
On one side, Lee Byron wants to preserve the directives purely as a construction of the language to be used at a minimum. Meanwhile, part of the community wants directives to take a more unrestricted role when executing queries. Ivan Goncharov, maintainer of the specification as well as graphql-js, the reference implementation of GraphQL for JavaScript, explained the contrast between these two positions:
On the one hand, we want type system to be as strict as possible to make it easy to work with (in middlewares or in any other tool). On the other hand, we want directives to be as flexible as possible so 3rd-party developers can experiment with new syntax without forking GraphQL parser and creating new GraphQL dialect.
This comment also explains what Lee Byron meant when he described directives as “a tool for supplying additional intent to be later interpreted by the host programming environment.” If you didn’t understand it at first, don’t worry — you’re not alone.
Each GraphQL server vendor still controls directives in their entirety to power their own solutions.
Advancing GraphQL through directives
Directives fulfill a fundamental role for GraphQL. Although they’re not freely added to the spec, directives can still help improve GraphQL. Because directives are unregulated, implementers can experiment with them as they see fit to solve a given problem. If the produced feature becomes indispensable and can benefit GraphQL as a whole, then it’s considered for addition to the spec.
Directives are like a playground that helps evolve GraphQL. In that way, directives offer a glimpse of what the future of GraphQL will look like once it becomes standardized.
For a sneak peek at how directives are poised to improve GraphQL in the near future, check the aptly titled talk “A peek at the Future of GraphQL.” In it, Robert Zhu, who worked on GraphQL at Facebook, delivers a brilliant rundown of what directives the community is currently working on.
He mentions the following in particular.
-
@specifiedByattaches an optional URI to custom scalar definitions pointing to a document that holds extra information (data-format, serialization, and coercion rules) for the scalar. It’s currently in the draft stage -
@deferand@streamrender parts of the query faster, eliminating the need to wait for slower fields to compute (@defer), and starts rendering the first few entries in a collection without waiting for the entire set (@stream). These are currently in the proposal stage
Whereas @specifiedBy addresses incompatibility issues when servers talk to each other, @defer and @stream are expected to improve app performance, delivering an initial response that the user can consume as close to immediately as possible.
The @defer directive was first implemented by the Apollo server. Here’s an example of a GraphQL server implementing a feature that is missing from the spec and eventually becomes so useful that it is proposed for the spec.
And then we have features that are missing from the GraphQL servers and implemented by users through custom directives. For instance, the [RFC] Flat chain syntax issue proposes to combine the results from nested objects, like this:
{
clients(limit: 5) {
id
programs: programs.shortName
}
}
This would produce the following response.
{
"data": {
"clients": [
{
"id": 2,
"programs": ["ABC","DEF"]
},
{
"id": 3,
"programs": ["ABC", "XYZ"]
}
]
}
}
This behavior, still unsupported by the server, is available as part of the graphql-lodash library, which offers a directive @_ to shape the response of the query.
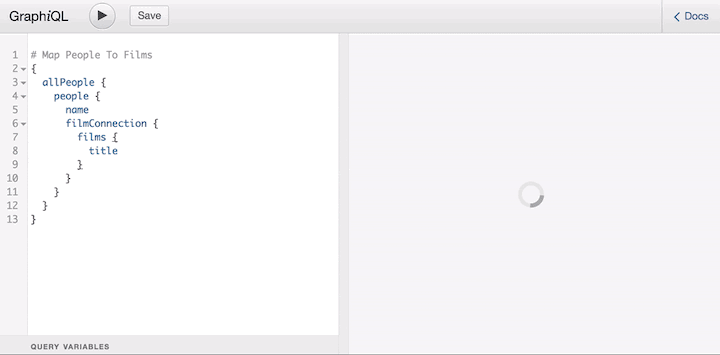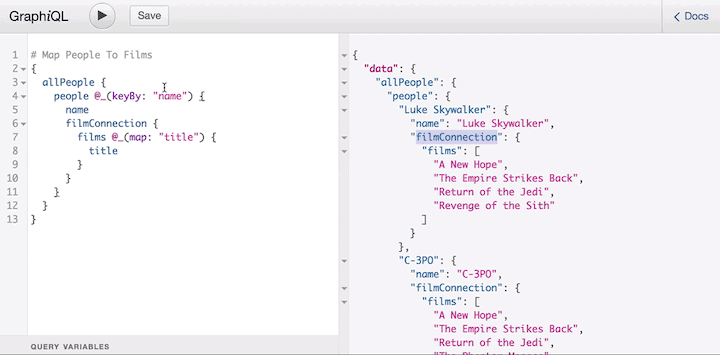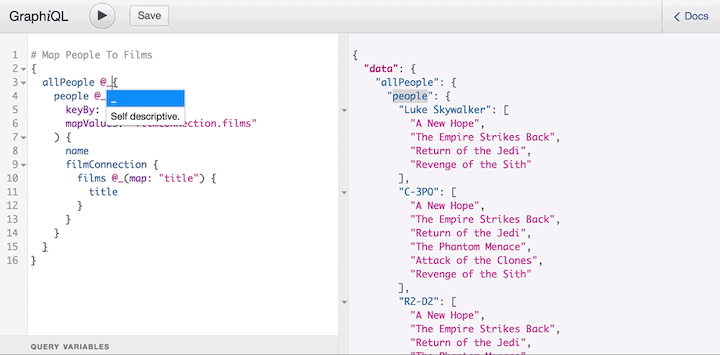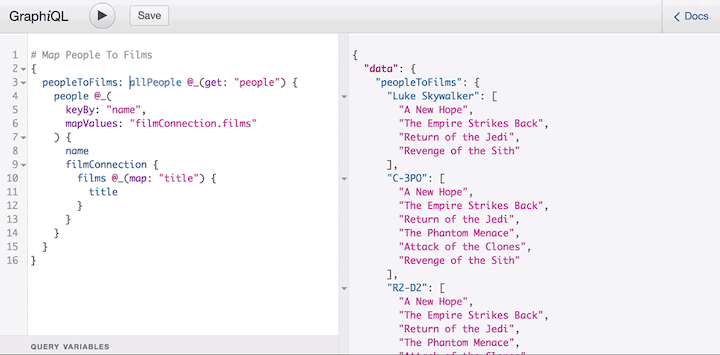
This directive is just a temporary solution until the proposal makes it through the last stage of the process (it’s currently in the strawman stage) and is added to the spec, at which time all GraphQL servers must satisfy the new syntax. But even if that day never comes, users don’t need to wait to use the feature.
In one of my own projects, I implemented an @export directive for my GraphQL server in PHP, which exports the value of a field (or set of fields) into a variable to be used somewhere else in the query. This feature was requested in the [RFC] Dynamic variable declaration issue, which is also in the strawman stage.
Directives fill the void when the GraphQL server requires a feature that is not part of the spec. Custom directives fill the void when you require a feature that the GraphQL server doesn’t provide.
Shopping for GraphQL servers
How do you choose between the myriad GraphQL servers that are available? Assuming you expect your API to be in active development for the long term, start by asking the following:
- Does it support creating custom directives?
- How powerful can the custom directives be?
Servers that provide robust support for custom directives will lead the way into the future of GraphQL. They’re well-positioned to implement novel features before everyone else and become a reference implementation for the others to imitate. The better the support for custom directives, the more likely a server is to be up to date and compatible with the latest specification.
Conversely, servers that approach directives as an afterthought risk producing APIs that grow stagnant and increasingly difficult to upgrade, making them a poor long-term investment.
Directives are not a cure-all
Directives are not a solution to everything. Use them, but don’t abuse them.
As I mentioned, directives are great for extending GraphQL functionality, but they’re not the most suitable tool for every kind of functionality. Some tasks are better tackled by field resolvers. For others, directives simply do not provide an optimal solution.
Let’s examine a few problems I’ve encountered with directives. These examples demonstrate why directives are not quite the Swiss Army knife they might initially seem to be — at least, not yet.
Defining directives for a type of result or specific field
I’ve produced a @cdn directive for my own GraphQL server in PHP, which transforms a URL (a custom scalar) type by replacing its domain with the domain from my CDN.
query {
user(id: 1) {
url
cdn: url @cdn(from: "https://newapi.getpop.org", to: "https://nextapi.getpop.org")
}
}
Running this query produces the following.
{
"data": {
"user": {
"url": "https://newapi.getpop.org/author/leo/",
"cdn": "https://nextapi.getpop.org/author/leo/"
}
}
}
This directive only makes sense when the field is of type URL, for which there are only handful of fields in the schema: the url field for User and Post and src from the Media type.
Ideally, I’d like to define in my schema that the @cdn directive is available only when the field is of type URL or when it’s applied to a list of whitelisted fields. Unfortunately, all I can do is define its directive location to be FIELD or FIELD_DEFINITION, but not which field or whose definition.
I have seen some workarounds for this issue. For instance, Apollo suggested the following solution for an @upper directive.
class UpperCaseDirective extends SchemaDirectiveVisitor {
visitFieldDefinition(field) {
const { resolve = defaultFieldResolver } = field;
field.resolve = async function (...args) {
const result = await resolve.apply(this, args);
if (typeof result === "string") {
return result.toUpperCase();
}
return result;
};
}
}
Since the @upper directive can only be applied to Strings, Apollo proposed validating if (typeof result === "string") { before applying the logic. This makes me shudder. What’s the point of GraphQL’s strong type system if you simply accept every type and validate it with some custom logic, ready to produce some bugs down the road?
In this case, GraphQL would be better off if directives could receive fine-grained information on their directive locations.
Code-first solutions become second-class citizens
In a previous article, I described the difference between the schema-first (SDL-first) and code-first approaches to creating a GraphQL service. The main difference is that the code-first approach doesn’t rely on the SDL for creating the schema.
Since schema-type directives are a construction of the SDL, when there is no SDL, there are no such directives and the GraphQL server misses out on tons of features. That’s the case or Nexus, for instance. Because it’s a code-first solution, it finds itself unable to implement support for Apollo federation , which relies on a few custom directives defined on the SDL.
Passing inputs to schema-type directives can be ambiguous
This may be an exceptional case, but it’s good to know in case you ever encounter it in your projects.
The Apollo documentation explains how to implement a @date directive, which receives its optional format input as a field argument from the field it modifies, today.
graphql(schema, `query {
today(format: "d mmm yyyy")
}`).then(result => {
// Logs with the requested "d mmm yyyy" format:
console.log(result.data.today);
});
The problem is that you can apply multiple directives to the same field. These directives may have been created by different vendors — meaning you can’t control them — and may expect arguments with the same name.
For instance, a src field from the Image type could have the directives @darkenColors and @resize applied. This would modify the image accordingly, save it on the cloud, and return the URL of the new image. If both directives receive an argument percentage (the first one to indicate the amount of darkening to be applied to the image and the second one to specify how to resize the image), then querying the src(percentage: "50%") field is ambiguous. Does "50%" apply to the darkening or the resizing?
Directives modify types
Following the example above, the today field returns a Date, and this type is converted to String when applying the @format directive. This behavior is confusing and goes against the idea of strong typing.
I proposed a solution to this problem: composable fields to allow fields to act as inputs to other fields. That way, if the format field is of the String type and receives an input of the Date type, it could compose a today field of type Date like format(today, "d mmm yyyy"), which is similar to [this query](https://newapi.getpop.org/api/graphql/?query=posts(limit:5).title%7CupperCase(title(), using a modified syntax. My proposal is unlikely to be approved, however, because it introduces a new way to parse a field and breaking changes are highly discouraged.
Conclusion
Directives are among the most useful and interesting GraphQL features, but you wouldn’t know it from reading the vast majority of blog posts and articles about what makes GraphQL special. Directives are underappreciated and super-powerful.
How strong is the support for directives in your GraphQL server? Does it allow you to do every functionality you could dream of? What about very basic functionality? Is it difficult or easy to implement?
Everyone can make use of the same tooling (such as GraphiQL) to improve the developer experience and boost productivity. Every GraphQL server supports fetching exactly the data you need without under- or overfetching. But not every GraphQL server provides the same support for custom directives. Ultimately, this may be the single most important factor in separating the GraphQL services that will withstand the test of time from those that will eventually become stagnant and have to be reimagined from scratch.
Put simply, directives must not be afterthought. So when shopping around for GraphQL servers, evaluate their support for custom directives before you even think about the other features.
Monitor failed and slow GraphQL requests in production
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you're interested in ensuring network requests to the backend or third party are successful, try LogRocket.

LogRocket is like a DVR for web apps, recording literally everything that happens on your site. Instead of guessing why problems happen, you can aggregate and report on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.
The post GraphQL directives are underrated appeared first on LogRocket Blog.

Top comments (0)