Machine Learning — NLP Vectorization Techniques
Whenever you start with any ML algorithm that involves text you should convert the text into a bunch of numbers. This is obvious because ML algorithms usually build a probabilistic model(which is math) and math can deal only with numbers.
The process of converting NLP text into numbers is called vectorization in machine learning.
Word Vocabulary
Vocabulary is the list of all the words you are dealing with. If your dataset can contain 1000 documents then your word vocabulary would be a list of unique words from the document. For a generalized chatbot, your vocabulary will have all the words in the language dictionary. For a customer success bot, it will have a language understanding as well as the words with respect to the products or services you provide.
Bag of words(BoW)
The simplest and most powerful vectorization technique. Given a bunch of sentences BoW is creating a table of words with it’s associated a score denoting it_s_ contribution to the document.
The scoring can be done based on any of the following scoring techniques
- Word Count — (No of occurrences)
- Word Frequency — (No. of occurrences/Total number of words)
- TFIDF Vectorizer — The word that occurs the least carries the most information about the document
Applications : BoW is used in spam filtering. Given an email and frequency of words in the email, the simplest approach would be to figure out whether the most occurring words are spammy. TFIDF is used in topic modeling and document tagging.
BoW also found itself a spot with computer vision where the image features are treated as a word vectors and preserved in a sparse matrix.
Word2Vec
Word2Vec is a strategy where words are represented as a bunch of numbers. These numbers(Vectors) are not assigned in random they are assigned in such a way that two similar words are closer together in a vector space.
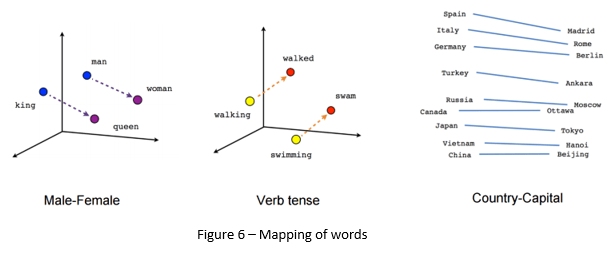
Applications
- Parts of speech tagging
- Entity Extraction
- Chatbots


Top comments (0)