
Becoming familiar with the Project
Coming into the final month of the six month program of Lambda School FullStack Development course, there is a program known as Labs. In this month, there are a variety of different projects you can get assigned to, but I got the awesome opportunity to work on something called Human Rights First Asylum. This is a tool intended for lawyers to better prepare for their asylum cases by provided a web-based platform to upload cases that would be scraped for relevant data, and that data could be shown in visualization that would reflect data in our database. This ultimately allows for lawyers to see relevant data from the cases they uploaded to try to see trends in how a judge may ultimately decide how to preside on a case and better prepare.
I participated on this project in the month of July of 2021, and found it was a product that has been worked on for about 5 to 6 months previously. Although the lifetime of this project has existed long before my team and I got our hands on it, we were allowed about a month of time to make changes. This meant we would have a lot of challenges to overcome in this short timeline, but it was a challenge the entire team was ready to take on since we all wanted to show off the coding chops that we had learned over the past 5 months.
In our team, we had split up into a number of roles in order to have more clear cut goals in what we want to work on. In the end, we had 3 Data Science Engineers, 4 Backend Engineers, 4 Frontend Engineers, 2 User Interface/User Experience Designer, and finally 2 Technical Project Leads. With my personal interests lying in the Backend, I took up that Backend Engineer role. Since this is a role that connects the frontend to the backend, I found myself touching base with almost the entirety of the team, save for UI/UX. In order to have endpoints the frontend could use, we had to communicate with the Frontend Engineers on what those endpoints would looks like. Similarly, the Backend Engineers worked closely with the Data Science Engineers to take their data visualizations and present them to the frontend. To help facilitate the these connections, the Technical Project Leads helped fill in the holes and make meetings with some outside resources in order to help solve our issues.

# finding problems
What is our issue?
I had the main problems I worked on this project related to realizing the missing Moderator role and implementing and updating some of our endpoints to help visualize data about judges. The one I want to talk about today is about implementing those endpoints because I ran into a lot of unique problems that I had not run into before working in an existing codebase and trying to make these endpoints work.
On the developer roadmap, something a few of the Backend Engineers saw from the inherited issues from the last team working on this project. One of the was just “Backend Judges endpoint need to be updated- buried in an old PR”. Me and another team member jumped into this problem to try to understand what exactly this entailed and what needed to be implemented. What we ended up figuring out was that there were many different endpoints that existed that had been built by upwards of 5 to 6 individuals and were built for many different cases. However, none of them had built for the current iteration of the project with the changes made to the Data Science API. Reaching this conclusion was a long process with a lot of work between Data Science and Backend though.
Can we fix it?
In order to solve the problem, I dove into the codebase with one my Technical Project Lead, and just tried to comprehend and update what was going on. There were a plethora of issues from using a judge’s first name in order to retrieve information for them (which obviously overlapped, even in our dummy data), to endpoints using the same url, if the frontend were to actually use them, it would try to access two endpoints at the same time. We broke down each of these endpoints and went through the router and model in order to understand what other functions these endpoints access. This is how we found the extent of some of the issues that existed.
Since this felt so complicated, my TPL and I stuck through this together in order to try to identify the source of each of these issues. However, the scope of the problem was to such an extent that we needed to understand the data science APIs output clearly and reached out to people who used to work on the project to understand what their goals in writing some of these endpoints were. One of these people was extremely helpful in opening the door to my understanding of how these issues came about.
What had happened is that a lot of the code was either made to work in the future, or made to work for the current iteration of the project. For instance, we found that code to help import and read CSV files so that the original version of the project, which would take manually scrapped cases in a CSV file, could process the asylum cases. However, despite this code being deprecated because we upload cases using PDFs now, it was continually updated. Some other pieces of code were made with the assumption that the data science endpoints would function a certain way, but the data science endpoints did not exist yet and were not built when we took over the project. In order to tackle this, we decided to make a number of updates to the code.
Yes we can!
Despite these problems continually cropping up in the code, we decided to make a number of cases to normalize our endpoints and update them so that they will function better in the future and make more sense. In order to do this, we needed to talk to the data science API, as well as our stakeholders in order to understand what still needs to be functional after we are done.
Starting off, we made comments on the old code that wasn’t working in the codebase anymore. We talked to the stakeholders and they didn’t want to remove the functionality completely since there may always be case information from a CSV that could come in and it would be great to upload in the future. However, we at least warned future learners coming onto the project about how it worked and functions that are involved with this functionality. In addition, we helped make some changes to some of those existing functions so that they take a unique judge id instead of a first name which many judges could share.
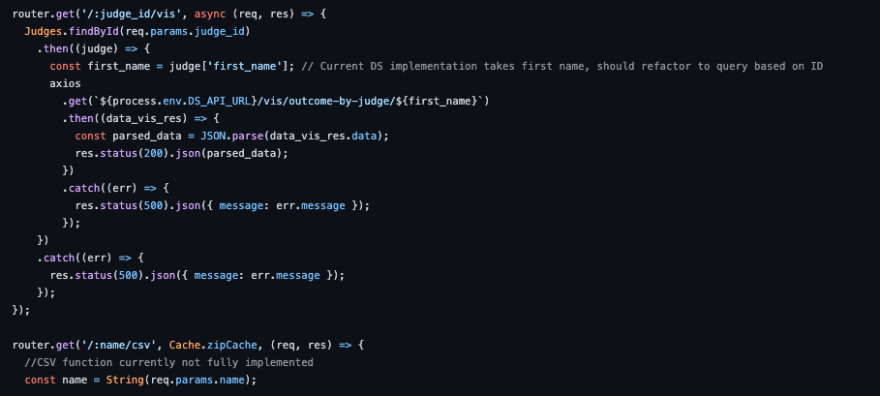
Leaving helpful hints!
We then talked to and participated in meetings with our Data Science Engineers to understand how our data visualizations are being outputted. There were some existing problems such as appellate cases coming out as a list of judges, not separated by individual names, but understanding some of these issues let us work with some of the endpoints, such as the function that assumed how the data science API would work, and rewrite it so that it worked with now existing data science code.
Let's step back and take a look
The result of our work was a lot of cleanup with a functioning backend endpoint that accessed the data science API to deliver a json string to the frontend that could be taken and developed into a data visualization for our asylum lawyers to use. It is not the most robust code yet since we ran out of time, but it is an excellent foothold to start off with. However, our goal wasn’t just to make the endpoint work.
Our goal was to cut down most of the time it took for me and my teammate to understand the ins and outs of our codebase to maybe a few hours instead of the multiple day journey we took. I believe we achieved that goal by reducing the deprecated code that we assumed was being used, commenting code that may actually need to be updated in the future for useful features, and normalizing all the endpoints properly so that they are truly functional.
However, some of the challenges that may come along the way are introducing those new useful features that we intended. Like I mentioned earlier, the appellate cases judges are more difficult to gather from the data science API, which could make it harder to identify which judges are on which cases and how they decided to make their decisions. Also, filters are almost necessary to have these data visualizations be a useful function for these lawyers. Seeing information based on a certain period of time, or state, or country of origin are all very important, but since not much progress has been made on this front yet, it will certainly be a challenge to complete and make sure it works with the data science API and the frontend.
Moving forward
However, through all of these challenges, I am definitely a better programmer after this Labs experience. I believe I am a much better technical communicator to speak toward a large project such as this one. I haven’t worked on anything nearly this large, but I learned how to ask the questions I needed to in order to understand code that was completely new to me, or in a language I don’t code in. Since the backend binds this program together, I had to learn how many new and different things worked, like the existing codebase, Okta, or the python data science API worked, and used that knowledge to communicate our issues to others and explain what information I needed to solve the issues I had.
Incidentally, I found that this has really helped shape my direction as a programmer. Initially, I really enjoyed frontend programmer because I could easily see the changes I would make. However, now that I have worked on this program with many different technical disciplines, I felt like my knowledge really grew as a programmer and saw how the backend binds all of these moving parts into a working product. One of my future career goals is to eventually branch out from being a web developer and work on new software projects, and maybe one day be able to code my own video game. This felt like my first step toward this goal, moving away from the front end and working to bind the new part that a video game would undoubtedly have and understand how I could overcome the challenges it would present me.





Top comments (0)