Zeebe.io — a horizontally scalable distributed workflow engine
Say hello to cloud-native workflow automation — part 1
There are many use cases for workflow automation out there. Many people think that workflow automation is only used for slow and low frequency use cases like human task management. Despite the fact that this is not true (see e.g. 24 Hour Fitness or Zalando) I do see limitations of current workflow technology in terms of scalability, but on a very different order of magnitude. As traditional engines are based on relational databases they are naturally limited in scale to what that database can handle. Even if this is sufficient for most companies, I know there are definitely interesting use cases requiring more performance and scalability, e.g. to process financial trades which need soft real-time guarantees under a very high load.

Over the last few years a lot of smart folks at Camunda dived deep into the question of how to scale a workflow engine beyond smaller iterative improvements. The result of this thinking lead us to the source-available project Zeebe.io. And we’ve just released the first production-ready version of it!
Zeebe will push the frontiers of what workflow automation can do as it provides true horizontal scalability. That means that adding nodes to the system will result in being able to process more load — and this increase is linear.

The key ingredients to achieve this are:
- Zeebe is a truly distributed system without any central component, leveraging concepts like Raft Consensus Algorithm for scalability and resilience.
- Zeebe uses event sourcing and event streaming concepts as well as replicated append-only log. Partitioning allows for scaling out.
- It is designed as reactive system according to the reactive manifesto.
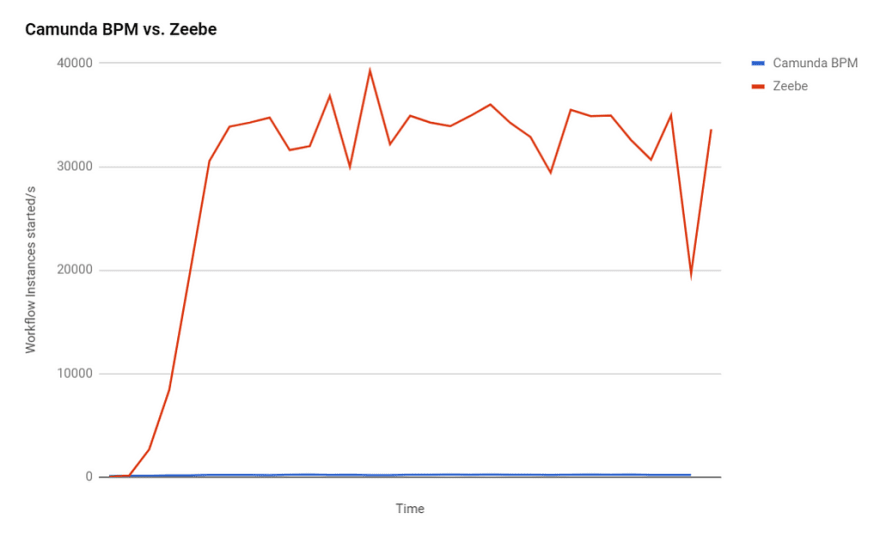
As a result, Zeebe is in the same class of systems like Apache Kafka. In early attempts we could process roughly the number of events per second as Kafka, which was a few hundred times faster than Camunda 7.8 (which is an example for a traditional workflow engine, and actually even the fastest open source one according to a study by the university of Lugano in May 2016):
So how could we achieve this? One important idea is to build an event sourced system.
An event sourced workflow engine
Traditional workflow engines capture the current state of a workflow instance in a database table. If the state changes the database table is updated. Simplified, it looks like this:
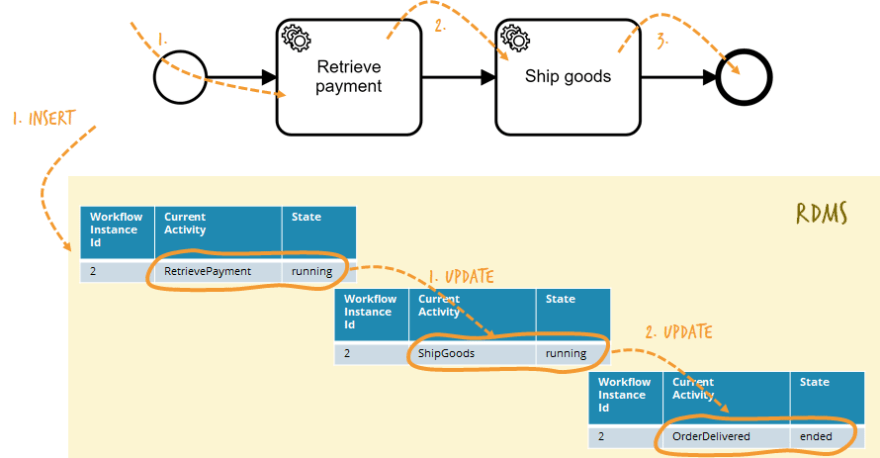
Using this approach the workflow engine can leverage a lot of guarantees from the relational database (RDMS), e.g. ACID transactions.
Zeebe works very differently and leverages event sourcing. That means that all changes to the workflow state are captured as events and these events are stored in an event log alongside commands. Both are considered to be records in the log. Quick hint for DDD enthusiasts: These events are Zeebe internal and related to the workflow state. If you run your own event sourced system within your domain you typically run your own event store for your domain events.
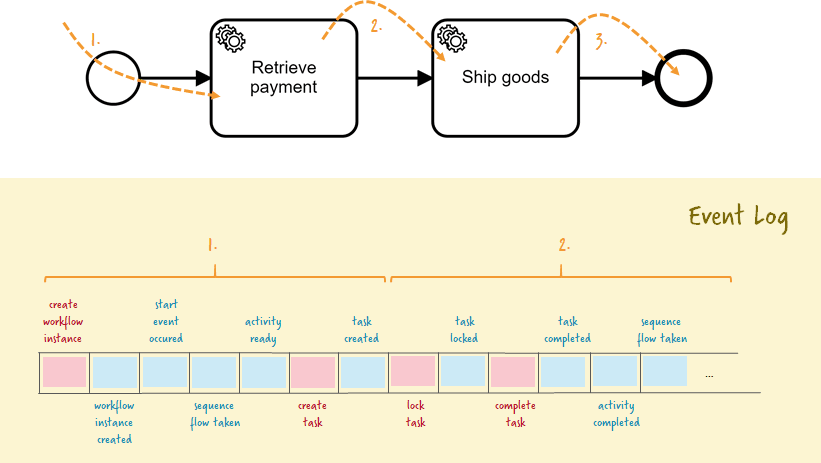
Records are immutable and therefore the log is append-only. Nothing will ever be changed once it is written, it is like a journal in accounting. Append-only logs can be handled and scaled very efficiently, something we will dive deeper into in part two of this article.

The current state of a workflow can always be derived from these events. This is known as projection. A projection in Zeebe is saved internally as snapshot leveraging RocksDB, a very fast key-value store. RocksDB allows Zeebe internally to find certain objects by key, as a pure log would not even allow for simple queries like “give me the current state for workflow instance 2”.

Zeebe stores the log on disk. Currently this is the only supported storage option (other options like e.g. Apache Cassandra are regularly discussed, but not on the roadmap so far). RocksDB also flushes the snapshot state to disk, which not only creates much faster start-up times, but also allows Zeebe to delete processed records from the log, keeping it quite compact (something we will dive deeper into in part two of this article).
In order to achieve performance, resilience and scalability we applied the following distributed computing concepts:
- Peer-to-peer clusters, Gossip,
- Raft Consensus Algorithm,
- Partitions,
- High-performance computing concepts and the high-performance protocol gRPC.
I cover this in-depth in part two of this post: how we built a highly scalable distributed state machine.
Zeebe architecture and usage example
Zeebe runs as an own program on a Java Virtual Machine (JVM). Relating to architecture options to run a workflow engine this is the remote engine approach, as the application using Zeebe talks remotely with it. But as we leverage streaming into the client and use binary communication protocol this is very efficient and performant. Its huge advantage is that the broker has a defined setup and environment and cannot be influenced by your application code. So this design decision provides proper isolation, we learned the importance of that in years of experience supporting a workflow engine.
Visual workflows
Zeebe uses visual workflow definitions in the ISO standard BPMN, which can be modeled graphically with the free Zeebe Modeler.

If you prefer you can also use a YAML to describe workflows, e.g.:
https://medium.com/media/5d536155037b6f30f5809bb1439018db/href
Please note, that not all language constructs are currently supported in YAML.
Native language clients supporting reactive programming, streaming and back-pressure
A workflow can include so called service tasks. When an instance reaches these tasks some of your code needs to be executed. This is done by creating Jobs which are fetched by JobWorkers in your application. Zeebe provides native language clients, e.g. in Java:
https://medium.com/media/79b16d0be1130a17e63a14d2cac2830e/href
or in NodeJs:
https://medium.com/media/ee3403f1e552007012eaade0528d7769/href
or in C#:
https://medium.com/media/d0f6d9d0e0ef16537c2c8beb84c3b3ff/href
or in Go:
https://medium.com/media/9cd7ce1e5144881915419a776313f87f/href
Or in Rust or Ruby. More languages will follow. And thanks to gRPC it is easy to use almost any programming language, as described in this post of how to use Python.
As you might have spotted in the code, you can use a reactive programming model in your application.
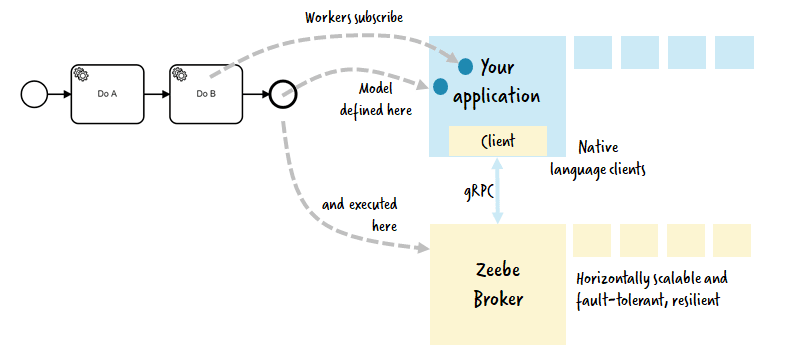
You can connect as many clients to Zeebe as you want to and the Jobs will be distributed (currently in a round-robin fashion) allowing for flexible scalability of the workers (up and down). Zeebe will soon support back-pressure, so making sure that jobs are provided only in a rate a client can process them. No clients can be overwhelmed with work. If in doubt the jobs are saved in Zeebe until new clients connect.
Clients are competing consumers which means that one job will only be executed by exactly one of the clients. This is implemented using a lock-event which needs to be written to Zeebe before a job can be executed. Only one client can write that lock-event, other clients trying to do so get an error message. A lock is held for a configurable amount of time before being removed automatically, as Zeebe assumes that the client has died unexpectedly in this case.
Transaction and at-least once semantics
It is important to note that Zebee Clients do not implement any form of ACID transaction protocols. This means that in case of failures no transaction will be rolled back. With this setup you have two design alternatives:
- You commit the transaction to your domain and afterwards notify Zeebe of the completion of the job. Now your app could crash in between the commit and the complete. So Zeebe would not know that the job is completed and hand it over to another client after the lock timeout. The job will be executed again. The semantic is “ at least once ”.
- You complete the job first and afterwards commit your transaction. If the app crashes in between you probably have completed the job but not committed the transaction. The workflow will have moved on. The semantic is “ at most once ”.
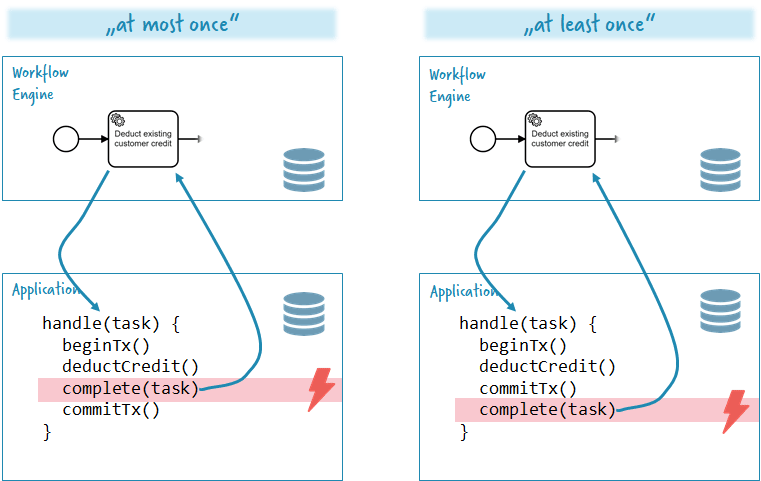
Most of the time you will decide to go for “at most once”, as it makes the most sense in the majority of use cases.
As your code might be called multiple times you have to make your application logic idempotent. This might be natural in your domain or you might think of other strategies and create an Idempotent Receiver (see e.g. Spring Integration). I tackled idempotency briefly in 3 common pitfalls of microservices integration — and how to avoid them and plan an extended article on it.
Queries via CQRS
The Zeebe broker is responsible for executing running workflows. It is optimized to apply new commands to the current state in the way to reach the performance and scalability goals mentioned in the beginning. But the broker cannot serve any queries like “what workflow instances were started this morning between 8 and 9 but haven’t finished yet?”. As we are not using a relational database anymore we cannot do simple SELECT statements. We do need a different way to handle the so-called query model in this case.
This way of separating command and query model is known as Command Query Responsibility Segregation (CQRS) with big advantages:
CQRS allows you to separate the load from reads and writes allowing you to scale each independently. […] you can apply different optimization strategies to the two sides. An example of this is using different database access techniques for read and update.
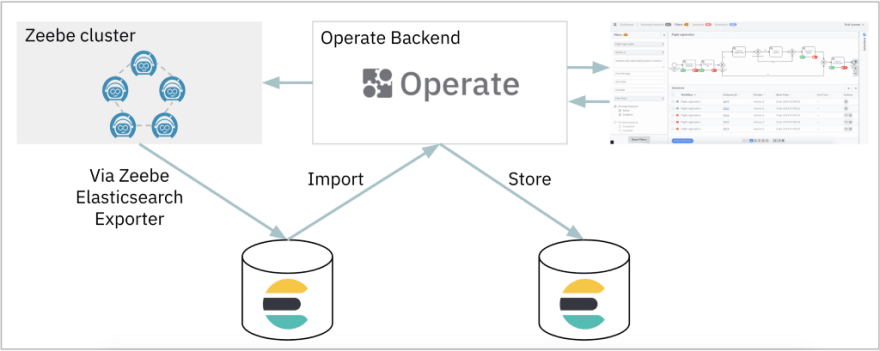
This is exactly what we do with Zeebe. The Broker leverages event streaming and optimizes for high throughput and low latency. But it does not provide query capabilities. That’s why Zeebe provides so called Exporters which can access the whole event stream. One out-of-the-box exporter is for Elasticsearch. By using it all events are written to Elastic and stored there, ready to be queried.
Zeebe now comes with an operation tool you can use to look into the workflow engine: Operate. You can see what’s going on, recognize problems (so called incidents) as well as root-causing and fixing incidents.

Operate is also built to scale and uses its own optimized indices on Elasticsearch:
Source-available license and open source
One interesting side note goes on open source. You might follow the latest development around source-available licenses (e.g. from Cockroach Labs, Confluent, MongoDB, Redis, Timescale). The background is that cloud vendors can simply take existing open source projects and provide a managed service offering, without paying anything back to the community. And big cloud vendors can typically leverage their market position to compete easily with managed service offerings of the open source companies themselves. This could drain the communities, but also turn into an existential threat for companies with the core developers on the payroll. In the long run this could kill a lot of innovation. Source-available licenses protect open source companies from that threat, even if the Open Source Initiative (OSI) doesn’t acknowledge these licenses as open source, hence the clumsy name.
Zeebe is distributed under The Zeebe Community License, a comparable source-available license. It
- Allows what the MIT license allows (basically everything), except
- it does not allow you to offer a commercial workflow service that uses Zeebe
This license allows for all intended use cases of existing users and customers. It actually “feels” like MIT. You can download, modify, and redistribute Zeebe code. You can include Zeebe in commercial products and services. As long as you don’t offer a generic workflow service.
Summary
Zeebe is designed as a truly scalable and resilient system without a central database. It is very performant. It can be used together with almost any programming language. It uses visual workflows in BPMN, that allow for true BizDevOps. This combination sets it apart from any orchestration or workflow engine I know of.
It is Open Source (or source-available to be precise) and the usage is pretty simple. So there are no barriers to get started.
Got an appetite to learn more about the distributed computing concepts we used to build Zeebe? Move on to my deep dive article how we built a highly scalable distributed state machine.
Bernd Ruecker is co-founder and chief technologist of Camunda. I am passionate about developer friendly workflow automation technology. Follow me on Twitter. As always, I love getting your feedback. Comment below or send me an email.

Top comments (0)