Webinar FAQ for Monitoring & Orchestrating Your Microservices Landscape using Workflow Automation
Answering leftover questions from my webinar in March 2020

On Wednesday, March 11, 2020, I conducted the webinar titled “Monitoring & Orchestrating Your Microservices Landscape using Workflow Automation”. Not only was I overwhelmed by the number of attendees, but we also got a huge list of interesting questions before and especially during the webinar. Some of them were answered, but a lot of them were not. I want to answer all open questions in this blog post.
Unfortunately this post got a bit long — sorry, I did not have the time to write a shorter one. Feel free to jump to the question that interests you right away!
- BPMN & modeling related questions (6 answers)
- Architecture related questions (12)
- Stack & technology questions (6)
- Camunda product-related questions (5)
- Camunda Optimize specific questions (3)
- Questions about best practices (5)
- Questions around project layout, journey and value proposition (3)
- Wrap-Up
Note that we also started to experiment with the Camunda’s question corner and discuss to make this more frequent, so keep an eye to our community for more opportunities to ask anything (especially as in-person events are canceled for some time).
You can find the recording of the webinar online, as well as the slides:
https://medium.com/media/4f72e3d728297208c085100e28ced5e5/href
BPMN & modeling related questions
Q: How to present BPMN diagrams so that common people can understand it?
There is not a simple answer to that. But due to my experience most “common people” can understand a basic subset of BPMN easily. For our Real-Life BPMN book we did a chart showing the elements we see used most often in automation-related projects:
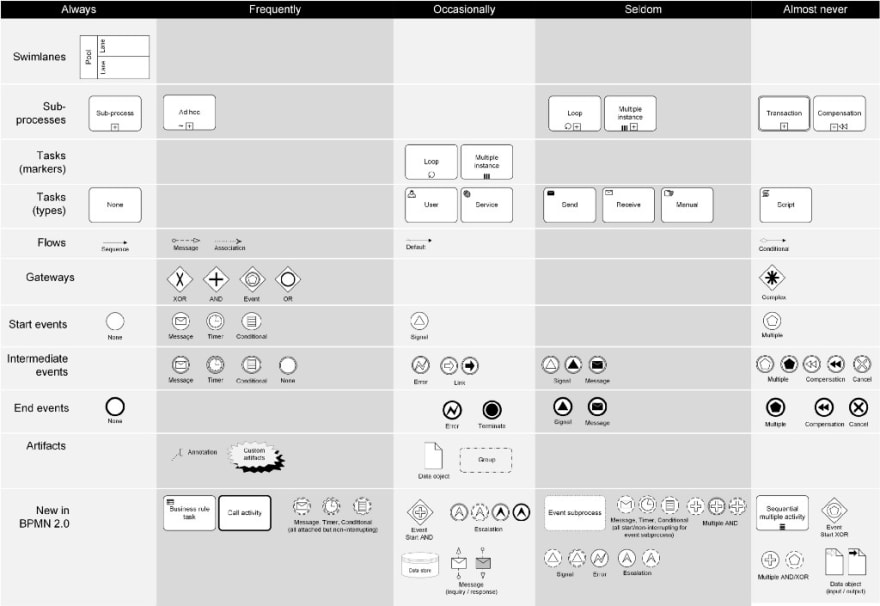
You can typically express a lot with the subset of “Always” or “Frequently”. And these symbols are intuitive — at least with a bit of training or explanation on the go.
But comprehensible models should also comply with certain best practices — you can find one example in Create Readable Process Models.
Last but not least, it is important to not model every implementation aspect in BPMN. Remember, that a workflow solution is BPMN + programming code, so you can choose what to express in the BPMN model and what you express in the programming language of your choice (I wrote a whole section about this in my upcoming book, but the super-condensed rule of thumb is: default → Programming, activities where you have to wait → BPMN, activities that should be visible → BPMN).
Q: Does the Camunda Process Engine in its open-source version supports the entire and complete BPMN 2.0 descriptive symbol set?
There is no difference in BPMN symbol support of the Camunda community and enterprise edition.
Camunda supports almost all symbols. We never missed something in recent real-life projects. You can find the exact coverage in the documentation (this overview does make the gaps transparent).
Q: Why do you name events and functions in the BPMN model in the same style? Why not e.g. receive payment for a function? It is not fully textbook to model events as activities
This question might relate to this workflow model I created in the webinar when I talked about that Camunda Optimize can do monitoring on pure events flowing around (even in scenarios where you do not use any workflow engine):

And there are indeed two flaws with this model — well spotted. First of all, it violates our typical naming convention, whereas every task is named with “object verb”, meaning that would result in:

While this is indeed better named, it has the downside that the exact event names are no longer shown. If you want to keep the event names from your application, we could model:

I do agree that this might be the most accurate way of modeling this situation. But in this case, I decided on tasks instead of events for two reasons: This might be more intuitive for business people when they look at the workflow model. Doing the payment will take a bit of time, so events are confusing to some people. And second: I often give this kind of demo to people that do not (yet) know BPMN, and they also seem to understand boxes and arrows quicker. Especially as I typically also show timer boundary events in the same talk, I don’t want to introduce too many different modeling alternatives at once.
As this workflow model is “only” used in Optimize to project events onto, you have a bit of freedom anyway. So in this example, it might even be a good idea to model:

There is no right or wrong modeling here, at least, to my gut feeling. But I do agree that the model I did in the heat of the moment might not be the best choice to do in a real-life scenario.
Q: In the orchestration scenario, BPMN usage appears to be more or less limited to post-run analysis?
In the orchestration scenario I used the Camunda engine within the order fulfillment microservice. Why do I do this — what is the value?
- The workflow engine can wait, e.g. until a response or event happens — potentially much later. I can also leverage timer events to react if something takes too long.
- I can use the operations tool to see what is currently going on. This gets especially interesting if something is failed or stuck (which I did not simulate in the webinar).
- Of course you can use the audit data from the workflow engine to do further post-run analysis, but I did not dive into that in the webinar.

Q: Are you going to continue to work on CMMN?
At Camunda we are in maintenance mode with CMMN. We do support the existing features and fix every possible bug around it. But we do not actively develop it further. I want to quote a paragraph from the latest edition of our Real-Life BPMN, where we explained the reasons:
We gave CMMN two years to take off, but, within that time, we experienced limited value from CMMN in our projects, especially if you compare it to BPMN or DMN. One observation was, for example, that most logic in CMMN models was hidden in complex rule-sets if certain activities are possible, impossible, mandatory or unnecessary. These rules were often expressed elsewhere and also not represented graphically. Exaggerating a bit, the CMMN model becomes kind of a graphical bullet point list. So we decided to remove CMMN from this book to not confuse anybody that just embarks on their BPM journey. Instead we want to emphasis how to tackle unstructured processes with BPMN in section 4.5.5 on page 142 and point out the limits of this approach.
You can learn more about that decision in the webinar for the 4th edition.
Q: Would it possible to integrate a testing module to help users see the result of newly created DMN before deploying it to production?
Yes, that is possible. It is not part of Camunda BPM out-of-the-box, at least not at this moment. But I saw customers doing some own tooling around ours, leveraging the lean DMN engine itself and dmn.js for the UI part.
A great example is from LV1871, an insurance company in Germany. You can read about it in this blog post, the whole tooling is open source!

Architecture related questions
Q: How do you deal with interfaces between systems within one business process (e.g. order fulfillment) or between multiple business processes (e.g. sales and order fulfillment)?
Architecture wise I would not only look at the business process but at the system boundaries of your microservices. Let’s assume you have the order fulfillment microservices and the checkout microservice (the latter is what I would relate to sales — bare with me if you had other things in mind).
Within one microservice, you have some kind of freedom of choice, it mostly depends on the technologies used. I would consider all of these approaches valid:
- Two Java components calling each other via a simple Java call. You might share the same database transaction. (only within one microservice!)
- Two components calling each other via REST.
- Two components send AMQP messages to each other.
- Two different BPMN workflows call each other via BPMN call activity. (only within one microservice!)
If you cross the boundary of one microservice, you will have different applications that need to be decoupled. So you need to go via a well-defined API, which is most often either REST or Messaging (but could also mean Kafka, gRPC, SOAP or similar). That means you cannot do direct Java calls or use call activities (the italic bullet points above) — both would couple the microservices together too closely in terms of technology.
Q: Can you tell a few pros and cons using microservices vs call-activities?
This is related to the last answer. A call activity makes the assumption, that the called subprocess is also expressed in BPMN and deployed on the same workflow engine. If this is the case, it is a very easy way to invoke that subprocess. You will see the link in monitoring (e.g. Camunda Cockpit) and get further support, for example around canceling parent or child workflows. So if you don’t have any issues with the restriction to run in the same workflow engine, call activities are great. This is typically the case within one microservice.

If you cross the boundary of one microservice, you don’t want to make that assumption. You don’t even want to know if the other microservice uses a workflow engine or not. You simply want to call its public API. So in this case the call activity cannot be used, you use a service task or a send/receive task pair instead.

Q: How do you chain workflows spread across different microservices
This should be partly answered by the last two answers. End-to-end workflows very often cross the boundaries of one service. Let‘s use the end-to-end order fulfillment business process as an example. It is triggered by the checkout service, needs to retrieve payment, fetch goods from the warehouse and so on.
The whole business process happens because of ping-pong of different services. The interesting part is to look at how this ping-pong is happening. And to end up with a manageable system you have to find the right balance between orchestration (one service commands another service to do something) and choreography (services reacting on events):

That means that only parts of the whole business process will be modeled as an executable workflow in a workflow engine. And some parts mind end up in a different workflow engine. And other parts end up hardcoded somewhere. In the above example payment might also have its own workflow:

This is an implementation detail. It is not visible from the outside. You just call the payment API.
You can learn more about that in my talk Complex Event Flows in Distributed Systems.
Q: Could you please send me more information about the differences between events and commands? Is that a different type of contract?
You already learned a bit about that in the last answer:
- Events are facts, it is the information that something has happened. It is always past tense. If you issue an event you should not care about who is picking it up. You simply tell the world: hey — something happened. One important consequence of this thinking is: You should be OK if nobody picks up your event! This is a good litmus test if your event is really an event. If you do care that somebody is doing something with it, it would probably be better a command.
- Commands are messages where you want something to happen. So you send a command to something that you know can act on it. And you expect it to do it. There is no choice. It might be still asynchronous though, so it is not guaranteed that you get an immediate reply.
I talked about that at length in my talk Opportunities and Pitfalls of Event-Driven Utopia (2nd half).
If you need a good metaphor: if you send a Tweet, this is an event. You just tell the world something that you think is interesting. You have no idea what will happen with it, might be that nobody looks at it, but it can also trigger tons of reactions. You simply can’t know in advance. If you want your colleague to do something for you, send them an email. This is a command, as you expect them to do something with it.
Of course you could also switch to synchronous communication and call them, still a command, just blocking and synchronous now. This is another important remark: commands or events are not about communication protocols. Of course it is intuitive to send events via messaging (topics) and do commands via REST calls. But you could also publish events as REST feeds, and you can send commands via messages,
Q: Could you address the issue “sync over async” in a microservice environment? This means, that the process has to be run synchronously until it gets an error. After that it should roll back to the last commit point and give the caller the error message.
This is a super interesting topic. We build architectures more and more based on asynchronous communication. In some situations you still want to return synchronous responses, e.g. when your web UI waits for a REST call.
At least most projects still think they need that. I doubt, that we need it that often, we should better think twice about user experience and frontend technologies. I wrote about it in Leverage the full potential of reactive architectures and design reactive business processes. But let’s do assume that we need that synchronous response.
In this case you have to implement a synchronous facade. In short, this facade waits for a response within a given timeout. For Camunda BPM I did an example with a semaphore once (not the only possibility of course — just an example):
Semaphore newSemaphore = NotifySemaphorAdapter.newSemaphore(traceId); chargeCreditCard(traceId, customerId, amount); boolean finished = newSemaphore.tryAcquire(500, TimeUnit.MILLISECONDS); NotifySemaphorAdapter.removeSemaphore(traceId);
For Camunda Cloud (Zeebe) we even have this functionality build in with awaitable workflow outcomes.
Q: How to handle distributed transactions in an event-driven microservice choreography?
A couple of years back I wrote Saga: How to implement complex business transactions without two-phase commit — which might be a bit outdated, but still gives you the important basics. Or if you prefer you might tune into this talk: Lost in transaction.
TL-DR: You can’t use technical ACID transactions with remote communications, so never between microservices. You need to handle potential inconsistencies on the business level with one of three strategies:
- Ignorance: Sounds silly, but some consistency problems can be ignored. It is important to make a conscious decision about it.
- Apologies: You might not be able to avoid wrong decisions because if inconsistencies, but take measures to recognize and fix that later. This might mean that you need to apologize for the mistake — which might still be better, easier or cheaper than forcing consistency.
- Saga: You do the rollbacks on the business level, for example in your workflows.
Q: Can you give us an example of the saga pattern being used with BPMN?
This continues the answer from the last question. So a Saga is a “long-lived transaction”. One way to implement this is by using BPMN compensation events. The canonical example is this trip booking (I also used in Saga: How to implement complex business transactions without two-phase commit):

Using the order fulfillment example from the webinar, you could also leverage this for payments. Assume you deduct money from the customer’s account first (e.g. vouchers) before charging the credit card. Then you have to roll that back in case the credit card fails:

Q: How to use compensation with microservices?
You could see two examples in the last answer, I hope that helps. There is also sample code available for these examples on my GitHub. More info can also be found in the Camunda docs.
Q: How to correctly use retries?
Please have a look in the documentation, it is not super easy to find (sorry!), but basically, two places might be worth checking: Transactions in Processes (as the foundation) and Failed Jobs for the specific retry configuration.
Q: Does Camunda support restartable and idempotent process?
Yes.
For idempotent start, typical strategies are (quoted from Remote workers and idempotency):
Set the so called businessKey in workflow instances and add a unique constraint on the businessKey field in the Camunda database. This is possible and you don’t loose support when doing it. When starting the same instance twice, the the second instance will not be created due to key violation in this case.
Add some check to a freshly instantiated workflow instance, if there is already another instance running for the same data. Depending on the exact environment this might be very easy — or quite complex to avoid any race condition. An example can be found in the forum.
In Zeebe we built-in some capabilities for idempotent start using unique “message keys”, see A message can be published idempotent.
You can easily restart workflows as you can learn about in the docs. Note that this might conflict with unique business constraints added for idempotency.
Q: I worry that applying automation (analytics) to existing workflows (i.e changing it, instead of automating some parts of an existing workflow) might not correlate to manpower requirements. For example, if all the databases were integrated (linked) based on some arbitrarily decided key — then critical information of (say) a patient connected with an issue referenced in another data set might require a “nurse” to verify the correctness of a record which was not previously required because the innate reasoning of an experienced staffer delivered these “interpretations” successfully — How could “experience” be grafted into the process?
This is quite a lengthy question and hard to answer without further refinement. But a I was consultant for a long time, I answer it anyway :-) I might be way off — then just send me an email and I am happy to refine my answer.
If you separate business logic into independent microservices, you can indeed no longer use database consistency checks (like foreign keys) or query capabilities spanning data from multiple microservices. Let’s use the example given in the question:
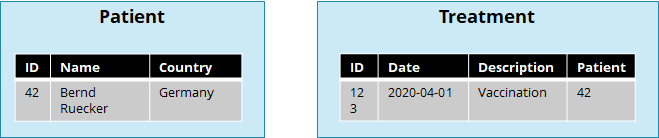
I could insert a treatment, where the patient id is invalid. And I could not easily answer the question, what people in Germany got a vaccination in April.
Both are true. But, this is the intention of the design! You want to probably evolve the treatment microservice independently of the patients. Maybe you will do treatments online in the future, where patients are registered differently. Maybe you have different patient microservices depending on location. Or whatsoever. Hard to discuss without a real use case at hand.
So you have to tackle these requirements on a different level now. First you could think of a specific microservice that is there purely for data analysis and does now data from both microservices. Like a data warehouse or the like. You might use events to keep that in sync.

And second you will probably have workflows that care about consistency. So, for example, you could think of a workflow to register a new treatment:

This could live within the treatment service. Then it might ask the patient service if the patient is registered and valid. Another design could be that the treatment microservice also listens to all events and builds a local cache of patients, so it can validate it locally. And a third design is that there might even be a separate microservice that is responsible for planning treatments, that leverages the other two. Planning a treatment might get more complicated anyway — as you might need to check interactions with treatments in history and much more.
I could go on for ages, but the bottom line: it all depends on how you design the boundaries of your microservices. If you get them right you will not have too many of these problems. If you do them in an unfortunate way, you might get in trouble. Very often microservices boundaries don’t follow the static entities (= tables) as you might think in the first place. There was a good article on that, unfortunately, I don’t find it right now. But probably that’s a good moment for you to google for good boundaries :-)
Q: Do you have microservices to manage areas like complex ordering including package sales, bundling with many pricing options? Or services that could aid in converting product design into the bill of material used for the production line?
Once again these questions need some additional discussion to be clear what is asked. From what I read I would simply say, that it depends (of course ;-)).
You might add logic around package sales and other complex requirements into the order fulfillment microservice. You might also decide that this should be a separate microservice. The important thing is that it matches your organization structure. So if one team should do it all, why not have one microservice? If it is too much for a team it does make sense to split it up.
In the latter case you need to think about the end-to-end business process, so especially about how you can include that special package sales service without hard coding it at many different places. In the example from the webinar I could imagine that the button (=checkout microservice) or some complex package sales microservice emit the order submitted event, and order fulfillment takes it from there. But looking into more details it gets complicated quickly (what’s with payment? What if I can’t send one package? …?).
This is super interesting to discuss, but only make sense in real-life scenarios. I am happy to join such a discussion — ping me!
Stack & technology questions
Q: How could Camunda be used in conjunction with Apache streaming and queuing platform?
The downside of questions via chat is that you simply can’t ask counter questions to understand the exact meaning. So I am not sure what Apache streaming and queuing platform relates to. But if my consulting past teaches me just one thing then that this does not need to stop me from answering ;-)
Let’s assume this platform is what I know as Apache Kafka. Then there are two interesting aspects to look at.
First: There is an overlap of the use case of streaming and workflow, especially when streaming is used to build event-chains between microservices, as I described with the choreography in an earlier answer.
But, there are also good examples of how to use streaming and workflow together. My ah-ha moment was when saw one use case around vehicle maintenance, which I describe in detail in Zeebe loves Kafka: Act on Insights of your Streams:
Assume that you have a huge amount of sensors that constantly send measurements (oil pressure is 80 psi) via Kafka. Now you have some clever logic generating insights based on these measures (oil pressure is critically high). All these insights are also sent via Kafka. But now you want to act on this information, e.g. to alert an operations person to organize some maintenance. In order to do so you have to get from the world of stateless event streams into the world of stateful workflows, from a world of a massive amount of information (the measures might be send every second) to a world with lower numbers, especially as you want to start a workflow only once per insight.

The second interesting aspect is actually about the integration of both tools, which is exactly the next question :-)
Q: Integration with Apache Kafka, best practices?
Integrating a workflow engine with Apache Kafka is technically speaking relatively easy. You need to:
- Ingest records from Kafka into the workflow engine, which is done via message receive events/tasks in BPMN.
- Publish records onto Kafka from the workflow, which is done via message send events/tasks in BPMN (or service tasks if you prefer).

You can find some pieces of code doing this with Java and Camunda BPM e.g. in the flowing-retail example using Spring Boot and Spring Cloud Streams. Or if you use Camunda Cloud (Zeebe) you could also leverage the Kafka connector for Zeebe, as you can see in this example on GitHub.
Q: Integrating with Spring Cloud?
Yes, this is possible. Camunda BPM offers a Spring Boot starter, so it is easy to hook it into the Spring universe including Spring Cloud. There are some examples using e.g. Spring Cloud Streams or also Spring Cloud to run Camunda on Cloud Foundry/PCF.
Q: Do you have any hands-on experience with a heterogeneous Camunda architecture? If yes, do you have any suggestions or best practices?
This question would need to be revised with more details. Almost every customer uses Camunda in a heterogeneous context. I could imagine this question is related to the next two: What if I don’t develop in Java?
Q: You mentioned the benefits of embedded Camunda. In this scenario, what languages or tech stack is Camunda compatible with? We like our microservices written in Go and Node.JS.
The Camunda engine is written in Java. So it is not possible to run it embedded as a library in any other language. Sorry.
BUT: You can use Camunda from other languages. I wrote about that in 2017: Use Camunda as an easy-to-use REST-based orchestration and workflow engine (without touching Java). The main idea is: Camunda provides a REST API which allows you to code in whatever language you like and just talk REST with Camunda:

This works very well for a lot of customers in different worlds, like for example Go, Node.JS, C# and Ruby.
With the upcoming 7.13 release we further improve the experience by introducing two features:
- Camunda Run: A distribution of Camunda BPM that is highly configurable and doesn’t require you to have any Java know-how.
- OpenAPI Support (aka Swagger): This allows you to use the REST API from the programming language of your choice easier, for example by generating a client for it.
Q: Is it OK to use Camunda with a full .NET solution?
Yes, of course. See my answer to the last question, which also applies to .NET. We still do not provide a ready-to-be-used client library as a NuGet package, but we are not that far away anymore. And we plan to improve support for other languages over time anyway.
Camunda product-related questions
Q: What is the difference between Camunda BPM and Zeebe?
Or different forms of asking the same question: How do you position Camunda BPM vs Zeebe in relation to this presentation? Is Camunda BPM still the best/most reliable solution for microservice architecture with orchestration flows? Or is Zeebe the recommended route for such a new project?
To get everybody on the same page first, within Camunda we have two open-source workflow engine projects:
- Camunda BPM: A BPMN workflow engine, that persists state via a relational database. The engine itself is stateless, and if you cluster the engine all nodes meet in the database.
- Zeebe: A BPMN workflow engine, that persists state on its own (kind of event sourcing). Zeebe forms an own distributed system and replicates its state to other nodes using a RAFT protocol. If you want to learn more about if check out Zeebe.io — a horizontally scalable distributed workflow engine.
Camunda BPM is our fully featured BPM platform that covers a wide range of use cases across different industries. Zeebe on the other hand is the engine that powers Camunda Cloud, our managed workflow service (workflow as a service). We have built Zeebe to allow horizontal scaling, to run smoothly in cloud-native environments and to not require any third party dependency like a database. This is great but also harder to operate for many companies that are not yet fully invested in cloud-native architectures. And of course, Zeebe does not yet have all the features of Camunda BPM.
So my recommendation is to use Camunda BPM unless you want to use Camunda Cloud, which then means Zeebe.
I would however try to use External Tasks as much as possible in Camunda BPM. This will set your application up to be architecturally ready for future migrations. One customer for example wanted to leverage the managed services and thus migrated from Camunda BPM to Camunda Cloud — and it was a relatively easy endeavor because of this.
Q: Can we manage a large number of instances?
Yes. But it always depends.
First of all: does this large number of instances waits most of the time? Or does it refer to a large number of requests? Then: What is a large number? 100? 1,000? 1,000,000? Per Day? Per Hour? Per Second?
In our best practice Performance Tuning Camunda we gave some recommendations on how to load test and tune the engine. The only reliable way to give a good answer is to set up a load test that mimics the patterns you will need.
But so far we were able to make every scenario we encountered work :-) A good resource to learn that you can scale quite far is also the 24h Fitness case study.
Q: Is it possible to use Camunda BPM for microservices swarm orchestration and data flow regulation in hi-load systems (25M events per day)? How we can exclude or optimize the DB (as a bottleneck) from the processes?
This relates to the last question but is more precise on the numbers. So doing the math 25M events are approx. 300 events per second. I have no idea about the load distribution, but normally you always need to look at peaks too, so let’s assume 500.
Now I don’t know what these 500 events do within Camunda, but for simplicity, let’s assume they are correlated as messages, so every event leading to one request within Camunda.
In that ballpark it makes sense to have a closer look at performance and I would recommend doing a proper load test. If you have findings it is still possible to tune the engine, e.g. adjust the database indices (if you know what you are doing) or reducing the amount of history data being written.
But I want to repeat myself: so far we were able to make every scenario we encountered work :-) Best talk to us about your concrete use case.
Q: How to design high-performance large volumes business processes? Especially large digital transformation projects specific to 5G business. Currently working on POC for German telco in 5G for BSS stack using Camunda.
This kind of relates to the last question and requires a deeper look into the specific scenario. Please reach out to us to discuss this.
Q: What are the most significant enterprise features of Camunda that enable workflow orchestration which are not present with the community version?
The good news is, that there is no significant feature missing in the community edition, that would stop you from doing microservices orchestration. It is important for us, that our community edition is usable in real-life scenarios!
That’s said, of course, we need to provide enough motivation to go for the enterprise edition to pay everybody’s salary. This is mostly about all the additional tooling you need if you apply Camunda in bigger and mission-critical scenarios: features in the operations tool around diving into historic data, fixing problems at scale, migrating versions and so on. And Camunda Optimize as the analytic tool is also enterprise only.
On top of that, of course you get support, more access to our consulting services, additional warranties and further patches for old versions.
You can find a comparison table here.
Camunda Optimize specific questions
Q: Is Camunda Optimize Event-Mapping/Ingestion available now? Open-source or as a product? Are there any plans in the future to provide a community edition of Optimize?
Process events monitoring was released with Optimize 3 and is already available today.
There is no community edition available of Camunda Optimize and there are no plans to provide one. Optimize for us is an important up-selling feature as discussed in the last question.
That’s said there is a free trial version available and I could imagine, we will also have ways to easily leverage Camunda Optimize in Camunda Cloud soon (maybe even a free tier? But nothing I can promise !).
Q: In the Optimize demo, you created a process and mapped it to the Kafka events. Did you deploy it to a Camunda engine which provided Camunda history events to Optimize? If so, is that Camunda engine part of Optimize?
No, Camunda Optimize just needs Elasticsearch as a data store. It does not need any workflow engine to do process events monitoring.
Q: Maybe instead of calling it “Process Discovery”, how about the buzzword-compliant “Process Mining”?
Let’s quote Wikipedia:
Process mining is a family of techniques in the field of process management that support the analysis of business processes based on event logs. During process mining, specialized data mining algorithms are applied to event log data in order to identify trends, patterns and details contained in event logs recorded by an information system.
Process discovery is one of these techniques, which can derive a process model from all the events you ingest. And this is what I talked about in the webinar: We want to add process discovery to the product (and we already had a working prototype).
Additionally, I would not (yet) call Optimize a fully-fledged process mining tool — but I know that I am often too honest for this world and some other vendors don’t care about exact category boundaries too much ;-)
Questions about best practices
Q: Business data versus workflow data: if you cannot tear them apart, how can you keep them consistent? Are the eventual/transactional consistency problems simpler or more complex with Camunda BPM in the equation?
This is quite a complex question, as it depends on the exact architecture and technology you want to use.
Example 1: You use Camunda embedded as a library, probably using the Spring Boot starter. In this case, your business data could live in the same database as the workflow context. In this case you can join one ACID transaction and everything will be strongly consistent.
Example 2: You leverage Camunda Cloud and code your service in Node.JS, storing data in some database. Now you have no shared transaction. No you start living in the eventual consistent world, and need to rely on “at-least-once” semantics. This is not a problem per se, but at least requires some thinking about the situations that can arise. I should probably write an own piece about that, but I had used this picture in the past to explain the problem (and this very basic blog post might help also):

So you can end up with money charged on the credit card, but the workflow not knowing about it. But in this case you leverage the retry capabilities and will be fine soon (=eventually).
Q: Is it a good idea to save the process data into a single complex object with JSON notation?
As always: It depends.
But if the data cannot live anywhere else, serializing the data into the workflow is at least an option. And if you serialize it, JSON might also be a good idea. Please note, that you cannot query for data in that process variable any more (or do a text query at max).
So it depends. The best practice Handling Data in Processes might help to judge that.
Q: How to handle the filtering of information allowed or not to be seen by a user of the process?
I guess this refers to task lists. There are two layers to look at it. Is it important that the user is not able to get the data at all — not even by looking at the data transferred to his browser via JSON in the background?
If yes, you need to work with data mappings to make sure only the variables are available in the task that should be readable and configure permissions accordingly.
If no, the easiest option is to simply not show certain data in the forms for users.
Q: How to do microservice versioning and workflow versioning and manage both in harmony and congruent?
I love this question, but it depends. Versioning Process Definitions might give you a good starting point for the workflow angle of it.
For the microservices angle of it there are tons of other material available discussing tolerant readers and overall versioning approaches. This is a rabbit hole I don’t want to follow here.
Q: What are the best practices for handling version changes when dealing with a BPMN that changes key pieces of its workflow microservices?
This seems to be similar to the last two questions.
Questions around project layout, journey and value proposition
Q: Where is the best place to start when moving from old legacy monolith workflow systems to Camunda so there is minimum disruption.
It depends on so many things. The How to migrate to Camunda whitepaper Can give you some first guidance.
Q: How to convince monolith customers with legacy to move to microservices?
You need to find the current pain points and show how microservices can provide a cure. Companies need to understand the real benefits. You should not apply microservices just because it is hip.
The major benefit is around business agility. Microservices are small, autonomous services that do one small thing very well — and then need to work together. The less they need to communicate to anyone else the more efficient they can work and the more agile they can be when any change is needed. My favorite quote around that is from Jeff Bezos:

And the metaphor I always use is a three-legged race. If you tie together different teams, so that they need each other to change or deploy anything, you make them all slower. If you cut the bonds, every team can run faster.

Of course, this leaves you with the challenge of how these services collaborate — that’s why you inevitably also will stumble over workflows :-)
I searched a bit but did not find a recording where I go exactly over this storyline, probably The Role of Workflows in Microservices gives you at least a glimpse of how I think about that.
Q: What are the advantages of using Camunda for microservices orchestration?
Following up on the last answer I am convinced, that you need orchestration capabilities in your microservices architecture. I discussed this in this webinar, but also for example in Complex event flows in distributed systems.
The second part of this question then is: Why to use Camunda instead of any other workflow tool. While I might be a bit biased on this, I am convinced that Camunda has the strongest offering in that space because of the following characteristics:
- Developer-friendly: No fluff & unrealistic low-code promises, but a great integration into the developers’ world, including tooling and procedures.
- Highly-scalable: Camunda can back small workflow applications as well as global, mission-critical core business processes. And we help the Nasa to get to Mars :-)
- BPMN/DMN standards-based: We are completely based on well-known and widely adopted standards, that are not only directly executable but also provide visual diagrams, that non-it folk can understand, which brings us to:
- Business-IT-collaborative (see also BizDevOps — the true value proposition of workflow engines).
Wrap-Up
I am sorry for the long post. But it was a huge list of questions and I had quite a lot of fun to answer them. I hope that was helpful. And: You are brave if you made it till here — kudos!
Bernd Ruecker is co-founder and chief technologist of Camunda. He likes speaking about himself in the third-person. He is passionate about developer-friendly workflow automation technology. Connect via LinkedIn or follow him on Twitter. As always, he loves getting your feedback. Comment below or send him an email.

Top comments (0)