(This post was written as part of an assignment for the Computer Science Career Path from Codecademy.com)
Background
For the past few months, I have been working through various resources to help me transition into a career in software development. Of course, as part of this learning, I have written small programs here and there, along with a couple larger portfolio projects. I made a post about my first portfolio project, and now it's time once again to share with the class. The task for this project was to create a recommendation software for a topic of my choice.
Brainstorming
I'll be the first to admit that brainstorming topics is not my strong suit. When given the choice, I would much prefer to figure out how to implement an existing idea, rather than to think up the idea myself. I knew that I needed to choose a topic that I could easily break into various categories, otherwise I'd probably constantly feel the need to restart from the ground up.
I decided that a good way to think of something might be to try thinking of times where I am most indecisive and would most appreciate a good recommendation. For me, this definitely meant finding some kind of media to consume. I don't know why, but for some reason, whenever I have the chance to relax and find something enjoyable to watch/listen to, I can never think of anything. I usually have to leave it up to various websites' recommendations for new content to consume. I think I've found my topic!
The Project
(Follow along on GitHub!)
All right, so we're going to make a recommendation system for media, but what does that actually mean? What kind of media should I focus on? What kinds of things can you ask the user to narrow down their options? How is that going to boil down to a concise recommendation for the user? In order to start my project, I needed to have answers to these questions.
My plan for the user interaction was simple:
- User is bored.
- User uses recommendation software.
- User gets ideas for media to consume.
This means that I needed to have some kind of collection of different forms of media; I settled on including movies, tv shows, video games, and songs.
I also needed to figure out different ways to group these different forms of media. To do this, I needed to look at characteristics of the media that are not super apparent at face value: release date, genre(s), and length (movies in minutes, tv shows in # of episodes, games in hours, and songs in seconds). Some planning and trail-and-error later, and I had a working prototype: users would be greeted with welcome message and an introductory selection to start the process of narrowing down the media.
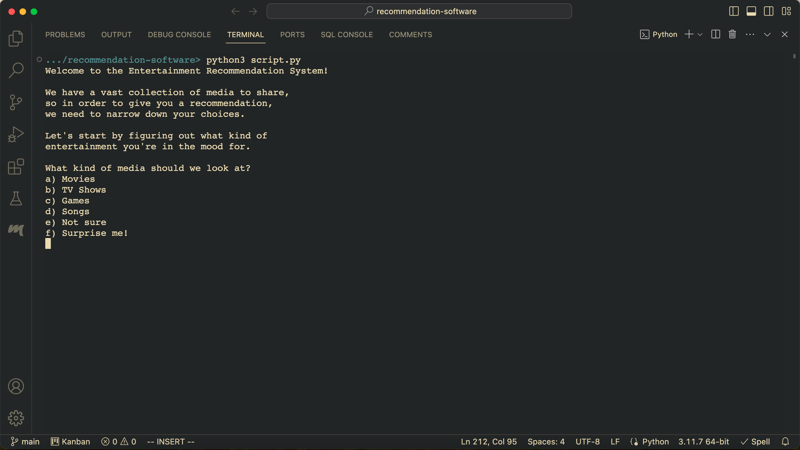
The basic roadmap of all of the paths is roughly the same. The user starts by selecting a form of media that they want to focus on. If the user doesn't know which type of media they want (they are here to get entertainment recommendations, after all), they have two additional options: "Not sure" and "Surprise me!". The latter simply chooses one of the media types at random, then proceeds as if the user had entered it. The former, however, begins a unique path, which returns the most extensive collection of media.
In step two, no matter what they chose previously, the user will start to narrow down their options by selecting their favorite metric. This time, they do not have an "unsure" choice, but they still get the option to have the program choose one for them at random. There is one more question for the user, which will look slightly (or very) different depending on which metric they chose.
Essentially, I need the user to split the metric somehow. For length and release date, this meant selecting from their extremities (shortest/longest, oldest/newest), and for genre this meant selecting a single genre, which the program could then use to select media based on related genres. No matter what the user chose previously, once they get through this step, the entire collection of media is filtered by the given metrics.
At this point, we have a filtered collection of our entire selection of media based on the user's metric choice. Now we need to decide which media to return to them. Luckily, they already told us what they wanted at the beginning! The user will end up with the filtered collection of whichever media type they chose. In the case that they chose the "unsure" option at the beginning, they would receive a filtered collection from all of the media types.
What Could Be Improved?
A lot. But I had to keep my expectations realistic. This was one project from one course I was working through. As I mentioned, I am currently trying to transition my career into software development. While this project was an important portfolio project for this one course, I see it as more of a practice portfolio project in my overall journey to jump careers. With that out of the way, let's get into the areas that I feel could be improved had I given them a bit more attention.
Standardization
I gathered most of the information surrounding the media simply by searching around for manually. Therefore, there is bound to be some inconsistency, whether due to input errors when entering the information or simply due to subjectivity. For example, classifying media by genre can be done to a certain extent objectively, but when you start doing so across multiple media forms, sometimes the difference between genres like "action" and "action-adventure" becomes less clear. To mitigate some of the complexity caused by this, wherever possible, these situations were simplified (so the two genres from the example would both be classified as "action-adventure", even if that's not technically what they both are).
Storage
I couldn't even tell you what data structure the media is stored in (okay maybe that isn't true, but it's still not super well designed, which is more important). Technically, they're stored in Python dictionaries, but the different forms of media are stored in different dictionary variables. To keep track of those, the dictionaries they're stored in are themselves stored in a list... but not in the same file as the media. While this is kind of nice for easy access in the utility algorithms, I'm willing to bet it hurts efficiency when the program actually has to do anything with the collections. In my defense, this project falls before any database lessons in the Codecademy course it's from, so I think I did a pretty okay job without needing to jump a full unit ahead.
Algorithms
Speaking of utility algorithms, these are probably the weakest area of the program. They aren't bad, but I'd be lying if I said I gave them the amount of consideration that they should get, for how big of an impact they have on the end performance. The algorithms relating to the genres are especially inefficient, as they tend to iterate over the collections several times even in the span of a few lines of code (nested loops, nested higher-order-functions, etc.). This isn't actually too bad of a cost in the current iteration of the project, but that is mainly because the collection of media is tiny compared to a production level program. I haven't tested it, but I have a funny feeling this current program wouldn't scale very well...
Filtering
Right now, the program can only filter the media based on the endpoints of the metrics. If you choose a movie by older release date, you will only ever get a group of the oldest three movies in the collection. While there are enough different combinations of metrics and media for this not to be a huge deal for this smaller sized sample program, eventually it might be smart to let users choose somewhere in the middle.
But what about choosing by genre? I was hoping you wouldn't ask... This is the section of the code that basically works, but just barely. On the bright side, this means that there is plenty for me to still improve on. So, what's wrong with it? Nothing, per se (like I said, it does work). It's just embarrassingly messy and horribly inefficient. I mean, it calculates related media for all of the media types, regardless of if you chose a single media type or told the program you were unsure. Of each of those five individual branches (each media type, plus the unsure option), four of them will discard 75% of the calculated related media. In other words:
- You always calculate 12 pieces of related media (assuming there are actually 12 related pieces of media that exist).
- Of the five possible paths to continue from, only one of them returns all 12 pieces of media.
- The other four paths return 3 pieces of media and discard the other 9.
But wait, doesn't it do that for the other metrics as well? Yes, it does! However, those metrics are single pieces of data, whereas the genres are stored in lists. There's at least an entire extra layer of iteration involved when we're working with them over the other metrics, so it's more expensive to get to this point.
See why I didn't want to mention it? This is one of those times where I had to stay realistic. Even getting this section to work the way I wanted was a bit of an ordeal (you'd be surprised what weird results you get when overlapping genres and media types; like including "fps" as one of the genres for Portal 2, or "animated" for Attack on Titan leads to a super interesting list of media deemed "kid-friendly" 😅). Because this took so long to get working in the first place, it was one area that I knew would take up all my time if I didn't let it go.
Verdict
So, what's my verdict on this project? It's a whole lot better than the one in my first post, that's for sure. I know it isn't perfect, but for where I am in my learning, for how much better the end result is than my first portfolio project, and for the amount of time the whole thing took (including writing this post), I'm pretty happy with it. And hey, at least I have some clear objectives for what can be improved in my next projects. Not too shabby for a self-taught former music teacher, if I may say so myself.





Top comments (0)