
In the previous article, I introduced FuzzyWuzzy library which calculates a 0–100 matching score for a pair of strings. The different FuzzyWuzzy functions enable us to choose the one that would most accurately fit our needs.
However, conducting a successful project is much more than just calculating scores. We need to clean the data before we start working on it, choose the best method to calculate our scores, learn how to work not only with a pair of strings but with tables of data, and eventually know how to use the scores we received to make the most out of our results.
So, without further ado, let’s dive into some best practices we should be familiar with.
Using a Table With Pandas In order To Compare Multiple Strings
As discussed earlier, FuzzyWuzzy functions calculate matching scores for two strings. But when working with “real life” data, we will probably want to compare at least two sets of strings. This means working with a table, or when speaking in Pandas terms — working with DataFrames.
A good table will resemble this one:

The table above contains two comparison columns, each with a relevant header, where the strings to be compared are in parallel rows.
Given such a dataset, we can read the table to a DataFrame using a relevant function. The example below reads directly from a CSV, but if you are interested in using other formats — you can check out the following documentation.
>>> my_data_frame = pd.read_csv("my_folder/my_file_name.csv")
Data Preprocessing — Cleaning the Data Before Analysis
Before we choose our FuzzyWuzzy function and start comparing strings, we want to clean the data to ensure that our results will be as accurate as possible.
Cleaning the data means removing irrelevant strings, and thus improving the functions’ performance.
For example, let’s assume we compare strings of two addresses, where one address is “Joe Boulevard” and the other is “Jule Boulevard”. The matching score will be relatively high, but mostly due to the existence of “Boulevard” in both strings. Removing it and recalculating will result in a much lower matching score:
>>> fuzz.ratio(“Joe Boulevard”, “Jule Boulevard”)
89
>>> fuzz.ratio(“Joe”, “Jule”)
57
The type of cleaning required for your data depends on your domain.
We saw an example of the required cleaning for addresses. Similarly, when comparing phone numbers — we will probably want to remove parentheses and dashes that have no added value. It is also recommended to normalize all of your strings to lowercase since some FuzzyWuzzy functions treat differently-capitalized letters as different strings.
So, look at your data, and decide what should be modified in order to make it clean and ready for processing.
Data Pre-Processing — Let’s Get Technical
Now, let’s define a function with the relevant logic, and iteratively run it on each of the relevant columns in the DataFrame.
** The example below was simplified in order to keep the explanation clear. For best results, it is recommended to use regular expressions (regex) which is beyond the scope of this article. Note that strings_to_remove, in its current form, may lead to imperfect results after the cleanup.
>>> strings_to_remove = [' ave ', ' ave. ', 'avenue', ' lane ', ' ln', 'blvd', 'boulevard', ' rd. ', 'road', 'street', ' st. ', 'str ', ' dr. ', 'drive', ' apt ', 'apartment', 'valley', 'city', '.', ',']
>>> comparison_table =
comparison_table.astype(str).apply(lambda x: x.str.lower())>>> for current_string in strings_to_remove:
comparison_table = comparison_table.astype(str).apply(
lambda x: x.str.replace(current_string, ' '))
>>> comparison_table = comparison_table.astype(str).apply(
lambda x: x.str.replace(' +', ' '))
And — voilà!

Adding a Score Column And Comparing
All that’s left now is to add an empty column named ‘score’ to the DataFrame, calculating the matching scores using our chosen FuzzyWuzzy function,
and populating the DataFrame with those scores.
Here is an example of how to do that -
>>> comparison_table["score"] = "">>> comparison_table['score'] =
comparison_table.apply(lambda row:
fuzz.token_set_ratio(row['col_a_addresses'], row['col_b_addresses']),axis=1)
Let’s compare the results with those we would have received if we had run the FuzzyWuzzy function on an unprocessed DataFrame:
Before Cleaning -

After Cleaning -
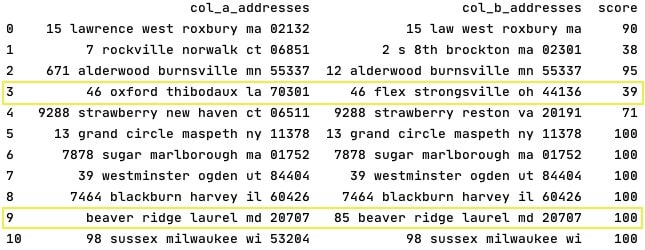
So, what actually happened after cleaning the data?
The matching scores became more accurate — either increased or decreased based on the cleaning.
- Let’s look at row 3 where the score decreased after cleaning. In this case — the word “Lane” which appeared on both addresses before cleaning, falsely increased the matching score. But after removing it, we were able to see the addresses are not that similar.
- Let’s look at row 9 where the score increased after cleaning. While “Lane” and “ln.” have the same meaning, they are different strings with different capitalization. Once cleaning the noise out — we were able to receive a much better score, that more accurately reflects the similarity level between those strings.
- It is also interesting to see that the cleaned strings in row 9 are not identical. ”85" appears only in col_b_addresses yet the matching score is 100. Why? Since the strings are “close enough” to be determined as a perfect match by the algorithm. A decision that would have likely been the same if a human being had to make it.
Choosing a FuzzyWuzzy Function — In a Nutshell
One method to choose the best FuzzyWuzzy function to work with is based on the logic/purpose of the different functions and determining which function seems most relevant for your purposes.
However, if you cannot decide which function may retrieve the most accurate results — you can conduct a small research to determine what to work with.
The method I would recommend using would be to take a sample of your data set and run each of the relevant functions against it. Then, for each of the results — manually decide if the value in each row is true positive / false positive / true negative / false negative.
Once this is done, you can either choose where your TP/FP rate is most satisfactory, or go ahead and calculate accuracy* and sensitivity* as well, and use these values to make your decision.
For each project, our goals may differ, and the false positive / true negative rates we are willing to take will be different.
* Both accuracy and sensitivity are used in Data-Science and beyond the scope of this article. The formulas for each of these can be found online.
Choosing A Threshold Score — In a Nutshell
My pair of strings returned a matching score of 82. Is it good? Is it bad?
The answer depends on our target, and there are many relevant questions to ask, such as: are we interested in strings that are very similar to one another, or in different ones? What is the maximal false-positive rate we are willing to accept? What is the minimal true-positive rate we want to work with?
For the same set of strings, we can come up with two different threshold scores — minimal score for similar strings (for example 85), and maximal score for different strings (for example 72).
There can be a whole range between these threshold scores that will be doomed as “inconclusive”.
There are different methods to define a threshold score, and we won’t dig into them in this article. I will, however, mention that choosing a threshold score will require some manual work, similar to the one mentioned above regarding how to choose the best FuzzyWuzzy function to work with — taking a sample set of strings with final scores, determining true-positive and false-positive for the results, and eventually deciding where our threshold stands.
Using FuzzyWuzzy for strings comparison, as well as pre-processing the data, and eventually analyzing the results is a fascinating work. There is always more to do, and different ways to improve the process.
In this article, we explored some of the practices that make this process useful and comfortable.
If you enjoyed this article, and/or the previous one, let me know! Share in the comments below a takeaway note for your next project.
I’d love to hear from you :)

Top comments (0)