
This is going to be one of the series of posts related to Interview topics that I would be writing. In this post, we are going to explore hashmap. I couldn't remember any interview without Hashmap being involved.
So what is Hashmap?
In Simple terms, Hashmap stores data in key-value format.
Let's take an example of key-value pairs
myCloset={
"RoundNeckTShirts":5,
"VNeckTShirts":3,
"NightPyjamas":5,
"Trousers"5
}
Each and every value inside the object will be stored as a key-value in the form of an array, but how to identify which pairs are stored in which array index?
That is where Hash functions come into the picture
Hash Functions uses the key to calculates the index in which the key-value pair needs to be stored. Various programming language uses a different hash function to calculate the array index. Let's take the below example for instance
Imagine you have a chest of drawers and you want to arrange your kid's clothes in it category wise(as shown in cover pic), For eg, if its a Nightdress, it should go into the Pajamas drawer, if its a V Neck Top, it should go into T-Shirts drawer, etc
Similarly, the hash function helps identify the array index (drawer in this example) where the key-value pair(clothes in this instance) needs to be stored.
Hence regardless of the number of inputs to be stored, big O notation for insert will always be o(1) because the amount of work and the time required to perform the operation(Identify hash -> Identify index position -> Store the value ) doesn't change based on the volume of data
Hash Collision
Obviously, you will have more than one set of clothes under one category(in this example) like below which is quite possible but it should be avoided. This is termed as Hash Collision

During data insertion, If more than one data returns the same value from a hash function then hash collision happens and the data is stored in the same bucket with reference to one another
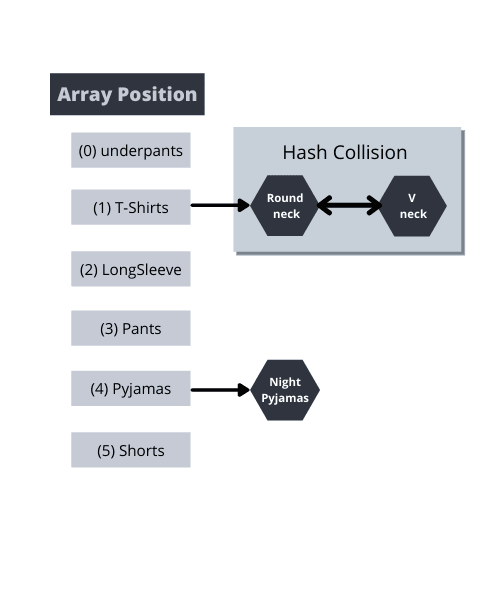
During data retrieval, if there are multiple nodes present in each bucket, then each of them is compared against the target value to retrieve the data from the bucket. Hence the best case(if there are no collisions) Big O would be o(1) and worst-case ( if there are multiple collisions and more data are stored in the same bucket) then each item will be compared against the target from the top to bottom until an element is found which might lead to o(n) - depending on the number of elements
Load Factor
The Initial capacity of buckets in this example is 5(number of chest drawers), Load factor is the measurement of how much the buckets can be filled before additional capacity is increased. This factor differs for different programming languages. In Java, it is 0.75f with an initial capacity of 16 buckets hence 0.75*16= 12. After storing 12 keys, an additional 16 buckets will be added to the capacity.
So overall HashMap/Table is one of the most efficient data structures, it becomes worse if there are more collisions. Below Big O cheatsheet can be found here

Here is a link where you can visualize the manipulation in the hashmap
This will be one among the series of posts that I would be writing which are essential for interviews. So if you find are interested in this thread and found it useful, please follow me at my website or dev





Top comments (1)
Great post