
On Mechanisms

Once again, I’d like to express my gratitude to Peter Vosshall, Former Distinguished Engineer at AWS, for the inspiration behind this series of posts. I’d also like to thank my colleagues and friends Olga Hall and Matt Fitzgerald for their valuable feedback.

It takes three interconnecting elements to operate the technology we build successfully. First, you need to have the right culture. Second, you need great tools. And third, you need complete processes.
Part 1 of the series covered the cultural side of Operational Excellence (OE) and examined Amazon’s culture in the context of its Leadership Principles (LPs). Part 2 discussed the role that tools play in achieving OE. Part 3 will cover the final aspect to operational excellence — processes — or what we call mechanisms.
To help you understand the importance of processes, I wanted to share one of my favorite stories from Jeff Bezos, the CEO of Amazon. It starts with our customer connection training.
Customer connection training is available to every Amazonian. It was put in place to support Amazon’s mission to be Earth’s Most Customer-Centric Company and to help Amazonians make better connections between their work, the customer experience, and customer support resources. It’s one of the ways we continuously train people to put the customer at the heart of every decision we make.
The story goes as follows.
Several years ago, Jeff Bezos took part in customer connection training, and together with a very experienced customer-service (CS) representative, he took a phone call from a customer to respond to a complaint.
As soon as the CS representative pulled up the list of orders from that customer, she looked at Jeff and whispered that the customer was probably going to be returning one particular item on the list — a table — and added that the table in question was going to be damaged.
As you can imagine, Jeff was a little baffled by this prediction.
And indeed, the customer explained that she wanted to return the table because it was damaged.
After the phone call, Jeff asked the CS representative how she knew in advance that the table was going to be damaged. She answered:
“Oh! Those tables always come back, and they’re always damaged. They’re not packaged right, so the surface of the table always gets scratched.”
Jeff scratched his head, wondering how something so easy to avoid was happening.
After the training, like any CEO wanting to solve a problem, Jeff turned to the customer service leadership team. He asked them to do a better job and to make sure that the feedback loop between the customer service and retail department was closed.
Can you guess what happened?
Well, nothing happened.
Nothing happened because Jeff was asking for good intentions.
And to give you an example of a good intention, think about the following. Do you wake up in the morning, go to work and tell yourself:
“Today, I’m going to do a terrible job!”
I thought so. Most of us want to do well. We have good intentions. And so did everyone in the customer service department.
So, if good intentions don’t work, what works?
The answer is mechanisms.
Mechanisms are a lot better at fixing recurring problems than good intentions.
And there’s a happy ending to the scratched table story. But first, we have to go back to 1902, to a company called Toyota.
Once upon a time at Toyota

If you are wondering what a silk weaving loom has to do with a Toyota, it’s because the company we know for making cars today started life as a silk weaving company. Toyota operated silk weaving looms, similar to the one above. At that time, Toyota made silk for geishas, and geishas wouldn’t accept silk that had flaws.

So, in 1902, Toyota-san, the founder of Toyota, invented a small mechanism on the loom that would immediately stop the loom and reject the clothes if any of the tiny silk threads broke.
That little idea started an essential, powerful, yet simple philosophy:
Toyota will not allow any defect that they know about to go down the manufacturing line.
Of course, if you think about that for a second, it sounds more like an act of faith than a philosophy. But rather than computing the probability associated with product flaws and if they were worth fixing, Toyota simply decided not to let any defect that they found or knew about, go down the manufacturing line, regardless of the cost associated with it.
The Andon Cord
Toyota has had, for a long time now, cords along the assembly line that anyone can pull. Pull the cord, and it stops the production line (red arrow in the picture below).

Those cords — called Andon Cords — are often mistakenly identified as safety equipment. However, at Toyota, they’re a way to prevent any defect, no matter how small, from moving down the manufacturing line.
Any employee at Toyota is fully empowered — and expected — to pull the cord if they see or become aware of any defect. Immediately after the Andon Cord is pulled, a team leader will personally “go see” the issue at the problematic workstation and thank the operator for stopping a defect from going down the manufacturing line.
The Andon Cord approach, when first discovered by western manufacturing companies, was horrifying. Letting anyone on the factory floor decide to stop a multi-million dollar manufacturing line is not the kind of freedom senior executives like to give away.
Yet, that’s a real mechanism — empowering everyone in the company to stop defects and fix them before they reach customers.
The critical part here is the association of a tool, the Andon Cord, with a particular behavior and the specific culture.
To learn more about Toyota, the Andon Cord, and other specific tools and behaviors associated with its success, I strongly recommend reading “Toyota Kata” by Mike Rother.
Back to the scratched table story…
Amazon took that simple, but powerful idea and built the Andon customer service , a tool that lets any customer service representative “stop the line,” which means removing any product on the Amazon retail website in minutes until the defect gets fixed.
It’s still up and running today and has been very successful.
Following is an example of the Andon Cord at work — and the item is now under review because the Andon Cord has been pulled.
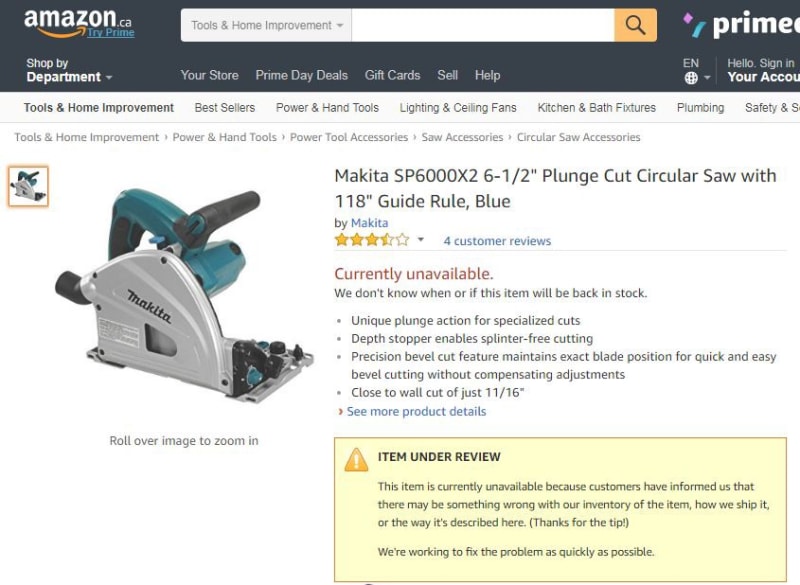
Amazon has built multiple versions of the Andon process — here is one preemptively doing a refund to our customers. Jeff Bezos shared it in his 2012 Shareholder Letter.

Here’s the important part:
“We noticed that you experienced poor video playback while watching the following rental on Amazon Video On Demand: Casablanca. We’re sorry for the inconvenience and have issued you a refund for the following amount: $2.99. We hope to see you again soon.”
Here is another shared online by a customer:

The Andon automatic refund program was implemented to address and maintain customer trust when digital video delivery is below our standards. The plan was built based on the Customer Obsession leadership principle.
Customer Obsession
Leaders start with the customer and work backward. They work vigorously to earn and keep customer trust. Although leaders pay attention to competitors, they obsess over customers.
The idea behind that program was not to drive purchase behavior but to address customer satisfaction, and today the program continues to receive positive unsolicited feedback in customer forums and the press.
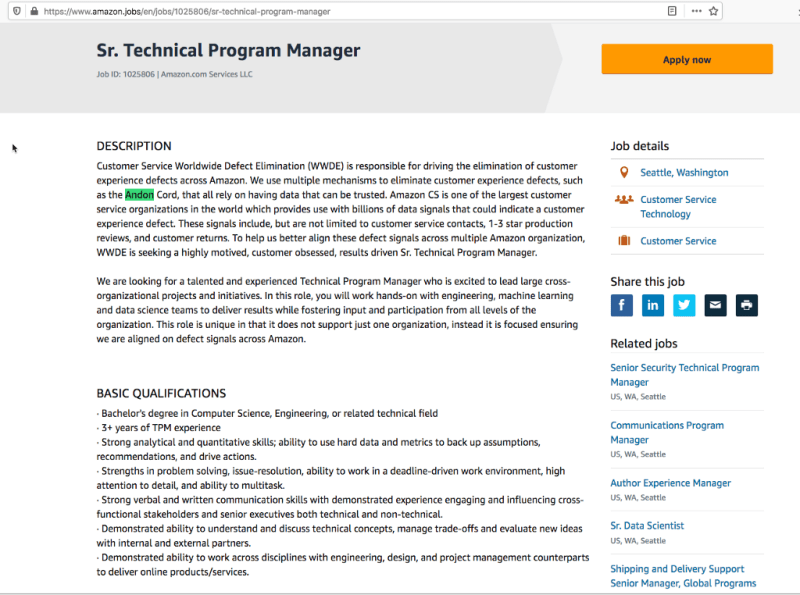
And we are hiring folks to further improve the Andon Cord program — hint ;)
Similar programs are also common within AWS, and you can see the effect of the Andon Cord every time AWS reduces prices, maintaining the Flywheel in motion (more about that below).
So, if you see yourself frustrated by a recurrent problem and catch yourself asking people to try harder, remember that you’re asking people for good intentions and that rarely does anyone want to do wrong.
Then, remind yourself that good intentions already exist, and that means you aren’t asking for a change.
“Good intentions never work; you need good mechanisms to make anything happen.” — Jeff Bezos
About mechanisms
A mechanism, or complete process, is made up of three steps: tools, adoption, and auditing.
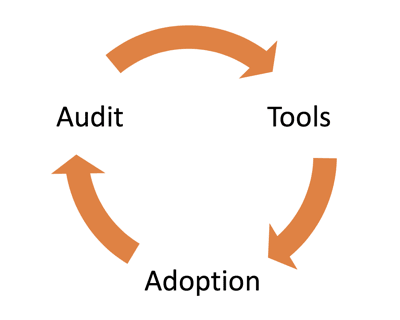
Imagine for a second that you build a tool. That tool is useless if you don’t have a training program and a way to drive its adoption. It’s also essential that you have some kind of continuous audit mechanism that ensures the tool is operating as designed.
Correction-of-Errors
Coming back to operational excellence, one mechanism that Amazon developed over time is the Correction-of-Errors (COE). It’s a process where a team reflects on a problem — maybe an unexpected loss of redundancy, or perhaps a failed software deployment — and documents what the problem was and how to avoid it in the future.
We use this mechanism to learn from our mistakes, whether they’re flaws in tools, processes, or the organization.
We use the COE mechanism to identify contributing factors to failures and, more importantly, drive continuous improvement.
It’s not a new process for Amazon — I’ve seen COEs from 1999 — but it’s become more productive over the years.
There are five main sections in a COE document.
1 — What happened?
2 — What data do you have to support your analysis?
3 — What was the impact on the customers?
4 — What are the contributing factors?
5 — What did you learn, and how will you prevent it from happening again in the future?
To learn more about our COE process, please check out my favorite re:Invent 2019 talk from Becky Weiss, a senior principal engineer at AWS.
Let me touch on two leadership principles that help Amazonians during a COE process:
Earn trust
Leaders listen attentively, speak candidly, and treat others respectfully. They are vocally self-critical, even when doing so is awkward or embarrassing. Leaders do not believe their or their team’s body odor smells of perfume. They benchmark themselves and their teams against the best.
Dive Deep
Leaders operate at all levels, stay connected to the details, audit frequently, and are skeptical when metrics and anecdotes differ. No task is beneath them.
The key to being successful during a COE is to be open and transparent about what went wrong. That means you have to listen carefully but also be vocally self-critical and dive deep on the issues at hand. It’s key to the COE process and operational excellence in general, and it can be quite hard in an environment that doesn’t embrace and encourage such behavior.
To make the COE mechanism a complete process, we have a continuous inspection in the form of weekly operational metrics review meetings where individual teams hold metrics reviews in front of senior leadership.
Spin the wheel
All service teams are expected to be “ready” to present their operational metrics if called upon; this ensures that everyone has their finger on the pulse and intimately knows how their services are performing. The team selected to present is chosen at random, using a wheel.

When selected, service owners present a 15 minute deep dive on their service metrics. Typical questions during the review include:
“ What are your error rates?”
“Are you monitoring enough?”
“What lessons have you learned?”
Learnings are often applied across teams, and many are added to the AWS Well-Architected framework that is made available to our customers in the form of white papers and a tool accessible from the AWS Console.
Continuous improvement
With the COE process and weekly operational metrics in place, you’d think we’ve ruled out good intentions.
Wrong.
With the COE and the weekly reviews in place, you’d expect that problems found by one team would be immediately picked up by others and proactively fixed.
But again, that’s asking for good intentions!
We needed another mechanism: a mechanism to enforce continuous improvement.
So, instead of asking for good intentions, we built a new tool: Policy Engine.
Policy Engine scans the infrastructure and its configurations to determine the risks and cost-savings opportunities. Policies are created from problems identified during the COE process — issues that can be codified. The tool is easily extensible, so when new problems are identified, new policies are created and added to the tool for everyone to use.
Most importantly, the Policy Engine dashboard presents a holistic view of how teams are performing in terms of identified risks and saving opportunities. That helps the organization continuously improve services and operate as cost-effectively as possible, again, maintaining the Flywheel in motion.
Take away
These mechanisms at Amazon have inspired the development of some of my favorite AWS services: AWS Config, AWS Trusted Advisor and the Well-Architected tool.
AWS Config enables you to assess , audit , and evaluate the configurations of your AWS resources. It lets you continuously monitor and record your resource configurations so you can check for configuration drifts. It also simplifies compliance auditing, security analysis, change management, and operational troubleshooting.
AWS Trusted Advisor gives you real-time guidance against AWS best practices. Business and Enterprise Support customers can access the full set of Trusted Advisor checks and recommendations to help optimize their infrastructure, increase security and performance, reduce costs, and monitor service limits.
Finally, the AWS Well-Architected Tool helps customers review their workloads and provides guidance following AWS best practices. It’s based on the AWS Well-Architected framework, developed to help customers build secure, high-performing, reliable, and cost-effective applications on AWS, designed from tens of thousands of workload reviews conducted by the AWS solutions architecture team.
Epilogue
To conclude this series of posts, remember that it takes three interconnecting elements to operate the technology we build successfully. First, you need to have an operationally focused culture. Second, you need a rich set of tools. And third, you need the right supporting processes.

Finally, don’t forget that good intentions don’t work — mechanisms do.
That’s all for now, folks. I hope you’ve enjoyed this series of posts. Please don’t hesitate to share your feedback and opinions. Thanks a lot for reading :-)
-Adrian





{kind=link}
Top comments (0)