
Hello world. This is the monthly AWS Natural Language Processing(NLP) newsletter covering everything related to NLP at AWS. Feel free to leave comments & share it on your social network.
Joint AWS / Hugging Face Workshop

There was a recent joint AWS/Hugging Face Workshop, now available on YouTube on how to ‘Accelerate BERT Inference with Knowledge Distillation & AWS Inferentia’
The workshop takes you through applying knowledge distillation to compress a large model to a small model, and then from the small model to an optimized neuron model ready to run on AWS Inferentia. The combination of reducing the model size and the Inference improvements from Inferentia custom silicon yielded a reduction of latency from 100ms+ to 5ms+ - a 20x improvement!
The workshop covered:
- Applying knowledge-distillation with BERT-large as teacher and MiniLM as student
- Compiling Hugging Face Transformer model with AWS Neuron for AWS Inferentia
- Deploying the distilled & optimized model to Amazon SageMaker for production-grade fast inference
There is a great set of presentations and tutorials On the Hugging Face YouTube channel well worth digging into the back catalogue and subscribing for new videos.
NLP Customer Success Stories
Searchmetrics is a global provider of search data, software, and consulting solutions, helping customers turn search data into unique business insights. To date, Searchmetrics has helped more than 1,000 companies such as McKinsey & Company, Lowe’s, and AXA find an advantage in the hyper-competitive search landscape.
In 2021, Searchmetrics turned to AWS to help with artificial intelligence (AI) usage to further improve their search insights capabilities.
This post outlines how Searchmetrics built an AI solution that increased the efficiency of its human workforce by 20% by automatically finding relevant search keywords for any given topic, using Amazon SageMaker and its native integration with Hugging Face.
In the News : Generating Illustrations from written description
OpenAI have announced DALL·E 2 a successor to the DALL·E system that they announced last year that can create realistic images and art from a description in natural language. DALL·E 2 has learned the relationship between images and the text used to describe them. It uses a process called “diffusion,” which starts with a pattern of random dots and gradually alters that pattern towards an image when it recognizes specific aspects of that image. The images created are consistent with what you would expect, but allow the request to specify the style of a drawing, for example the two images below are of ‘An astronaut riding a horse.’ with one request ending ‘as a pencil drawing’ and the other requesting ‘a photrealistic style’.

Other examples allow for more detailed and subtle requests to be made, for example ‘a raccoon astronaut with the cosmos reflecting on the glass of his helmet dreaming of the stars’ provides an image which seems to convey the emotion requested, but also successfully composes multiple images while retaining proportions.

More detail can be found on the OpenAI blog post announcing DALL·E 2 underlying research paper on Hierarchical Text-Conditional Image Generation with CLIP Latents.
In the News : AI finally gets the joke
As Natural Language Processing continues to evolve it has moved beyond detecting entities, intents or simple sentiments to now being at the point where it can now ‘understand’ and explain a joke:
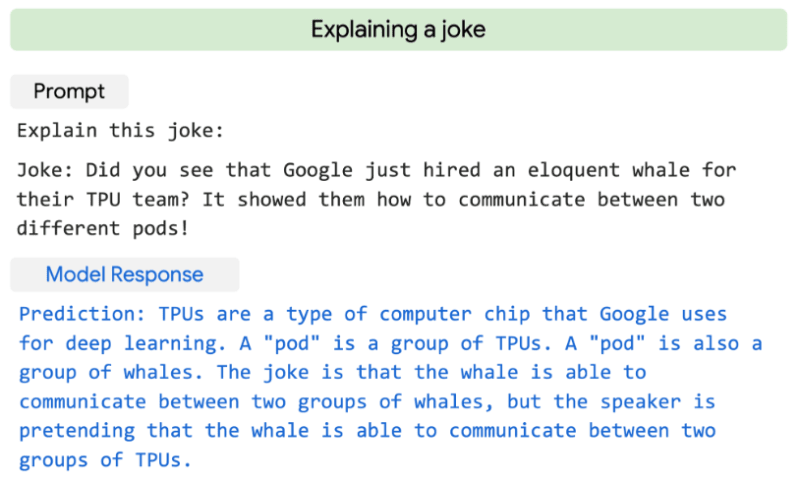
While the jokes are perhaps not the best (the Data Scientists that created them may be better sticking to the day job) the model’s explanation of the joke leads to interesting possibilities. While still very much a research project , the application of this in customer service chatbots could for example yielding better results than taking the comments of a sarcastic customer too literally.
The model itself is built on Google’s Pathways Language Model (PaLM) which has scaled to 540 billion parameters in order to achieve this level of insight.
Read the original source blog post or dive even deeper by reading the PaLM paper.
NLP Posts from the AWS Machine Learning Blog
Build a virtual credit approval agent with Amazon Lex, Amazon Textract, and Amazon Connect
Banking and financial institutions review thousands of credit applications per week, this blog post outlines how financial institutions can quickly and effectively expedite the process, reduce cost, and provide better customer experience with faster decisions using the range of Artificial Intelligence services available from AWS. While the scenario given is from the financial services world, the need to provide documentation and evidence in the form of bank statements, utility bills etc. has applicability to a number of business processes, such as construction permits, job applications or government processes such as passport applications.
This post describes implementing a serverless model using Amazon Connect, Amazon Lex and Amazon Textract, along with other serverless capabilities such as Amazon API Gateway and AWS Lambda to rapidly deploy a functioning solution.

The solution pattern above will be familiar to many who build serverless web applications on AWS, this post brings to life integrating Natural Language Processing and Intelligent Document processing capabilities into such an app.
Build a custom entity recogniser for PDF documents using Amazon Comprehend
Identifying entities is a key part of many intelligent document processing workflows, whether it is to create a labelled set of documents, construct an index or trigger a business process. Amazon Comprehend provides the ability to not only for the generic entities supported by the service such as dates, person or location, but also custom entities related to your data set such as product codes or other business specific entities.
In the past you could only use Amazon Comprehend on plain text documents, so if you wanted to analyse a PDF or Word Document as is often the case you would first convert to plain text. As well as being an additional step, this also meant you lost additional attributes related to position and layout in the document that could be used to drive stronger recognition. Last year Amazon Comprehend support for extracting custom entities from native document formats was announced along with support for annotating training documents using Amazon SageMaker Ground Truth.
This post talks through the process of configuring Amazon SageMaker Ground Truth
to annotate PDF documents directly, to build a custom entity model and use the additional structural context to provide more information to the model to help identify the relevant entities within documents.
Fine-tune and deploy a Wav2Vec2 model for speech recognition with Hugging Face and Amazon SageMaker
Automatic speech recognition (ASR) seems to be everywhere these days, whether voice-controlled assistants such as Alexa or Siri, through to call centre transcriptions, voice translations and more. While many scenarios can be effectively handled utilising pre-build AI services such as Amazon Transcribe, it is always good for any NLP practitioner to have multiple tools at their disposal. One example is the Hugging Face Wav2Vec2 model which uses a Connectionist Temporal Classification (CTC) algorithm, as CTC is a character-based algorithm it has the capability to generate output with the character-by-character sequence of the recording see Sequence Modelling With CTC for a backgrounder.
This blog post describes a deployment of an end-to-end Wav2Vec2 solution on SageMaker, the following diagram provides a high-level view of the solution workflow.
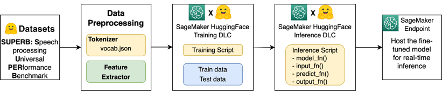
The approach outlined int this post can be utilised to fine tune the Wav2Vec2 model for your own data sets.
Host Hugging Face transformer models using Amazon SageMaker Serverless Inference
This blog post walks through the steps to deploy a Hugging Face model using SageMaker Serverless Inference, which following being announced at re:Invent 2021 went GA last month.
Serverless Inference joins the existing SageMaker deployment models of Real-time inference endpoints, Batch transform and Asynchronous inference, to make it easy for you to deploy and scale ML models.
As well as describing the process of deploying a number of popular Hugging Face models onto Serverless Inference, the post analyses the relative cost compared to a real time endpoint on an ml.t2.medium instance, demonstrating the savings that can be made for models with intermittent or low levels of access.

Identify paraphrased text with Hugging Face on Amazon SageMaker
Identifying paraphrased text, where one piece of text is a summary of another, can have a broad variety of applications in Natural language processing. For example, by identifying sentence paraphrases, a text summarization system could remove redundant information, identify plagiarized documents, or be utilised to identify cross references between multiple documents.
More complex and effective models successfully identify paraphrasing that uses significantly different language, or identify passages that have lexical similarities but opposite meanings for example opposites such as ‘I took a flight from New York to Paris’ vs ‘I took a flight from Paris to New York’.
This blog post walks through setting up such a model, fine tuning a Hugging Face transformer, and executing the model on Amazon SageMaker. It builds a scenario based upon the PAWS dataset (which contains sentence pairs with high lexical overlap), it also demonstrates using the Serverless Inference model in the above post. It would be a great starting point for any data sets you need to process in your own work.





Top comments (0)