The AWS Schema Conversion Tool is designed to make cross-engine database migrations more predictable. It does this by automatically converting not only the source data, but also most of the database objects such as views, stored procedures, and functions. If you think back to the previous section, you may recall that there was no mention of those database objects; the objective was simply to move all of the database tables. And, since that is all our sample database had, that was quite sufficient. However, many “enterprisey” databases will have these database objects. The Schema Conversion Tool will help you with those.
Firstly, the schema conversion tool is a downloadable tool, available for use on Microsoft Windows, Fedora Linux, and Ubuntu Linux. You can access the download links at https://aws.amazon.com/dms/schema-conversion-tool. We will use the Windows version of the tool for our walkthrough. Second, the tool will only migrate relational data into Amazon RDS or Amazon Redshift. Table 1 displays the source and target database combinations supported by the tool.
| Source | Aurora MySQL | Aurora PGSQL | MariaDB | MySQL | PGSQL | SQL Server | Redshift |
|---|---|---|---|---|---|---|---|
| Oracle | X | X | X | X | X | ||
| Oracle Data Warehouse | X | ||||||
| Azure SQL Database | X | X | X | X | |||
| Microsoft SQL Server | X | X | X | X | X | X | X |
| Teradata | X | ||||||
| IBM Netezza | X | ||||||
| Greenplum | X | ||||||
| HPE Vertica | X | ||||||
| MySQL | X | X | X | ||||
| PostgreSQL (PGSQL) | X | X | X | X | |||
| IBM DB2 LUW | X | X | X | X | X | ||
| IBM Db2 for z/OS | X | X | X | X | |||
| SAP ASE | X | X | X | X | X | ||
| Amazon Redshift | X | ||||||
| Azure Synapse Analytics | X | ||||||
| Snowflake | X |
Table 1. Databases available as sources and targets for Schema Conversion Tool
Clicking the download tool link will start the downloading of a zip file. Once the file is downloaded, extract the content to a working directory. There will be a .msi installation file and two folders. Run the installation file and start the application when the installation is completed.
Configuring the Source
Upon your first run of the tool, you will be presented with the terms of use. Accepting these terms will open the application and present the Create a new database migration project screen as shown in Figure 1.
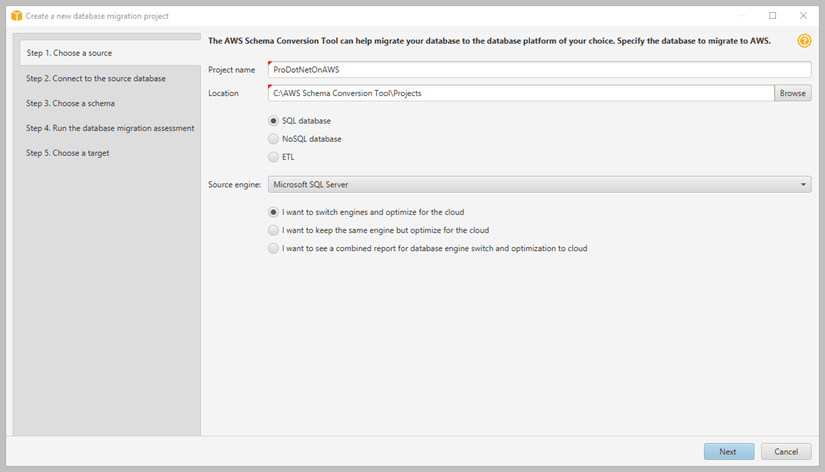 Figure 1. Create a new database migration project screen in SCT
Figure 1. Create a new database migration project screen in SCT
We selected Microsoft SQL Server as our source engine and this enabled the three radio buttons that give some direction as to how the conversion process should proceed. The three choices are:
- I want to switch engines and optimize for the cloud (default)
- I want to keep the same engine but optimize it for the cloud
- I want to see a combined report for database engine switch and optimization to the cloud.
Each of these selections will alter the logic of the migration project, for example, selecting to keep the same engine will provide you with a different set of destinations than selecting to switch engines.
Completing the fields in Step 1 and clicking the Next button will take you to the Step 2 – Connect to the source database screen as shown in Figure 2.
 Figure 2. Specifying connection information for the source database
Figure 2. Specifying connection information for the source database
As shown in Figure 2 there are four fields that have the upper left corner of the field displaying a red tick. Those fields are required for the connection, and three of them are fields that you should be well acquainted with by now, the Server Name, User name, and Password (when accessing the source database using SQL Server Authentication). However, the last field, Microsoft SQL Server driver path, is a new one and points to the directory in which the Microsoft SQL Server JDBC driver is located, which we didn’t have installed. Fortunately, AWS helpfully provides a page with links to the various database drivers at https://docs.aws.amazon.com/SchemaConversionTool/latest/userguide/CHAP_Installing.html. You will need to install drivers for both your source and target databases. We went through and downloaded the drivers for SQL Server (our source database) and the drivers for Amazon Aurora MySQL (our destination database). Once the appropriate JDBC drivers are installed, you can point to the SQL Server driver path as shown in Figure 3.
 Figure 3. Specifying SQL Server JDBC path
Figure 3. Specifying SQL Server JDBC path
Once you have your server, authentication, and driver path filled out you can click the Test connection button to ensure everything works as expected. If that is successful, you can select Next to continue.
Note: Our Microsoft SQL Server JDBC download contained three different .jar files, jre8, jre11, and jre17. The tool would allow the selection of jre8 and jre11 but would not allow the selection of the jre17 file. This will likely change as the tool continues to evolve.
The tool will next display a screen that indicates that it is loading the metadata for the server. This metadata includes databases, schemas, and triggers. Once that loading is completed, you will be in S_tep 3. Choose a schema_ where you will get a list of all databases and the schemas available within each one. This list includes all of the system databases, such as master, model, msdb, and tempdb. You will probably not want to include those! Once you have selected the schema(s), click the Next button. You will see the “Loading metadata” screen again as the tool gets all the database objects based upon your selected schema(s). This process will take a few minutes.
Database Migration Assessment Screen
Once completed, you will be taken to the Step 4. Run the Database migration assessment screen. The first thing that you will see is the assessment report. This report was created by the tool taking all the metadata that it found and analyzing it to see how well it would convert into the various source databases. At the top of the report is the Executive summary. This lists all of the potential target platforms and summarizes the types of actions that need to be taken. An example of this report is shown in Figure 4.
 Figure 4. Executive summary of the migration assessment report
Figure 4. Executive summary of the migration assessment report
Immediately under the executive summary is a textual analysis of the data in the chart. Each of the line items is described with an estimation of the percentage of database storage objects and database code objects that can be automatically converted. In our case, both Amazon RDS for MySQL and Amazon Aurora (MySQL compatible) can be converted at 100%. None of the other target platforms scored that high.
Additional detail is displayed further down the page as shown in Figure 5.
 Figure 5. Details on migrating to Amazon Aurora MySQL
Figure 5. Details on migrating to Amazon Aurora MySQL
This section demonstrates that 1 schema, 10 tables, 17 constraints, 7 procedures and 1 scalar function can be successfully converted to Amazon Aurora (MySQL compatible).
Configuring the Destination
Once you have completed your review of the potential destination, click the Next button. This will bring you to Step 5. Choose a target page where you select the target engine and configure the connection to the target database. When we got to the page Amazon RDS for MySQL was selected as the target engine, so we went with that and created a new Amazon RDS for MySQL instance in the RDS console, making sure that we enabled external access. Filling out the connection information and clicking the Test connection button demonstrated that we had filled the information out appropriately, so we clicked the Finish button.
Completing the Migration
This brings you to the project page as shown in Figure 6.
 Figure 6. Schema conversion tool conversion project
Figure 6. Schema conversion tool conversion project
Just like with DMS, the conversion tool gives you the ability to add mapping and transformation rules. You do this by clicking on the Main view icon in the toolbar and selecting the Mapping view. This changes the center section of the screen. In this section you can add Transformation rules. These transformation rules, just as with DMS, allow you to alter the name of items that are going to be migrated. You can create a rule where you create the appropriate filters to determine which objects will be affected, and you have the following options on how the names will be changed:
- Add prefix
- Add suffix
- Convert lowercase
- Convert uppercase
- Move to
- Remove prefix
- Remove suffix
- Rename
- Replace prefix
- Replace suffix
These different transformations are useful when working with database schemas that user older approaches such as using a prefix of “t” before the name to show that the object is a table, or “v” to indicate that it’s a view. We will not be using any transformations as part of our conversion.
Since we are converting our ProDotNetOnAWS database and its dbo schema, you need to go to the left window where the SQL Server content is displayed, right-click on the dbo schema, and select Convert schema from the popup menu. You will get an additional popup that shows the copying of the schema to the source destination. Once completed, the right window will look like Figure 7 where it shows that the schema has been copied over along with tables, procedures, views, and functions (if you have all of those).
 Figure 7. Schema converted to source database
Figure 7. Schema converted to source database
Note that this has not yet been applied to the destination server and is instead a local representation of what that it would look like once applied. Your next step is to apply the changes to the destination. You do this by right-clicking on the destination schema and selecting Apply to database. This will bring up a pop-up confirmation window after which you will see the schema being processed. The window will close once completed.
At this point, your schema has been transferred to the source database. Figure 8 shows the destination database in MySQL Workbench, and you can see that the schema defined in the tool has been successfully migrated.
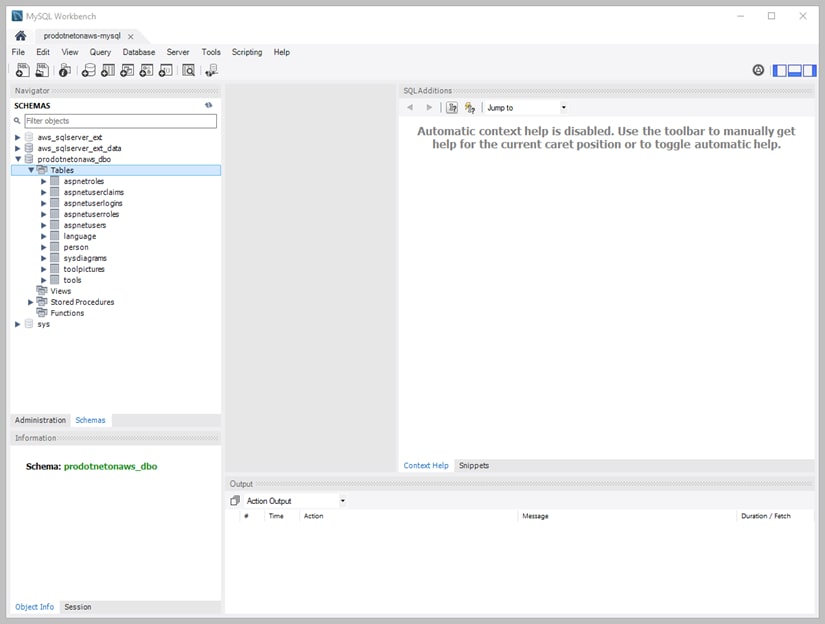 Figure 8. Viewing converted schema in MySQL Workbench
Figure 8. Viewing converted schema in MySQL Workbench
Once your data has been migrated, the last step is to convert your code so that it can access your new database.

Top comments (0)